 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Dynamic Data Augmentation via MCTS for Prostate MRI Segmentation
May 25, 2023
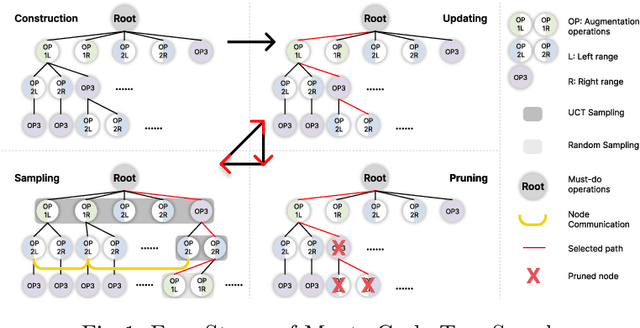
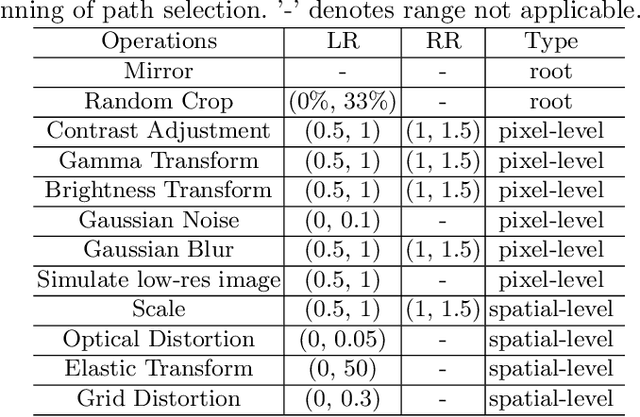
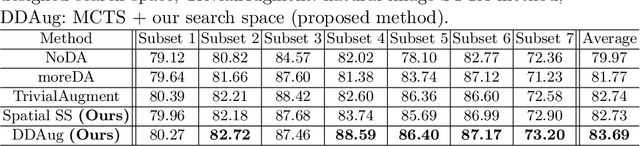
Medical image data are often limited due to the expensive acquisition and annotation process. Hence, training a deep-learning model with only raw data can easily lead to overfitting. One solution to this problem is to augment the raw data with various transformations, improving the model's ability to generalize to new data. However, manually configuring a generic augmentation combination and parameters for different datasets is non-trivial due to inconsistent acquisition approaches and data distributions. Therefore, automatic data augmentation is proposed to learn favorable augmentation strategies for different datasets while incurring large GPU overhead. To this end, we present a novel method, called Dynamic Data Augmentation (DDAug), which is efficient and has negligible computation cost. Our DDAug develops a hierarchical tree structure to represent various augmentations and utilizes an efficient Monte-Carlo tree searching algorithm to update, prune, and sample the tree. As a result, the augmentation pipeline can be optimized for each dataset automatically. Experiments on multiple Prostate MRI datasets show that our method outperforms the current state-of-the-art data augmentation strategies.
