 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Crowd3D: Towards Hundreds of People Reconstruction from a Single Image
Jan 23, 2023
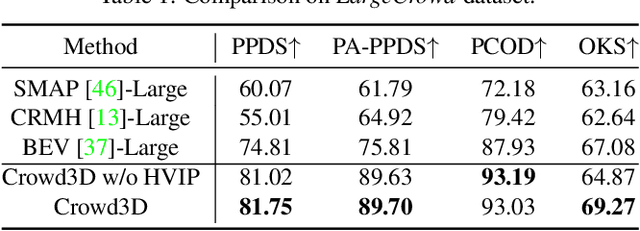
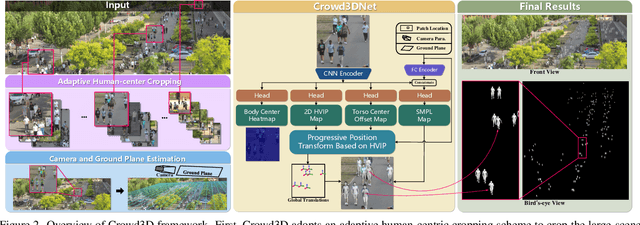
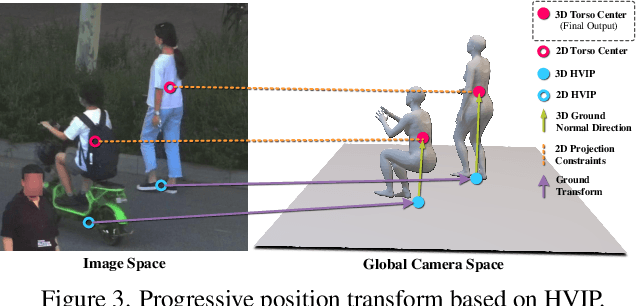
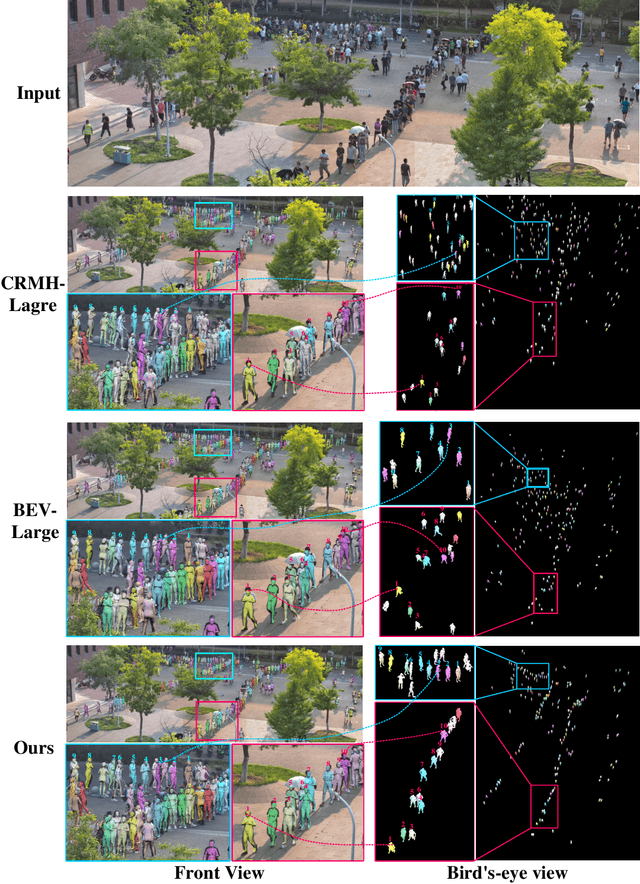
Image-based multi-person reconstruction in wide-field large scenes is critical for crowd analysis and security alert. However, existing methods cannot deal with large scenes containing hundreds of people, which encounter the challenges of large number of people, large variations in human scale, and complex spatial distribution. In this paper, we propose Crowd3D, the first framework to reconstruct the 3D poses, shapes and locations of hundreds of people with global consistency from a single large-scene image. The core of our approach is to convert the problem of complex crowd localization into pixel localization with the help of our newly defined concept, Human-scene Virtual Interaction Point (HVIP). To reconstruct the crowd with global consistency, we propose a progressive reconstruction network based on HVIP by pre-estimating a scene-level camera and a ground plane. To deal with a large number of persons and various human sizes, we also design an adaptive human-centric cropping scheme. Besides, we contribute a benchmark dataset, LargeCrowd, for crowd reconstruction in a large scene. Experimental results demonstrate the effectiveness of the proposed method. The code and datasets will be made public.
