 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning-augmented robotic automation for real-world manufacturing
Apr 24, 2026Industrial robots are widely used in manufacturing, yet most manipulation still depends on fixed waypoint scripts that are brittle to environmental changes. Learning-based control offers a more adaptive alternative, but it remains unclear whether such methods, still mostly confined to laboratory demonstrations, can sustain hours of reliable operation, deliver consistent quality, and behave safely around people on a live production line. Here we present Learning-Augmented Robotic Automation, a hybrid system that integrates learned task controllers and a neural 3D safety monitor into conventional industrial workflows. We deployed the system on an electric-motor production line to automate deformable cable insertion and soldering under real manufacturing constraints, a step previously performed manually by human workers. With less than 20 min of real-world data per task, the system operated continuously for 5 h 10 min, producing 108 motors without physical fencing and achieving a 99.4% pass rate on product-level quality-control tests. It maintained near-human takt time while reducing variability in solder-joint quality and cycle time. These results establish a practical pathway for extending industrial automation with learning-based methods.
A Kinematic Analysis of Palm Degrees of Freedom for Enhancing Thumb Opposability in Robotic Hands
Apr 24, 2026This study investigates the kinematic role of palm degrees of freedom (DoF) in enhancing thumb opposability in a five-finger robotic hand. A hand model consisting of a five DoF thumb and four fingers with three to four DoF is analyzed, where palm motion is introduced between adjacent fingers. To quantitatively evaluate thumb-finger interaction, the overlap workspace volume is defined based on voxelized fingertip reachable regions. Seven cases are considered, including configurations with increased total DoF and configurations in which the total DoF is maintained by redistributing DoF from the fingers to the palm. The results show that palm DoF significantly improves opposability, particularly for the ring and little fingers, by repositioning their base locations rather than simply extending their reachable range. However, when the total DoF is constrained, redistributing DoF to the palm leads to trade-offs between overlap workspace expansion and kinematic redundancy. These findings indicate that palm DoF and finger DoF play distinct roles in hand kinematics and should be considered jointly in design. This study provides a quantitative framework for evaluating palm-induced opposability without relying on object or contact models and offers practical design guidelines for incorporating palm motion in robotic hands.
A Kinematic Framework for Evaluating Pinch Configurations in Robotic Hand Design without Object or Contact Models
Apr 22, 2026Evaluating the pinch capability of a robotic hand is important for understanding its functional dexterity. However, many existing grasp evaluation methods rely on object geometry or contact force models, which limits their applicability during the early stages of robotic hand design. This study proposes a kinematic evaluation method for analyzing pinch configurations of robotic hands based on interactions between fingertip workspaces. First, the reachable workspace of each fingertip is computed from the joint configurations of the fingers. Then, feasible pinch configurations are detected by evaluating the relationships between fingertip pairs. Since the proposed method does not require information about object geometry or contact force models, the pinch capability of a robotic hand can be evaluated solely based on its kinematic structure. In addition, analyses are performed on four different kinematic structures of the hand to investigate their impact on the pinch configurations. The proposed evaluation framework can serve as a useful tool for comparing different robotic hand designs and analyzing pinch capability during the design stage.
Kinematic Optimization of Phalanx Length Ratios in Robotic Hands Using Potential Dexterity
Apr 22, 2026In the design stage of robotic hands, it is not straightforward to quantitatively evaluate the effect of phalanx length ratios on dexterity without defining specific objects or manipulation tasks. Therefore, this study presents a framework for optimizing the phalanx length ratios of a five-finger robotic hand based on potential dexterity within a kinematic structure. The proposed method employs global manipulability, workspace volume, overlap workspace volume, and fingertip sensitivity as evaluation metrics, and identifies optimal design configurations using a weighted objective function under given constraints. The reachable workspace is discretized using a voxel-based representation, and joint motions are discretized at uniform intervals for evaluation. The optimization is performed over design sets for both the thumb and the other fingers, and design combinations that do not generate overlap workspace are excluded. The results show that each phalanx does not contribute equally to the overall dexterity, and the factors influencing each phalanx are identified. In addition, it is observed that the selection of weighting coefficients does not necessarily lead to the direct maximization of individual performance metrics, due to the non-uniform distribution of evaluation measures within the design space. The proposed framework provides a systematic approach to analyze the trade-offs among reachability, dexterity, and controllability, and can serve as a practical guideline for the kinematic design of multi-fingered robotic hands.
KPIs 2024 Challenge: Advancing Glomerular Segmentation from Patch- to Slide-Level
Feb 11, 2025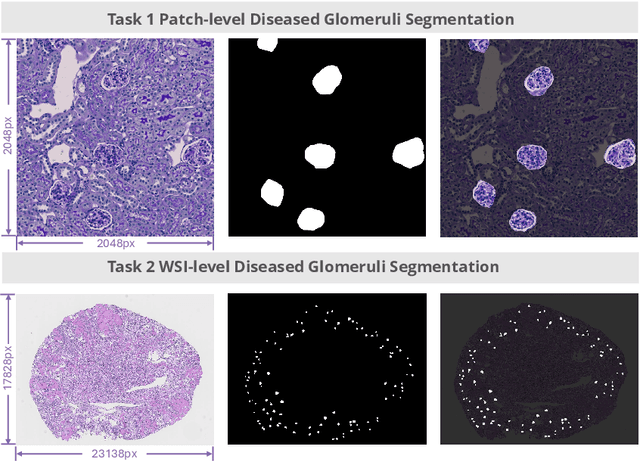