DiffCLIP: Leveraging Stable Diffusion for Language Grounded 3D Classification
May 25, 2023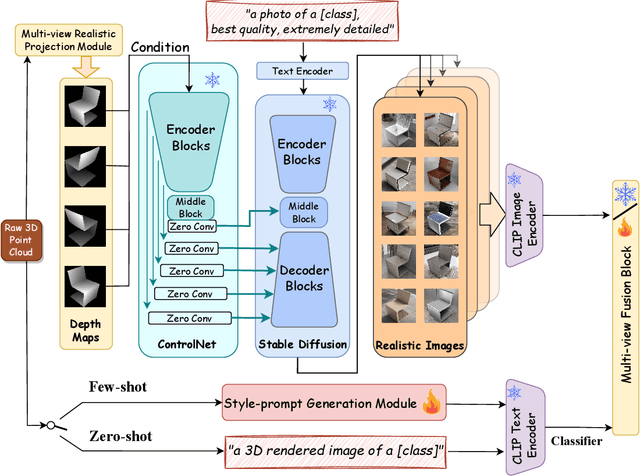
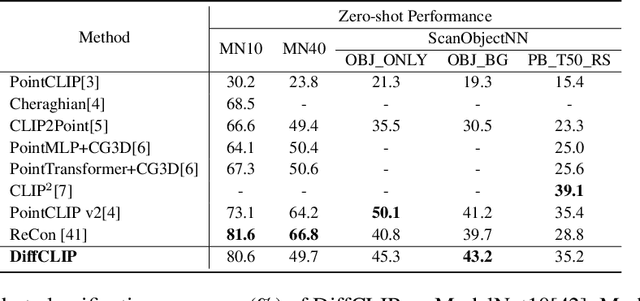


Large pre-trained models have had a significant impact on computer vision by enabling multi-modal learning, where the CLIP model has achieved impressive results in image classification, object detection, and semantic segmentation. However, the model's performance on 3D point cloud processing tasks is limited due to the domain gap between depth maps from 3D projection and training images of CLIP. This paper proposes DiffCLIP, a new pre-training framework that incorporates stable diffusion with ControlNet to minimize the domain gap in the visual branch. Additionally, a style-prompt generation module is introduced for few-shot tasks in the textual branch. Extensive experiments on the ModelNet10, ModelNet40, and ScanObjectNN datasets show that DiffCLIP has strong abilities for 3D understanding. By using stable diffusion and style-prompt generation, DiffCLIP achieves an accuracy of 43.2\% for zero-shot classification on OBJ\_BG of ScanObjectNN, which is state-of-the-art performance, and an accuracy of 80.6\% for zero-shot classification on ModelNet10, which is comparable to state-of-the-art performance.
Sharpness-Aware Minimization Leads to Low-Rank Features
May 25, 2023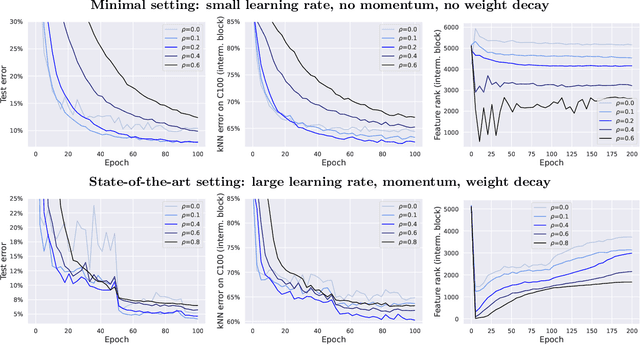
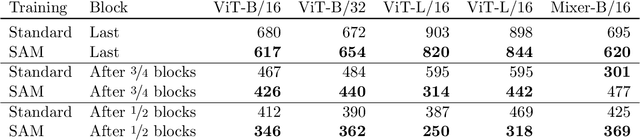
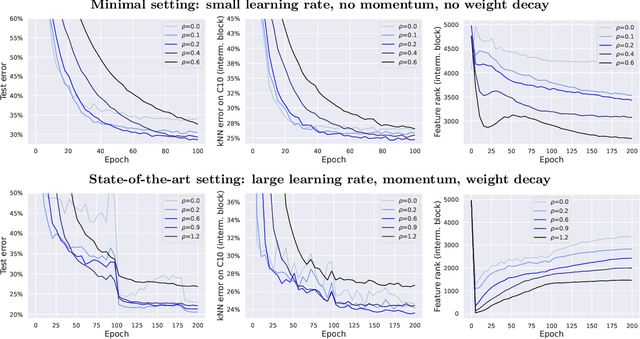
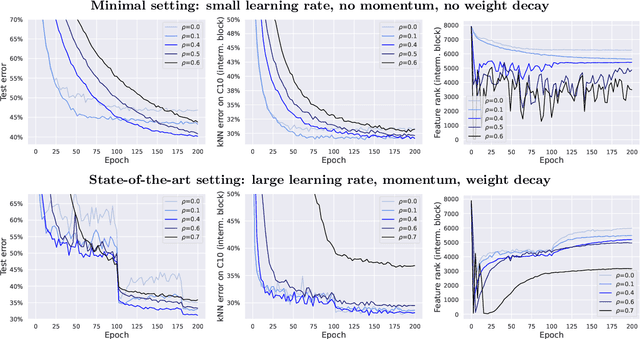
Sharpness-aware minimization (SAM) is a recently proposed method that minimizes the sharpness of the training loss of a neural network. While its generalization improvement is well-known and is the primary motivation, we uncover an additional intriguing effect of SAM: reduction of the feature rank which happens at different layers of a neural network. We show that this low-rank effect occurs very broadly: for different architectures such as fully-connected networks, convolutional networks, vision transformers and for different objectives such as regression, classification, language-image contrastive training. To better understand this phenomenon, we provide a mechanistic understanding of how low-rank features arise in a simple two-layer network. We observe that a significant number of activations gets entirely pruned by SAM which directly contributes to the rank reduction. We confirm this effect theoretically and check that it can also occur in deep networks, although the overall rank reduction mechanism can be more complex, especially for deep networks with pre-activation skip connections and self-attention layers. We make our code available at https://github.com/tml-epfl/sam-low-rank-features.
