 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
WeatherProof: Leveraging Language Guidance for Semantic Segmentation in Adverse Weather
Mar 21, 2024
We propose a method to infer semantic segmentation maps from images captured under adverse weather conditions. We begin by examining existing models on images degraded by weather conditions such as rain, fog, or snow, and found that they exhibit a large performance drop as compared to those captured under clear weather. To control for changes in scene structures, we propose WeatherProof, the first semantic segmentation dataset with accurate clear and adverse weather image pairs that share an underlying scene. Through this dataset, we analyze the error modes in existing models and found that they were sensitive to the highly complex combination of different weather effects induced on the image during capture. To improve robustness, we propose a way to use language as guidance by identifying contributions of adverse weather conditions and injecting that as "side information". Models trained using our language guidance exhibit performance gains by up to 10.2% in mIoU on WeatherProof, up to 8.44% in mIoU on the widely used ACDC dataset compared to standard training techniques, and up to 6.21% in mIoU on the ACDC dataset as compared to previous SOTA methods.
Zero-Shot Image Feature Consensus with Deep Functional Maps
Mar 18, 2024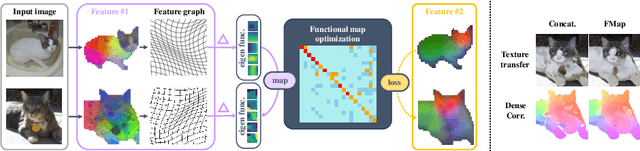
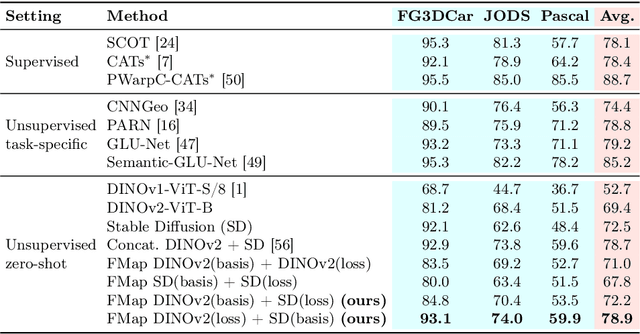
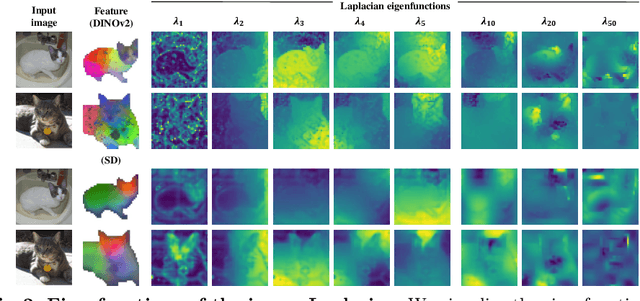
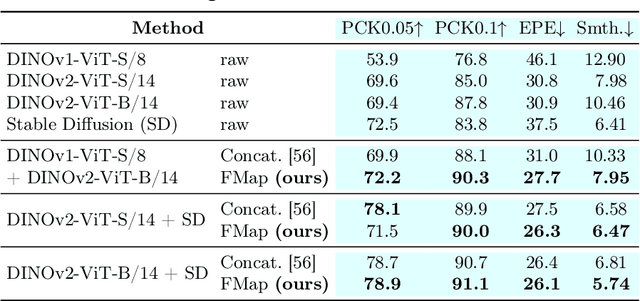
Correspondences emerge from large-scale vision models trained for generative and discriminative tasks. This has been revealed and benchmarked by computing correspondence maps between pairs of images, using nearest neighbors on the feature grids. Existing work has attempted to improve the quality of these correspondence maps by carefully mixing features from different sources, such as by combining the features of different layers or networks. We point out that a better correspondence strategy is available, which directly imposes structure on the correspondence field: the functional map. Wielding this simple mathematical tool, we lift the correspondence problem from the pixel space to the function space and directly optimize for mappings that are globally coherent. We demonstrate that our technique yields correspondences that are not only smoother but also more accurate, with the possibility of better reflecting the knowledge embedded in the large-scale vision models that we are studying. Our approach sets a new state-of-the-art on various dense correspondence tasks. We also demonstrate our effectiveness in keypoint correspondence and affordance map transfer.
