 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAPS: A Multilingual Benchmark for Global Agent Performance and Security
May 21, 2025Agentic AI systems, which build on Large Language Models (LLMs) and interact with tools and memory, have rapidly advanced in capability and scope. Yet, since LLMs have been shown to struggle in multilingual settings, typically resulting in lower performance and reduced safety, agentic systems risk inheriting these limitations. This raises concerns about the global accessibility of such systems, as users interacting in languages other than English may encounter unreliable or security-critical agent behavior. Despite growing interest in evaluating agentic AI, existing benchmarks focus exclusively on English, leaving multilingual settings unexplored. To address this gap, we propose MAPS, a multilingual benchmark suite designed to evaluate agentic AI systems across diverse languages and tasks. MAPS builds on four widely used agentic benchmarks - GAIA (real-world tasks), SWE-bench (code generation), MATH (mathematical reasoning), and the Agent Security Benchmark (security). We translate each dataset into ten diverse languages, resulting in 805 unique tasks and 8,855 total language-specific instances. Our benchmark suite enables a systematic analysis of how multilingual contexts affect agent performance and robustness. Empirically, we observe consistent degradation in both performance and security when transitioning from English to other languages, with severity varying by task and correlating with the amount of translated input. Building on these findings, we provide actionable recommendations to guide agentic AI systems development and assessment under multilingual settings. This work establishes a standardized evaluation framework, encouraging future research towards equitable, reliable, and globally accessible agentic AI. MAPS benchmark suite is publicly available at https://huggingface.co/datasets/Fujitsu-FRE/MAPS
Identifying Memorization of Diffusion Models through p-Laplace Analysis
May 13, 2025Diffusion models, today's leading image generative models, estimate the score function, i.e. the gradient of the log probability of (perturbed) data samples, without direct access to the underlying probability distribution. This work investigates whether the estimated score function can be leveraged to compute higher-order differentials, namely p-Laplace operators. We show here these operators can be employed to identify memorized training data. We propose a numerical p-Laplace approximation based on the learned score functions, showing its effectiveness in identifying key features of the probability landscape. We analyze the structured case of Gaussian mixture models, and demonstrate the results carry-over to image generative models, where memorization identification based on the p-Laplace operator is performed for the first time.
Manifold Induced Biases for Zero-shot and Few-shot Detection of Generated Images
Apr 21, 2025



Distinguishing between real and AI-generated images, commonly referred to as 'image detection', presents a timely and significant challenge. Despite extensive research in the (semi-)supervised regime, zero-shot and few-shot solutions have only recently emerged as promising alternatives. Their main advantage is in alleviating the ongoing data maintenance, which quickly becomes outdated due to advances in generative technologies. We identify two main gaps: (1) a lack of theoretical grounding for the methods, and (2) significant room for performance improvements in zero-shot and few-shot regimes. Our approach is founded on understanding and quantifying the biases inherent in generated content, where we use these quantities as criteria for characterizing generated images. Specifically, we explore the biases of the implicit probability manifold, captured by a pre-trained diffusion model. Through score-function analysis, we approximate the curvature, gradient, and bias towards points on the probability manifold, establishing criteria for detection in the zero-shot regime. We further extend our contribution to the few-shot setting by employing a mixture-of-experts methodology. Empirical results across 20 generative models demonstrate that our method outperforms current approaches in both zero-shot and few-shot settings. This work advances the theoretical understanding and practical usage of generated content biases through the lens of manifold analysis.
Insights and Current Gaps in Open-Source LLM Vulnerability Scanners: A Comparative Analysis
Oct 21, 2024



This report presents a comparative analysis of open-source vulnerability scanners for conversational large language models (LLMs). As LLMs become integral to various applications, they also present potential attack surfaces, exposed to security risks such as information leakage and jailbreak attacks. Our study evaluates prominent scanners - Garak, Giskard, PyRIT, and CyberSecEval - that adapt red-teaming practices to expose these vulnerabilities. We detail the distinctive features and practical use of these scanners, outline unifying principles of their design and perform quantitative evaluations to compare them. These evaluations uncover significant reliability issues in detecting successful attacks, highlighting a fundamental gap for future development. Additionally, we contribute a preliminary labelled dataset, which serves as an initial step to bridge this gap. Based on the above, we provide strategic recommendations to assist organizations choose the most suitable scanner for their red-teaming needs, accounting for customizability, test suite comprehensiveness, and industry-specific use cases.
Enhancing Neural Training via a Correlated Dynamics Model
Dec 20, 2023