Learning Better Contrastive View from Radiologist's Gaze
May 15, 2023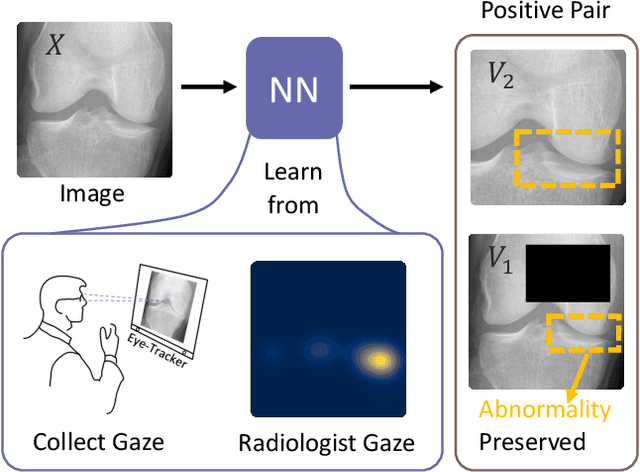
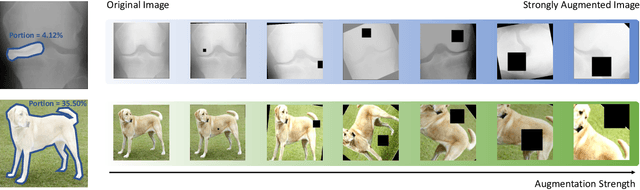
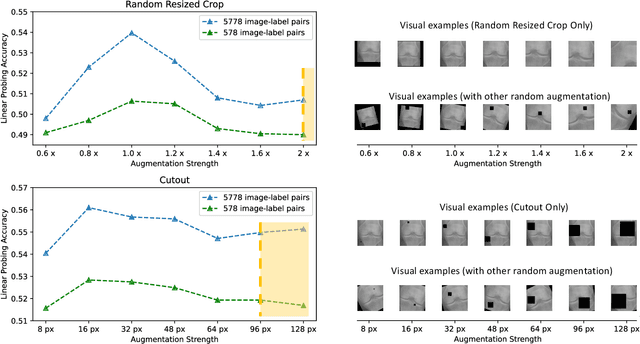
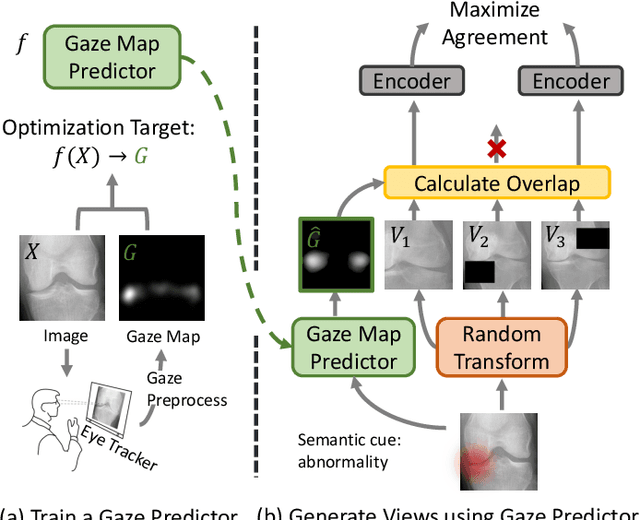
Recent self-supervised contrastive learning methods greatly benefit from the Siamese structure that aims to minimizing distances between positive pairs. These methods usually apply random data augmentation to input images, expecting the augmented views of the same images to be similar and positively paired. However, random augmentation may overlook image semantic information and degrade the quality of augmented views in contrastive learning. This issue becomes more challenging in medical images since the abnormalities related to diseases can be tiny, and are easy to be corrupted (e.g., being cropped out) in the current scheme of random augmentation. In this work, we first demonstrate that, for widely-used X-ray images, the conventional augmentation prevalent in contrastive pre-training can affect the performance of the downstream diagnosis or classification tasks. Then, we propose a novel augmentation method, i.e., FocusContrast, to learn from radiologists' gaze in diagnosis and generate contrastive views for medical images with guidance from radiologists' visual attention. Specifically, we track the gaze movement of radiologists and model their visual attention when reading to diagnose X-ray images. The