Towards Understanding Cross and Self-Attention in Stable Diffusion for Text-Guided Image Editing
Mar 06, 2024
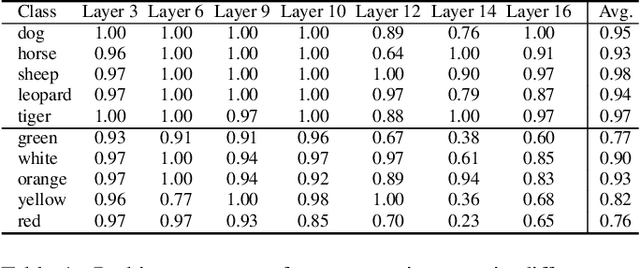
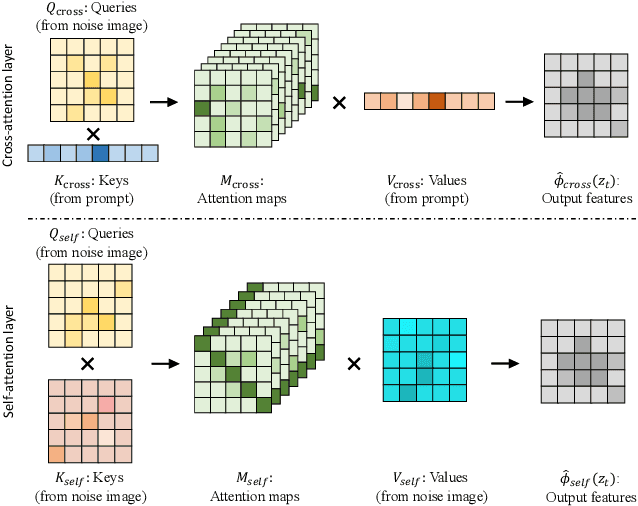
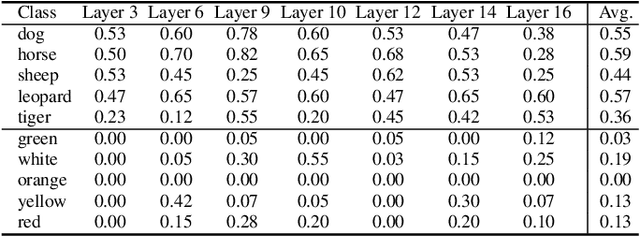
Deep Text-to-Image Synthesis (TIS) models such as Stable Diffusion have recently gained significant popularity for creative Text-to-image generation. Yet, for domain-specific scenarios, tuning-free Text-guided Image Editing (TIE) is of greater importance for application developers, which modify objects or object properties in images by manipulating feature components in attention layers during the generation process. However, little is known about what semantic meanings these attention layers have learned and which parts of the attention maps contribute to the success of image editing. In this paper, we conduct an in-depth probing analysis and demonstrate that cross-attention maps in Stable Diffusion often contain object attribution information that can result in editing failures. In contrast, self-attention maps play a crucial role in preserving the geometric and shape details of the source image during the transformation to the target image. Our analysis offers valuable insights into understanding cross and self-attention maps in diffusion models. Moreover, based on our findings, we simplify popular image editing methods and propose a more straightforward yet more stable and efficient tuning-free procedure that only modifies self-attention maps of the specified attention layers during the denoising process. Experimental results show that our simplified method consistently surpasses the performance of popular approaches on multiple datasets.