A Cross-direction Task Decoupling Network for Small Logo Detection
May 04, 2023
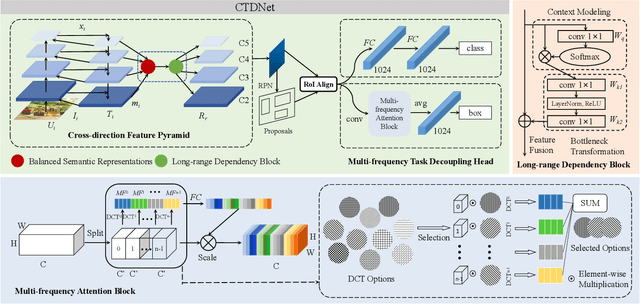


Logo detection plays an integral role in many applications. However, handling small logos is still difficult since they occupy too few pixels in the image, which burdens the extraction of discriminative features. The aggregation of small logos also brings a great challenge to the classification and localization of logos. To solve these problems, we creatively propose Cross-direction Task Decoupling Network (CTDNet) for small logo detection. We first introduce Cross-direction Feature Pyramid (CFP) to realize cross-direction feature fusion by adopting horizontal transmission and vertical transmission. In addition, Multi-frequency Task Decoupling Head (MTDH) decouples the classification and localization tasks into two branches. A multi frequency attention convolution branch is designed to achieve more accurate regression by combining discrete cosine transform and convolution creatively. Comprehensive experiments on four logo datasets demonstrate the effectiveness and efficiency of the proposed method.
Additive Class Distinction Maps using Branched-GANs
May 04, 2023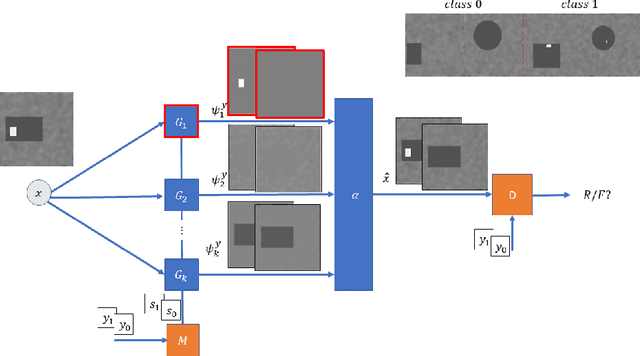
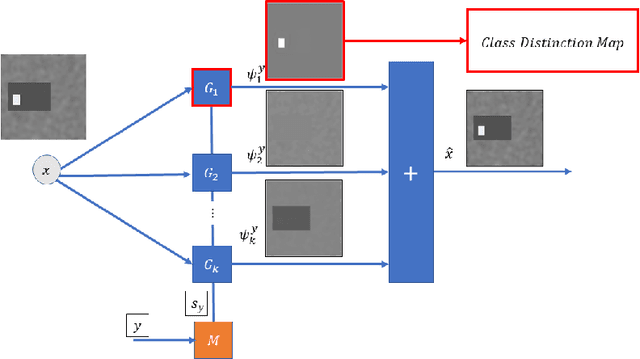


We present a new model, training procedure and architecture to create precise maps of distinction between two classes of images. The objective is to comprehend, in pixel-wise resolution, the unique characteristics of a class. These maps can facilitate self-supervised segmentation and objectdetection in addition to new capabilities in explainable AI (XAI). Our proposed architecture is based on image decomposition, where the output is the sum of multiple generative networks (branched-GANs). The distinction between classes is isolated in a dedicated branch. This approach allows clear, precise and interpretable visualization of the unique characteristics of each class. We show how our generic method can be used in several modalities for various tasks, such as MRI brain tumor extraction, isolating cars in aerial photography and obtaining feminine and masculine face features. This is a preliminary report of our initial findings and results.
