 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian Process Assisted Meta-learning for Image Classification and Object Detection Models
Dec 23, 2025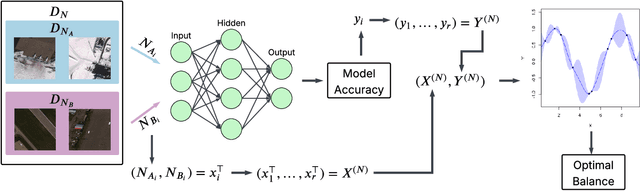

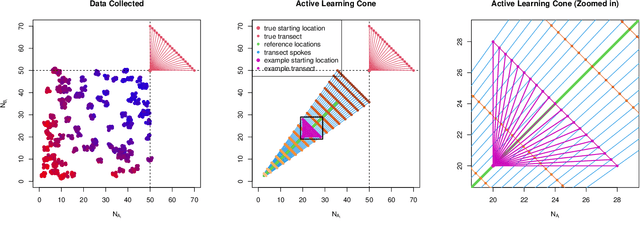
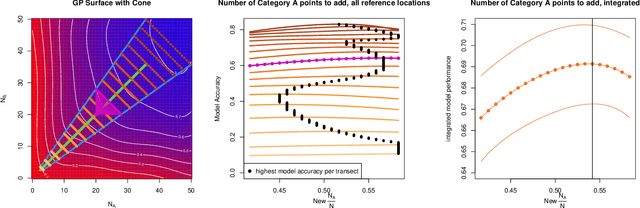
Collecting operationally realistic data to inform machine learning models can be costly. Before collecting new data, it is helpful to understand where a model is deficient. For example, object detectors trained on images of rare objects may not be good at identification in poorly represented conditions. We offer a way of informing subsequent data acquisition to maximize model performance by leveraging the toolkit of computer experiments and metadata describing the circumstances under which the training data was collected (e.g., season, time of day, location). We do this by evaluating the learner as the training data is varied according to its metadata. A Gaussian process (GP) surrogate fit to that response surface can inform new data acquisitions. This meta-learning approach offers improvements to learner performance as compared to data with randomly selected metadata, which we illustrate on both classic learning examples, and on a motivating application involving the collection of aerial images in search of airplanes.
Modular Jump Gaussian Processes
May 21, 2025Gaussian processes (GPs) furnish accurate nonlinear predictions with well-calibrated uncertainty. However, the typical GP setup has a built-in stationarity assumption, making it ill-suited for modeling data from processes with sudden changes, or "jumps" in the output variable. The "jump GP" (JGP) was developed for modeling data from such processes, combining local GPs and latent "level" variables under a joint inferential framework. But joint modeling can be fraught with difficulty. We aim to simplify by suggesting a more modular setup, eschewing joint inference but retaining the main JGP themes: (a) learning optimal neighborhood sizes that locally respect manifolds of discontinuity; and (b) a new cluster-based (latent) feature to capture regions of distinct output levels on both sides of the manifold. We show that each of (a) and (b) separately leads to dramatic improvements when modeling processes with jumps. In tandem (but without requiring joint inference) that benefit is compounded, as illustrated on real and synthetic benchmark examples from the recent literature.
Calibration Assessment and Boldness-Recalibration for Binary Events
May 09, 2023Probability predictions are essential to inform decision making in medicine, economics, image classification, sports analytics, entertainment, and many other fields. Ideally, probability predictions are (i) well calibrated, (ii) accurate, and (iii) bold, i.e., far from the base rate of the event. Predictions that satisfy these three criteria are informative for decision making. However, there is a fundamental tension between calibration and boldness, since calibration metrics can be high when predictions are overly cautious, i.e., non-bold. The purpose of this work is to develop a hypothesis test and Bayesian model selection approach to assess calibration, and a strategy for boldness-recalibration that enables practitioners to responsibly embolden predictions subject to their required level of calibration. Specifically, we allow the user to pre-specify their desired posterior probability of calibration, then maximally embolden predictions subject to this constraint. We verify the performance of our procedures via simulation, then demonstrate the breadth of applicability by applying these methods to real world case studies in each of the fields mentioned above. We find that very slight relaxation of calibration probability (e.g., from 0.99 to 0.95) can often substantially embolden predictions (e.g., widening Hockey predictions' range from .25-.75 to .10-.90)