Total Disentanglement of Font Images into Style and Character Class Features
Mar 19, 2024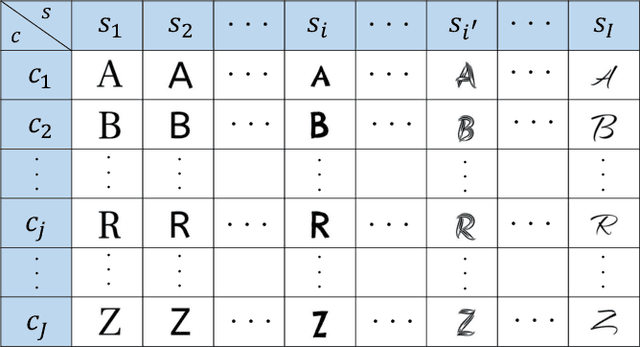
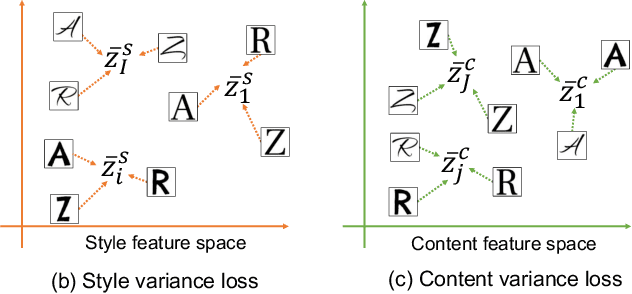
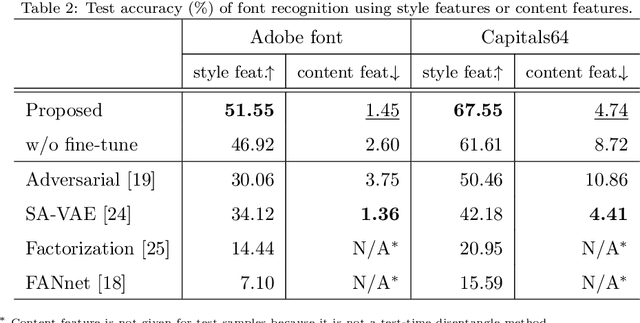
In this paper, we demonstrate a total disentanglement of font images. Total disentanglement is a neural network-based method for decomposing each font image nonlinearly and completely into its style and content (i.e., character class) features. It uses a simple but careful training procedure to extract the common style feature from all `A'-`Z' images in the same font and the common content feature from all `A' (or another class) images in different fonts. These disentangled features guarantee the reconstruction of the original font image. Various experiments have been conducted to understand the performance of total disentanglement. First, it is demonstrated that total disentanglement is achievable with very high accuracy; this is experimental proof of the long-standing open question, ``Does `A'-ness exist?'' Hofstadter (1985). Second, it is demonstrated that the disentangled features produced by total disentanglement apply to a variety of tasks, including font recognition, character recognition, and one-shot font image generation.
PromptCharm: Text-to-Image Generation through Multi-modal Prompting and Refinement
Mar 06, 2024
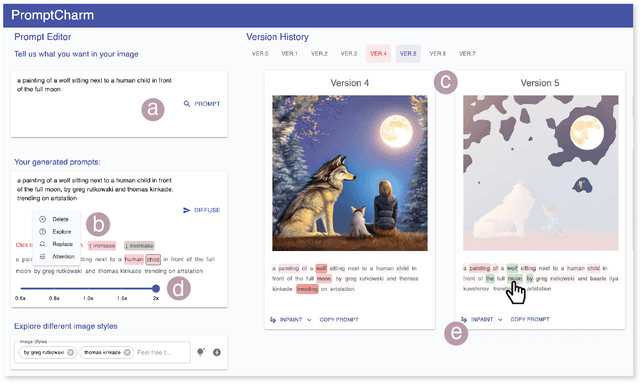

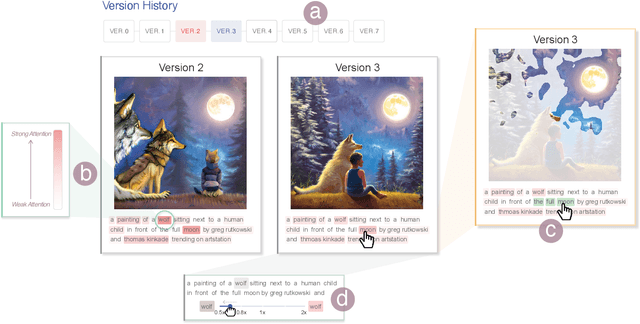
The recent advancements in Generative AI have significantly advanced the field of text-to-image generation. The state-of-the-art text-to-image model, Stable Diffusion, is now capable of synthesizing high-quality images with a strong sense of aesthetics. Crafting text prompts that align with the model's interpretation and the user's intent thus becomes crucial. However, prompting remains challenging for novice users due to the complexity of the stable diffusion model and the non-trivial efforts required for iteratively editing and refining the text prompts. To address these challenges, we propose PromptCharm, a mixed-initiative system that facilitates text-to-image creation through multi-modal prompt engineering and refinement. To assist novice users in prompting, PromptCharm first automatically refines and optimizes the user's initial prompt. Furthermore, PromptCharm supports the user in exploring and selecting different image styles within a large database. To assist users in effectively refining their prompts and images, PromptCharm renders model explanations by visualizing the model's attention values. If the user notices any unsatisfactory areas in the generated images, they can further refine the images through model attention adjustment or image inpainting within the rich feedback loop of PromptCharm. To evaluate the effectiveness and usability of PromptCharm, we conducted a controlled user study with 12 participants and an exploratory user study with another 12 participants. These two studies show that participants using PromptCharm were able to create images with higher quality and better aligned with the user's expectations compared with using two variants of PromptCharm that lacked interaction or visualization support.