Generative Multiplane Neural Radiance for 3D-Aware Image Generation
Apr 03, 2023
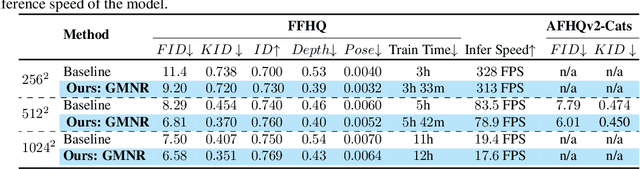


We present a method to efficiently generate 3D-aware high-resolution images that are view-consistent across multiple target views. The proposed multiplane neural radiance model, named GMNR, consists of a novel {\alpha}-guided view-dependent representation ({\alpha}-VdR) module for learning view-dependent information. The {\alpha}-VdR module, faciliated by an {\alpha}-guided pixel sampling technique, computes the view-dependent representation efficiently by learning viewing direction and position coefficients. Moreover, we propose a view-consistency loss to enforce photometric similarity across multiple views. The GMNR model can generate 3D-aware high-resolution images that are viewconsistent across multiple camera poses, while maintaining the computational efficiency in terms of both training and inference time. Experiments on three datasets demonstrate the effectiveness of the proposed modules, leading to favorable results in terms of both generation quality and inference time, compared to existing approaches. Our GMNR model generates 3D-aware images of 1024 X 1024 pixels with 17.6 FPS on a single V100. Code : https://github.com/VIROBO-15/GMNR
Neural Image Compression with a Diffusion-Based Decoder
Jan 23, 2023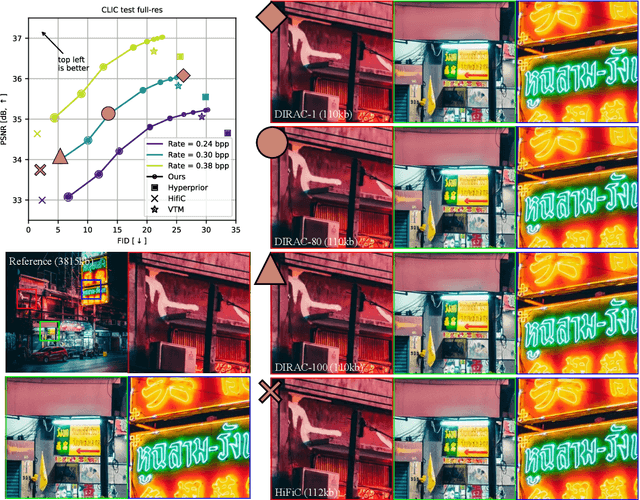
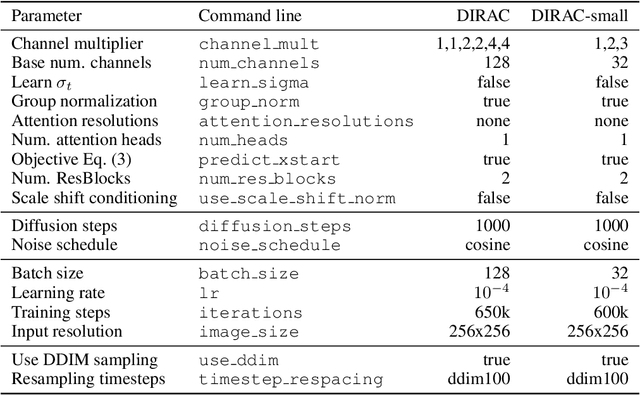
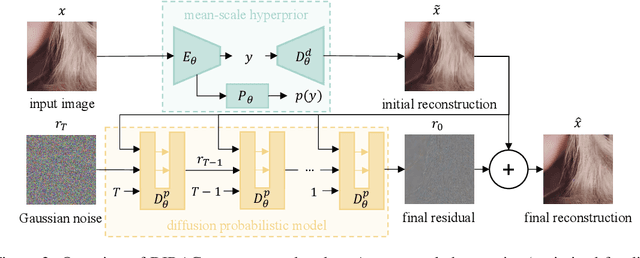
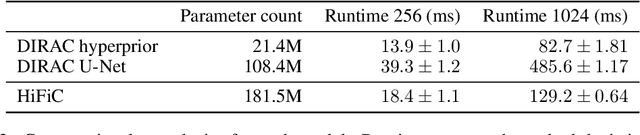
Diffusion probabilistic models have recently achieved remarkable success in generating high quality image and video data. In this work, we build on this class of generative models and introduce a method for lossy compression of high resolution images. The resulting codec, which we call DIffuson-based Residual Augmentation Codec (DIRAC),is the first neural codec to allow smooth traversal of the rate-distortion-perception tradeoff at test time, while obtaining competitive performance with GAN-based methods in perceptual quality. Furthermore, while sampling from diffusion probabilistic models is notoriously expensive, we show that in the compression setting the number of steps can be drastically reduced.