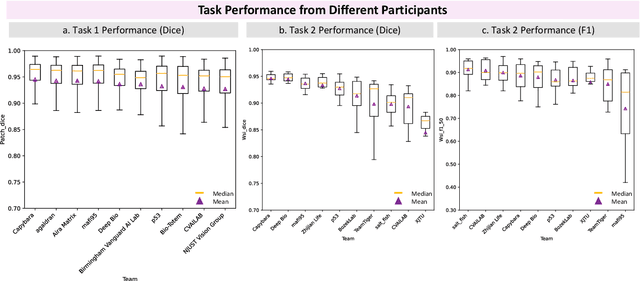

Chronic kidney disease (CKD) is a major global health issue, affecting over 10% of the population and causing significant mortality. While kidney biopsy remains the gold standard for CKD diagnosis and treatment, the lack of comprehensive benchmarks for kidney pathology segmentation hinders progress in the field. To address this, we organized the Kidney Pathology Image Segmentation (KPIs) Challenge, introducing a dataset that incorporates preclinical rodent models of CKD with over 10,000 annotated glomeruli from 60+ Periodic Acid Schiff (PAS)-stained whole slide images. The challenge includes two tasks, patch-level segmentation and whole slide image segmentation and detection, evaluated using the Dice Similarity Coefficient (DSC) and F1-score. By encouraging innovative segmentation methods that adapt to diverse CKD models and tissue conditions, the KPIs Challenge aims to advance kidney pathology analysis, establish new benchmarks, and enable precise, large-scale quantification for disease research and diagnosis.
Predicting the risk of early-stage breast cancer recurrence using H\&E-stained tissue images
Jun 10, 2024