An Upload-Efficient Scheme for Transferring Knowledge From a Server-Side Pre-trained Generator to Clients in Heterogeneous Federated Learning
Mar 23, 2024Heterogeneous Federated Learning (HtFL) enables collaborative learning on multiple clients with different model architectures while preserving privacy. Despite recent research progress, knowledge sharing in HtFL is still difficult due to data and model heterogeneity. To tackle this issue, we leverage the knowledge stored in pre-trained generators and propose a new upload-efficient knowledge transfer scheme called Federated Knowledge-Transfer Loop (FedKTL). Our FedKTL can produce client-task-related prototypical image-vector pairs via the generator's inference on the server. With these pairs, each client can transfer pre-existing knowledge from the generator to its local model through an additional supervised local task. We conduct extensive experiments on four datasets under two types of data heterogeneity with 14 kinds of models including CNNs and ViTs. Results show that our upload-efficient FedKTL surpasses seven state-of-the-art methods by up to 7.31% in accuracy. Moreover, our knowledge transfer scheme is applicable in scenarios with only one edge client. Code: https://github.com/TsingZ0/FedKTL
Open-Vocabulary Scene Text Recognition via Pseudo-Image Labeling and Margin Loss
Mar 12, 2024
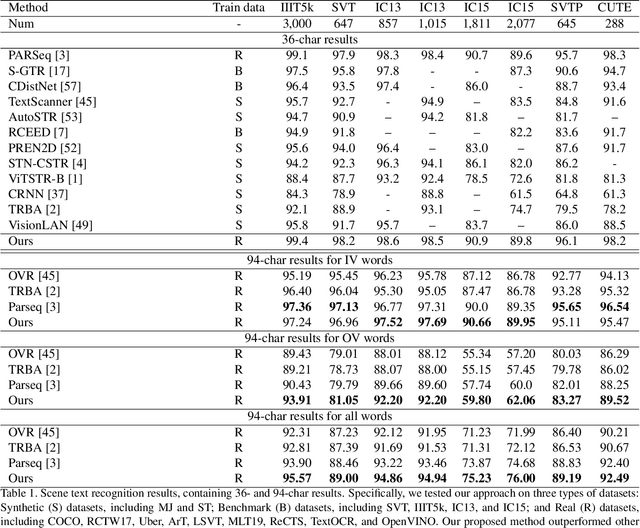
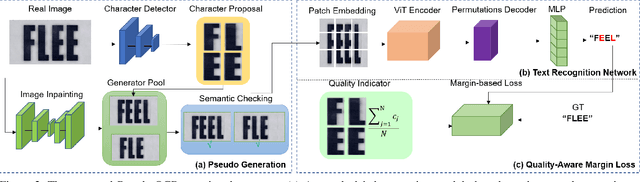
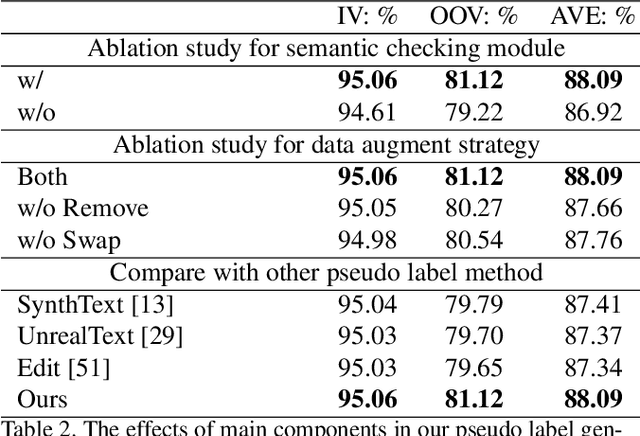
Scene text recognition is an important and challenging task in computer vision. However, most prior works focus on recognizing pre-defined words, while there are various out-of-vocabulary (OOV) words in real-world applications. In this paper, we propose a novel open-vocabulary text recognition framework, Pseudo-OCR, to recognize OOV words. The key challenge in this task is the lack of OOV training data. To solve this problem, we first propose a pseudo label generation module that leverages character detection and image inpainting to produce substantial pseudo OOV training data from real-world images. Unlike previous synthetic data, our pseudo OOV data contains real characters and backgrounds to simulate real-world applications. Secondly, to reduce noises in pseudo data, we present a semantic checking mechanism to filter semantically meaningful data. Thirdly, we introduce a quality-aware margin loss to boost the training with pseudo data. Our loss includes a margin-based part to enhance the classification ability, and a quality-aware part to penalize low-quality samples in both real and pseudo data. Extensive experiments demonstrate that our approach outperforms the state-of-the-art on eight datasets and achieves the first rank in the ICDAR2022 challenge.