Calibration Assessment and Boldness-Recalibration for Binary Events
May 09, 2023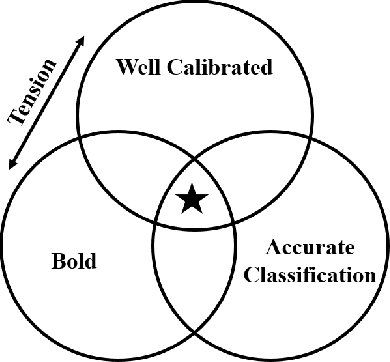
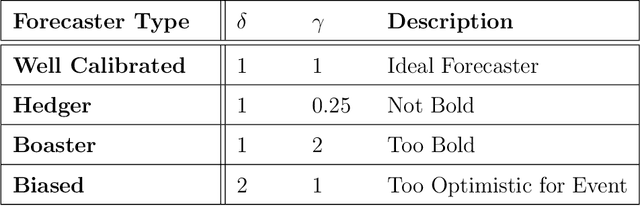
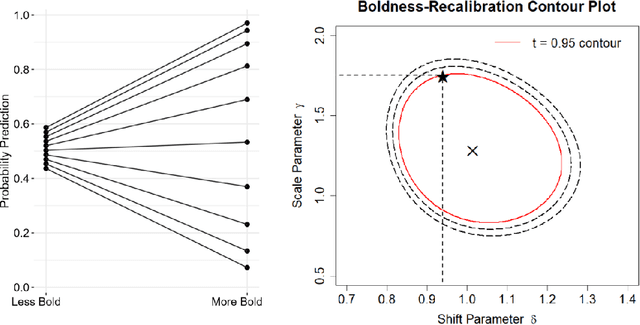

Probability predictions are essential to inform decision making in medicine, economics, image classification, sports analytics, entertainment, and many other fields. Ideally, probability predictions are (i) well calibrated, (ii) accurate, and (iii) bold, i.e., far from the base rate of the event. Predictions that satisfy these three criteria are informative for decision making. However, there is a fundamental tension between calibration and boldness, since calibration metrics can be high when predictions are overly cautious, i.e., non-bold. The purpose of this work is to develop a hypothesis test and Bayesian model selection approach to assess calibration, and a strategy for boldness-recalibration that enables practitioners to responsibly embolden predictions subject to their required level of calibration. Specifically, we allow the user to pre-specify their desired posterior probability of calibration, then maximally embolden predictions subject to this constraint. We verify the performance of our procedures via simulation, then demonstrate the breadth of applicability by applying these methods to real world case studies in each of the fields mentioned above. We find that very slight relaxation of calibration probability (e.g., from 0.99 to 0.95) can often substantially embolden predictions (e.g., widening Hockey predictions' range from .25-.75 to .10-.90)
NLIP: Noise-robust Language-Image Pre-training
Dec 14, 2022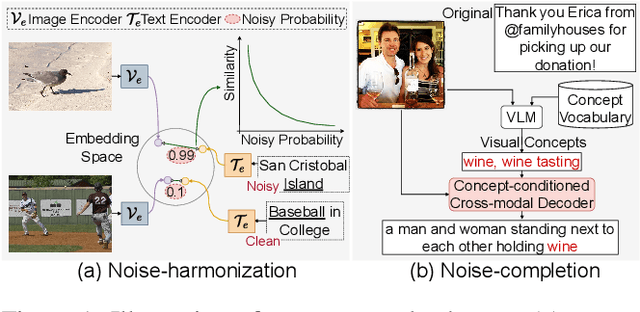
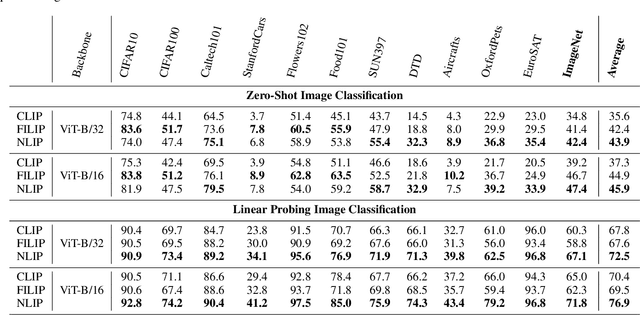
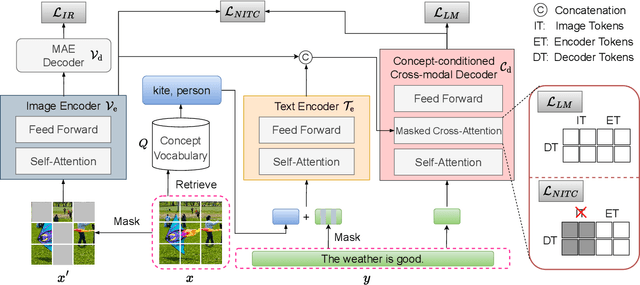
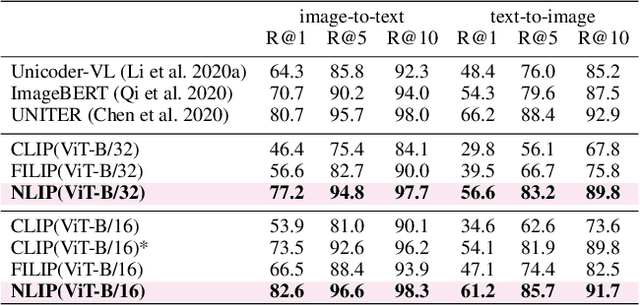