learned model can predict visual attention of the radiologists given a new input image, and further guide the attention-aware augmentation that hardly neglects the disease-related abnormalities. As a plug-and-play and framework-agnostic module, FocusContrast consistently improves state-of-the-art contrastive learning methods of SimCLR, MoCo, and BYOL by 4.0~7.0% in classification accuracy on a knee X-ray dataset.
Internal Diverse Image Completion
Dec 18, 2022
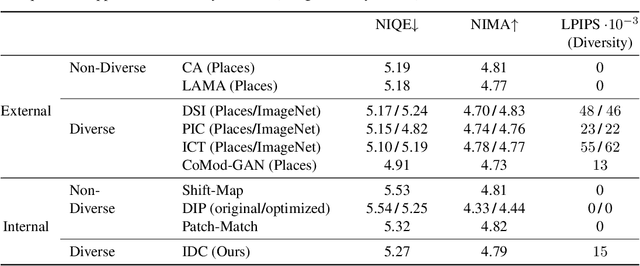
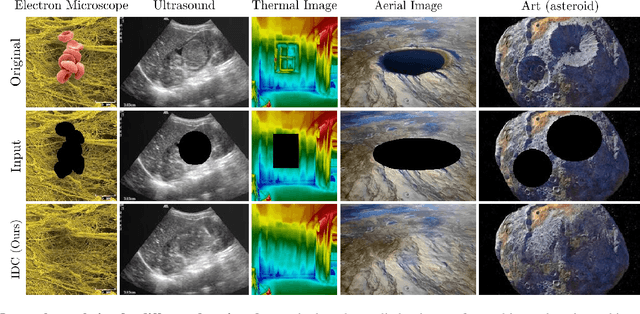
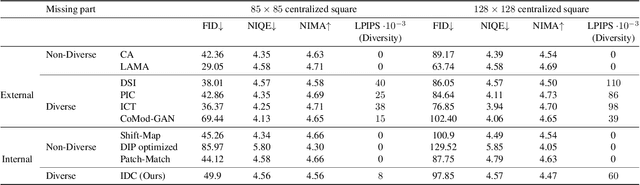
Image completion is widely used in photo restoration and editing applications, e.g. for object removal. Recently, there has been a surge of research on generating diverse completions for missing regions. However, existing methods require large training sets from a specific domain of interest, and often fail on general-content images. In this paper, we propose a diverse completion method that does not require a training set and can thus treat arbitrary images from any domain. Our internal diverse completion (IDC) approach draws inspiration from recent single-image generative models that are trained on multiple scales of a single image, adapting them to the extreme setting in which only a small portion of the image is available for training. We illustrate the strength of IDC on several datasets, using both user studies and quantitative comparisons.