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
Mar 05, 2024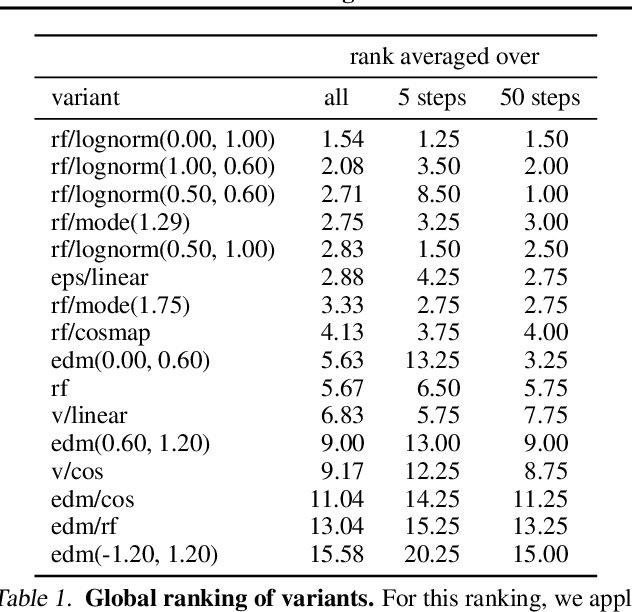
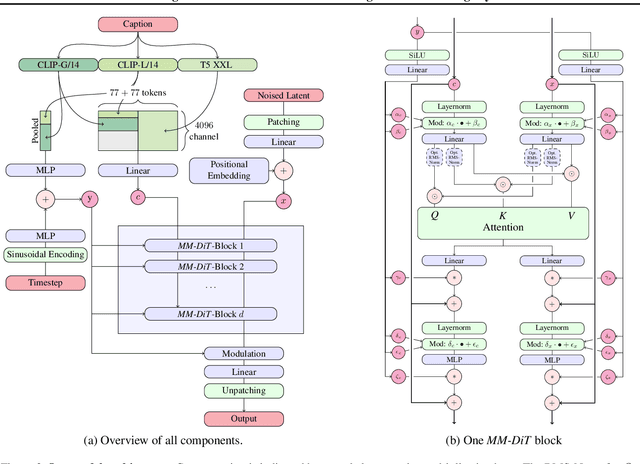
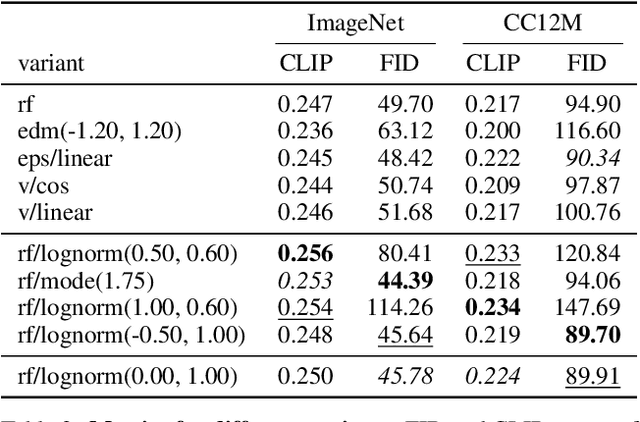
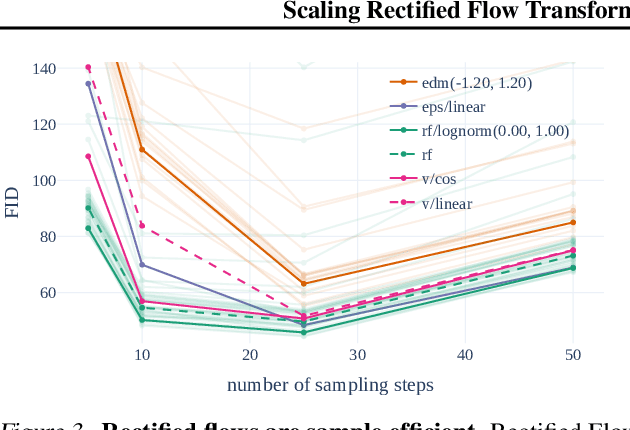
Diffusion models create data from noise by inverting the forward paths of data towards noise and have emerged as a powerful generative modeling technique for high-dimensional, perceptual data such as images and videos. Rectified flow is a recent generative model formulation that connects data and noise in a straight line. Despite its better theoretical properties and conceptual simplicity, it is not yet decisively established as standard practice. In this work, we improve existing noise sampling techniques for training rectified flow models by biasing them towards perceptually relevant scales. Through a large-scale study, we demonstrate the superior performance of this approach compared to established diffusion formulations for high-resolution text-to-image synthesis. Additionally, we present a novel transformer-based architecture for text-to-image generation that uses separate weights for the two modalities and enables a bidirectional flow of information between image and text tokens, improving text comprehension, typography, and human preference ratings. We demonstrate that this architecture follows predictable scaling trends and correlates lower validation loss to improved text-to-image synthesis as measured by various metrics and human evaluations. Our largest models outperform state-of-the-art models, and we will make our experimental data, code, and model weights publicly available.
RAR: Retrieving And Ranking Augmented MLLMs for Visual Recognition
Mar 20, 2024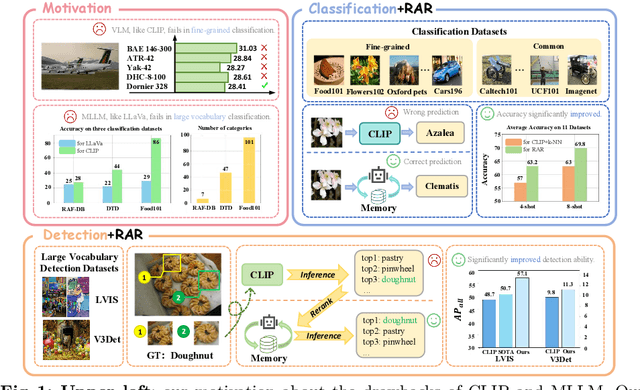