Large-scale cross-modal pre-training paradigms have recently shown ubiquitous success on a wide range of downstream tasks, e.g., zero-shot classification, retrieval and image captioning. However, their successes highly rely on the scale and quality of web-crawled data that naturally contain incomplete and noisy information (e.g., wrong or irrelevant content). Existing works either design manual rules to clean data or generate pseudo-targets as auxiliary signals for reducing noise impact, which do not explicitly tackle both the incorrect and incomplete challenges simultaneously. In this paper, to automatically mitigate the impact of noise by solely mining over existing data, we propose a principled Noise-robust Language-Image Pre-training framework (NLIP) to stabilize pre-training via two schemes: noise-harmonization and noise-completion. First, in noise-harmonization scheme, NLIP estimates the noise probability of each pair according to the memorization effect of cross-modal transformers, then adopts noise-adaptive regularization to harmonize the cross-modal alignments with varying degrees. Second, in noise-completion scheme, to enrich the missing object information of text, NLIP injects a concept-conditioned cross-modal decoder to obtain semantic-consistent synthetic captions to complete noisy ones, which uses the retrieved visual concepts (i.e., objects' names) for the corresponding image to guide captioning generation. By collaboratively optimizing noise-harmonization and noise-completion schemes, our NLIP can alleviate the common noise effects during image-text pre-training in a more efficient way. Extensive experiments show the significant performance improvements of our NLIP using only 26M data over existing pre-trained models (e.g., CLIP, FILIP and BLIP) on 12 zero-shot classification datasets, MSCOCO image captioning and zero-shot image-text retrieval tasks.