Accurate prediction of the likelihood of recurrence is important in the selection of postoperative treatment for patients with early-stage breast cancer. In this study, we investigated whether deep learning algorithms can predict patients' risk of recurrence by analyzing the pathology images of their cancer histology. A total of 125 hematoxylin and eosin stained breast cancer whole slide images labeled with the risk prediction via genomics assays were used, and we obtained sensitivity of 0.857, 0.746, and 0.529 for predicting low, intermediate, and high risk, and specificity of 0.816, 0.803, and 0.972. When compared to the expert pathologist's regional histology grade information, a Pearson's correlation coefficient of 0.61 was obtained. When we checked the model learned through these studies through the class activation map, we found that it actually considered tubule formation and mitotic rate when predicting different risk groups.
Learning-based legged locomotion; state of the art and future perspectives
Jun 03, 2024Legged locomotion holds the premise of universal mobility, a critical capability for many real-world robotic applications. Both model-based and learning-based approaches have advanced the field of legged locomotion in the past three decades. In recent years, however, a number of factors have dramatically accelerated progress in learning-based methods, including the rise of deep learning, rapid progress in simulating robotic systems, and the availability of high-performance and affordable hardware. This article aims to give a brief history of the field, to summarize recent efforts in learning locomotion skills for quadrupeds, and to provide researchers new to the area with an understanding of the key issues involved. With the recent proliferation of humanoid robots, we further outline the rapid rise of analogous methods for bipedal locomotion. We conclude with a discussion of open problems as well as related societal impact.
Rethinking Robustness Assessment: Adversarial Attacks on Learning-based Quadrupedal Locomotion Controllers
May 21, 2024



Legged locomotion has recently achieved remarkable success with the progress of machine learning techniques, especially deep reinforcement learning (RL). Controllers employing neural networks have demonstrated empirical and qualitative robustness against real-world uncertainties, including sensor noise and external perturbations. However, formally investigating the vulnerabilities of these locomotion controllers remains a challenge. This difficulty arises from the requirement to pinpoint vulnerabilities across a long-tailed distribution within a high-dimensional, temporally sequential space. As a first step towards quantitative verification, we propose a computational method that leverages sequential adversarial attacks to identify weaknesses in learned locomotion controllers. Our research demonstrates that, even state-of-the-art robust controllers can fail significantly under well-designed, low-magnitude adversarial sequence. Through experiments in simulation and on the real robot, we validate our approach's effectiveness, and we illustrate how the results it generates can be used to robustify the original policy and offer valuable insights into the safety of these black-box policies.
Learning Robust Autonomous Navigation and Locomotion for Wheeled-Legged Robots
May 03, 2024Autonomous wheeled-legged robots have the potential to transform logistics systems, improving operational efficiency and adaptability in urban environments. Navigating urban environments, however, poses unique challenges for robots, necessitating innovative solutions for locomotion and navigation. These challenges include the need for adaptive locomotion across varied terrains and the ability to navigate efficiently around complex dynamic obstacles. This work introduces a fully integrated system comprising adaptive locomotion control, mobility-aware local navigation planning, and large-scale path planning within the city. Using model-free reinforcement learning (RL) techniques and privileged learning, we develop a versatile locomotion controller. This controller achieves efficient and robust locomotion over various rough terrains, facilitated by smooth transitions between walking and driving modes. It is tightly integrated with a learned navigation controller through a hierarchical RL framework, enabling effective navigation through challenging terrain and various obstacles at high speed. Our controllers are integrated into a large-scale urban navigation system and validated by autonomous, kilometer-scale navigation missions conducted in Zurich, Switzerland, and Seville, Spain. These missions demonstrate the system's robustness and adaptability, underscoring the importance of integrated control systems in achieving seamless navigation in complex environments. Our findings support the feasibility of wheeled-legged robots and hierarchical RL for autonomous navigation, with implications for last-mile delivery and beyond.
Learning to walk in confined spaces using 3D representation
Feb 29, 2024



Legged robots have the potential to traverse complex terrain and access confined spaces beyond the reach of traditional platforms thanks to their ability to carefully select footholds and flexibly adapt their body posture while walking. However, robust deployment in real-world applications is still an open challenge. In this paper, we present a method for legged locomotion control using reinforcement learning and 3D volumetric representations to enable robust and versatile locomotion in confined and unstructured environments. By employing a two-layer hierarchical policy structure, we exploit the capabilities of a highly robust low-level policy to follow 6D commands and a high-level policy to enable three-dimensional spatial awareness for navigating under overhanging obstacles. Our study includes the development of a procedural terrain generator to create diverse training environments. We present a series of experimental evaluations in both simulation and real-world settings, demonstrating the effectiveness of our approach in controlling a quadruped robot in confined, rough terrain. By achieving this, our work extends the applicability of legged robots to a broader range of scenarios.