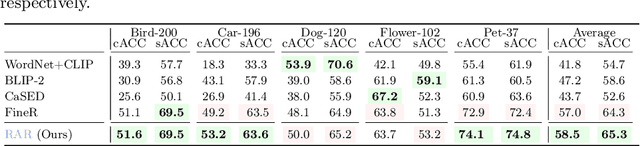
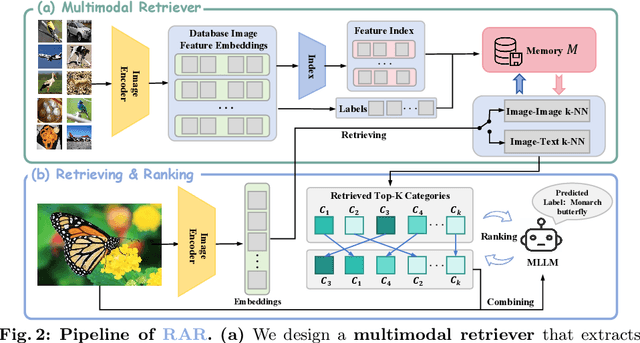
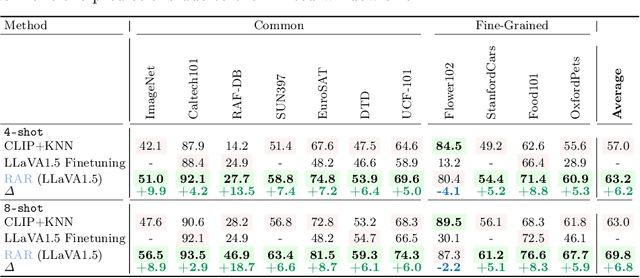
CLIP (Contrastive Language-Image Pre-training) uses contrastive learning from noise image-text pairs to excel at recognizing a wide array of candidates, yet its focus on broad associations hinders the precision in distinguishing subtle differences among fine-grained items. Conversely, Multimodal Large Language Models (MLLMs) excel at classifying fine-grained categories, thanks to their substantial knowledge from pre-training on web-level corpora. However, the performance of MLLMs declines with an increase in category numbers, primarily due to growing complexity and constraints of limited context window size. To synergize the strengths of both approaches and enhance the few-shot/zero-shot recognition abilities for datasets characterized by extensive and fine-grained vocabularies, this paper introduces RAR, a Retrieving And Ranking augmented method for MLLMs. We initially establish a multi-modal retriever based on CLIP to create and store explicit memory for different categories beyond the immediate context window. During inference, RAR retrieves the top-k similar results from the memory and uses MLLMs to rank and make the final predictions. Our proposed approach not only addresses the inherent limitations in fine-grained recognition but also preserves the model's comprehensive knowledge base, significantly boosting accuracy across a range of vision-language recognition tasks. Notably, our approach demonstrates a significant improvement in performance on 5 fine-grained visual recognition benchmarks, 11 few-shot image recognition datasets, and the 2 object detection datasets under the zero-shot recognition setting.