Resolution Improvement for OpticalCoherence Tomography based on Sparse Continuous Deconvolution
Apr 10, 2023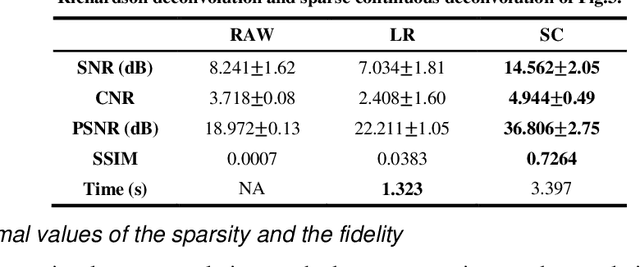
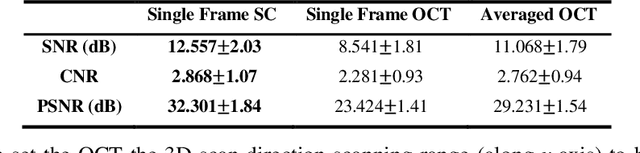
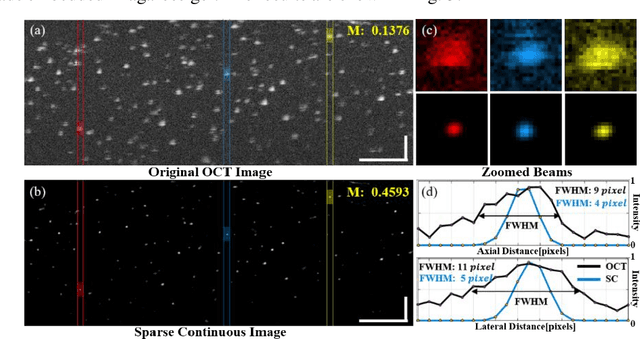
We propose an image resolution improvement method for optical coherence tomography (OCT) based on sparse continuous deconvolution. Traditional deconvolution techniques such as Lucy-Richardson deconvolution suffers from the artifact convergence problem after a small number of iterations, which brings limitation to practical applications. In this work, we take advantage of the prior knowledge about the sample sparsity and continuity to constrain the deconvolution iteration. Sparsity is used to achieve the resolution improvement through the resolution preserving regularization term. And the continuity based on the correlation of the grayscale values in different directions is introduced to mitigate excessive image sparsity and noise reduction through the continuity regularization term. The Bregman splitting technique is then used to solve the resulting optimization problem. Both the numerical simulation study and experimental study on phantoms and biological samples show that our method can suppress artefacts of traditional deconvolution techniques effectively. Meanwhile, clear resolution improvement is demonstrated. It achieved nearly twofold resolution improvement for phantom beads image that can be quantitatively evaluated
Segment Everything Everywhere All at Once
Apr 18, 2023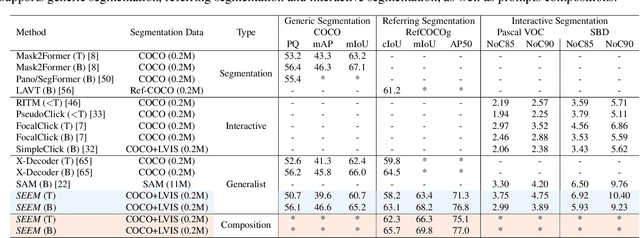
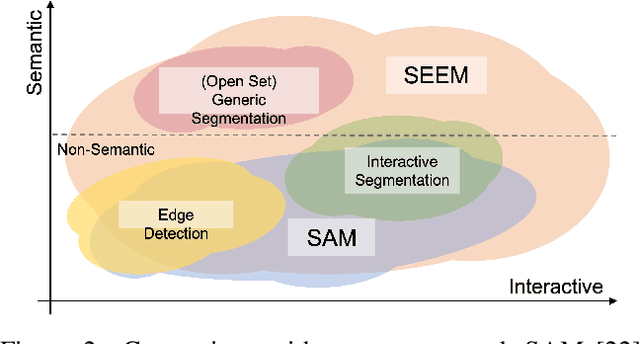
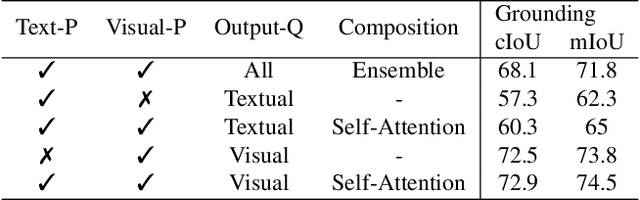
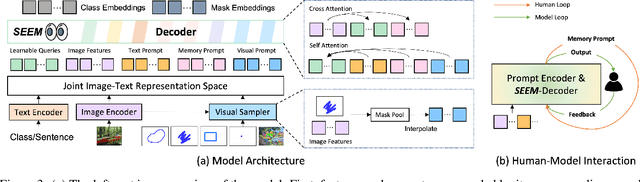
Despite the growing demand for interactive AI systems, there have been few comprehensive studies on human-AI interaction in visual understanding e.g. segmentation. Inspired by the development of prompt-based universal interfaces for LLMs, this paper presents SEEM, a promptable, interactive model for Segmenting Everything Everywhere all at once in an image. SEEM has four desiderata: i) Versatility: by introducing a versatile prompting engine for different types of prompts, including points, boxes, scribbles, masks, texts, and referred regions of another image; ii) Compositionality: by learning a joint visual-semantic space for visual and textual prompts to compose queries on the fly for inference as shown in Fig 1; iii)Interactivity: by incorporating learnable memory prompts to retain dialog history information via mask-guided cross-attention; and iv) Semantic-awareness: by using a text encoder to encode text queries and mask labels for open-vocabulary segmentation.