As neural networks grow in scale, their training becomes both computationally demanding and rich in dynamics. Amidst the flourishing interest in these training dynamics, we present a novel observation: Parameters during training exhibit intrinsic correlations over time. Capitalizing on this, we introduce Correlation Mode Decomposition (CMD). This algorithm clusters the parameter space into groups, termed modes, that display synchronized behavior across epochs. This enables CMD to efficiently represent the training dynamics of complex networks, like ResNets and Transformers, using only a few modes. Moreover, test set generalization is enhanced. We introduce an efficient CMD variant, designed to run concurrently with training. Our experiments indicate that CMD surpasses the state-of-the-art method for compactly modeled dynamics on image classification. Our modeling can improve training efficiency and lower communication overhead, as shown by our preliminary experiments in the context of federated learning.
Additive Class Distinction Maps using Branched-GANs
May 04, 2023



We present a new model, training procedure and architecture to create precise maps of distinction between two classes of images. The objective is to comprehend, in pixel-wise resolution, the unique characteristics of a class. These maps can facilitate self-supervised segmentation and objectdetection in addition to new capabilities in explainable AI (XAI). Our proposed architecture is based on image decomposition, where the output is the sum of multiple generative networks (branched-GANs). The distinction between classes is isolated in a dedicated branch. This approach allows clear, precise and interpretable visualization of the unique characteristics of each class. We show how our generic method can be used in several modalities for various tasks, such as MRI brain tumor extraction, isolating cars in aerial photography and obtaining feminine and masculine face features. This is a preliminary report of our initial findings and results.
Analysis of Branch Specialization and its Application in Image Decomposition
Jun 12, 2022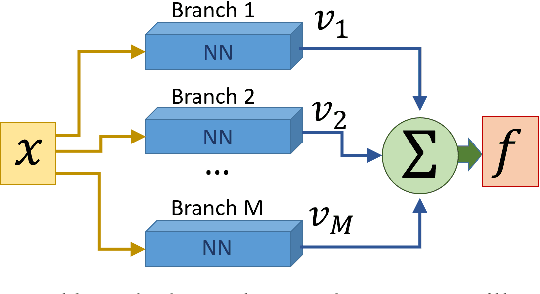
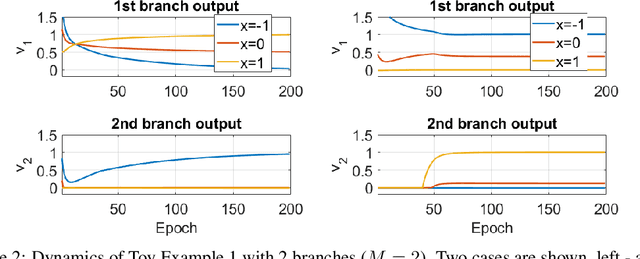
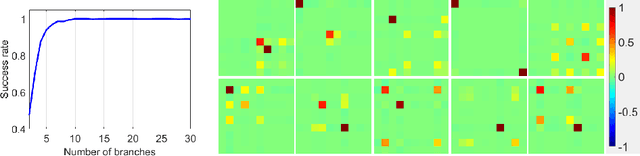
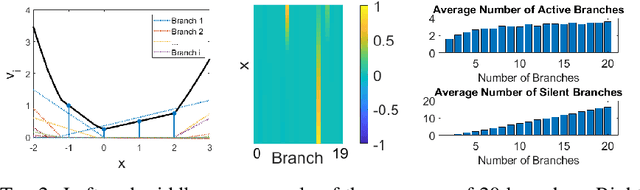
Branched neural networks have been used extensively for a variety of tasks. Branches are sub-parts of the model that perform independent processing followed by aggregation. It is known that this setting induces a phenomenon called Branch Specialization, where different branches become experts in different sub-tasks. Such observations were qualitative by nature. In this work, we present a methodological analysis of Branch Specialization. We explain the role of gradient descent in this phenomenon. We show that branched generative networks naturally decompose animal images to meaningful channels of fur, whiskers and spots and face images to channels such as different illumination components and face parts.