Learning Thin-Plate Spline Motion and Seamless Composition for Parallax-Tolerant Unsupervised Deep Image Stitching
Feb 16, 2023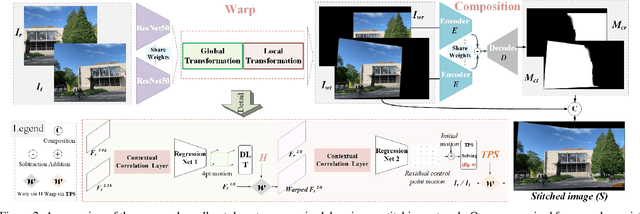
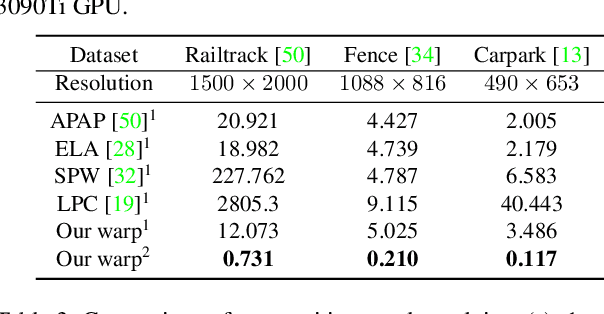

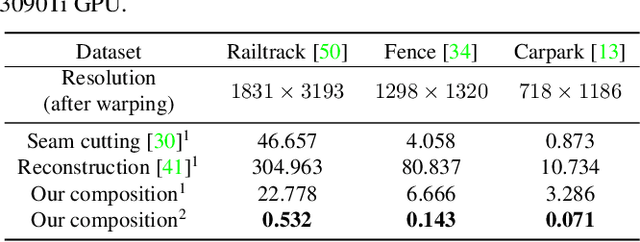
Traditional image stitching approaches tend to leverage increasingly complex geometric features (point, line, edge, etc.) for better performance. However, these hand-crafted features are only suitable for specific natural scenes with adequate geometric structures. In contrast, deep stitching schemes overcome the adverse conditions by adaptively learning robust semantic features, but they cannot handle large-parallax cases due to homography-based registration. To solve these issues, we propose UDIS++, a parallax-tolerant unsupervised deep image stitching technique. First, we propose a robust and flexible warp to model the image registration from global homography to local thin-plate spline motion. It provides accurate alignment for overlapping regions and shape preservation for non-overlapping regions by joint optimization concerning alignment and distortion. Subsequently, to improve the generalization capability, we design a simple but effective iterative strategy to enhance the warp adaption in cross-dataset and cross-resolution applications. Finally, to further eliminate the parallax artifacts, we propose to composite the stitched image seamlessly by unsupervised learning for seam-driven composition masks. Compared with existing methods, our solution is parallax-tolerant and free from laborious designs of complicated geometric features for specific scenes. Extensive experiments show our superiority over the SoTA methods, both quantitatively and qualitatively. The code will be available at https://github.com/nie-lang/UDIS2.