Seeing Through the Grass: Semantic Pointcloud Filter for Support Surface Learning
May 13, 2023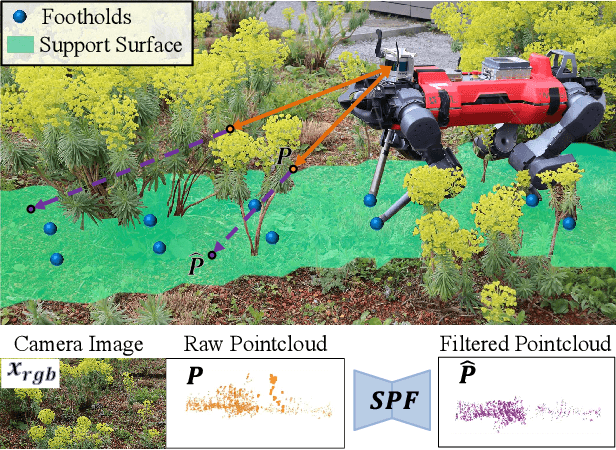
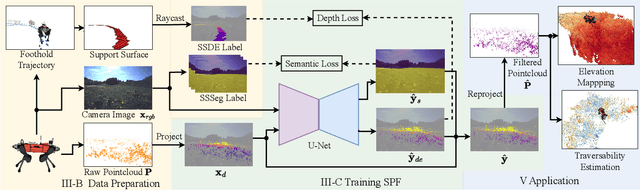
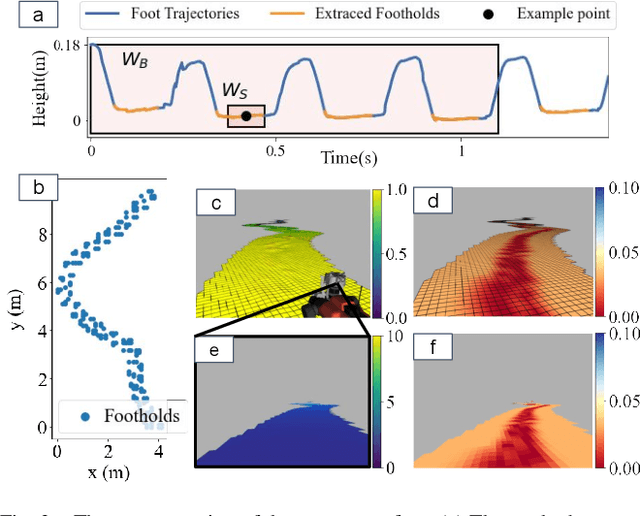

Mobile ground robots require perceiving and understanding their surrounding support surface to move around autonomously and safely. The support surface is commonly estimated based on exteroceptive depth measurements, e.g., from LiDARs. However, the measured depth fails to align with the true support surface in the presence of high grass or other penetrable vegetation. In this work, we present the Semantic Pointcloud Filter (SPF), a Convolutional Neural Network (CNN) that learns to adjust LiDAR measurements to align with the underlying support surface. The SPF is trained in a semi-self-supervised manner and takes as an input a LiDAR pointcloud and RGB image. The network predicts a binary segmentation mask that identifies the specific points requiring adjustment, along with estimating their corresponding depth values. To train the segmentation task, 300 distinct images are manually labeled into rigid and non-rigid terrain. The depth estimation task is trained in a self-supervised manner by utilizing the future footholds of the robot to estimate the support surface based on a Gaussian process. Our method can correctly adjust the support surface prior to interacting with the terrain and is extensively tested on the quadruped robot ANYmal. We show the qualitative benefits of SPF in natural environments for elevation mapping and traversability estimation compared to using raw sensor measurements and existing smoothing methods. Quantitative analysis is performed in various natural environments, and an improvement by 48% RMSE is achieved within a meadow terrain.