Average Calibration Error: A Differentiable Loss for Improved Reliability in Image Segmentation
Mar 11, 2024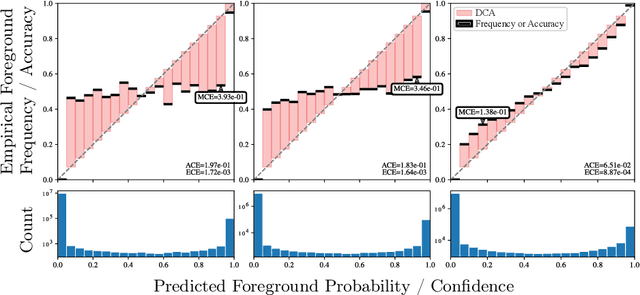
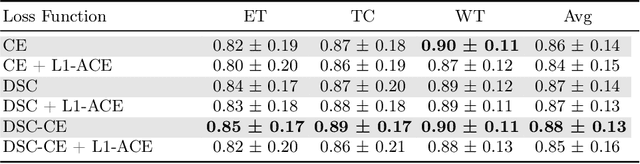
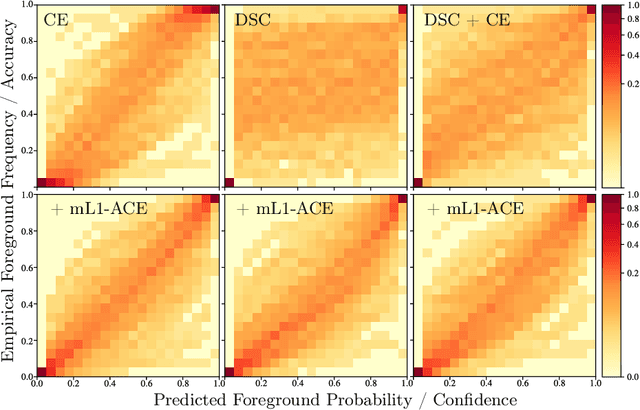
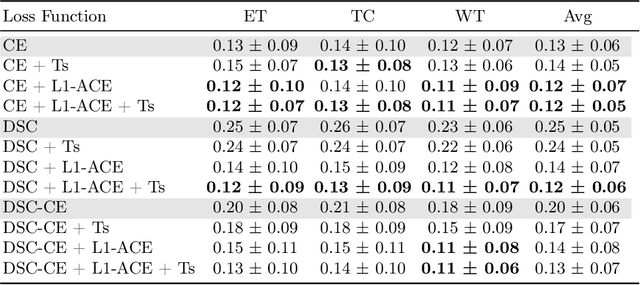
Deep neural networks for medical image segmentation often produce overconfident results misaligned with empirical observations. Such miscalibration, challenges their clinical translation. We propose to use marginal L1 average calibration error (mL1-ACE) as a novel auxiliary loss function to improve pixel-wise calibration without compromising segmentation quality. We show that this loss, despite using hard binning, is directly differentiable, bypassing the need for approximate but differentiable surrogate or soft binning approaches. Our work also introduces the concept of dataset reliability histograms which generalises standard reliability diagrams for refined visual assessment of calibration in semantic segmentation aggregated at the dataset level. Using mL1-ACE, we reduce average and maximum calibration error by 45% and 55% respectively, maintaining a Dice score of 87% on the BraTS 2021 dataset. We share our code here: https://github.com/cai4cai/ACE-DLIRIS