Self-Supervised Image Representation Learning: Transcending Masking with Paired Image Overlay
Jan 23, 2023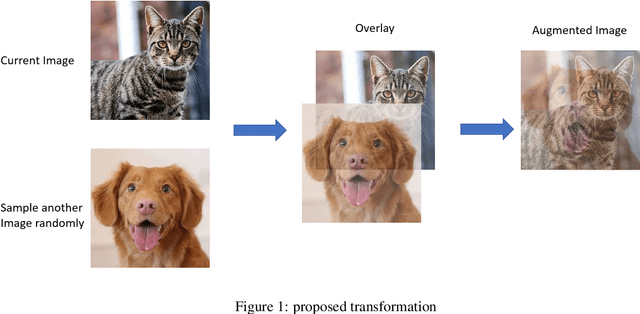
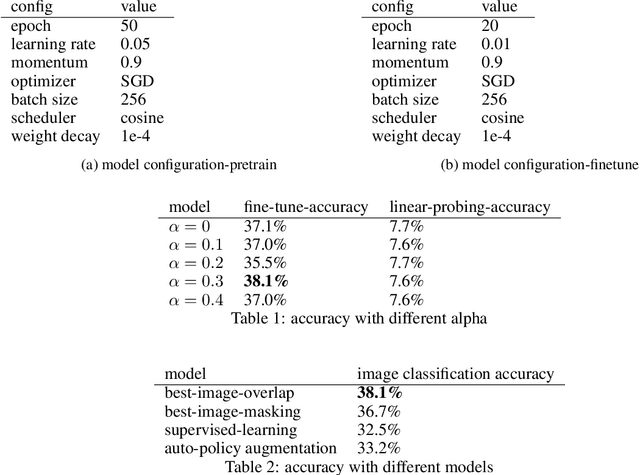


Self-supervised learning has become a popular approach in recent years for its ability to learn meaningful representations without the need for data annotation. This paper proposes a novel image augmentation technique, overlaying images, which has not been widely applied in self-supervised learning. This method is designed to provide better guidance for the model to understand underlying information, resulting in more useful representations. The proposed method is evaluated using contrastive learning, a widely used self-supervised learning method that has shown solid performance in downstream tasks. The results demonstrate the effectiveness of the proposed augmentation technique in improving the performance of self-supervised models.
Explicit Visual Prompting for Universal Foreground Segmentations
May 29, 2023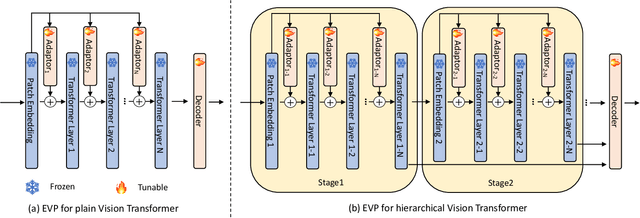
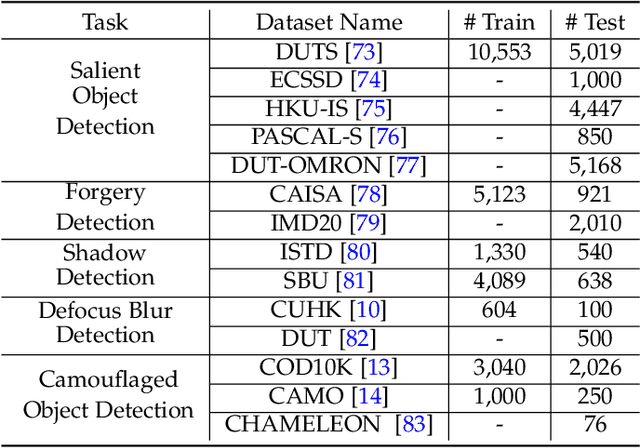
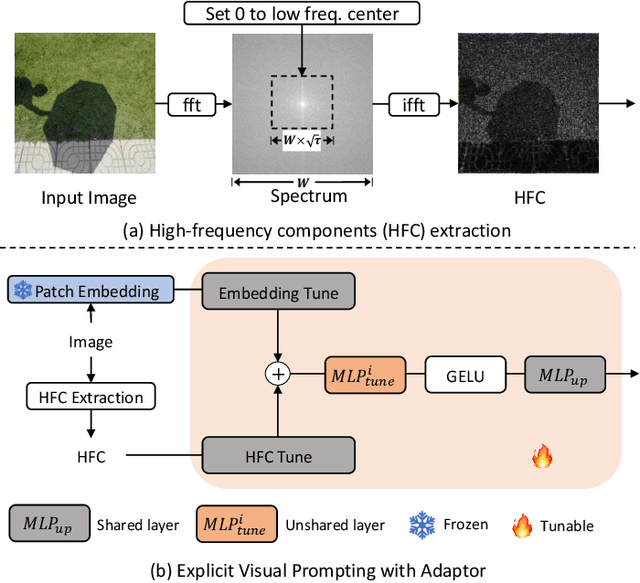
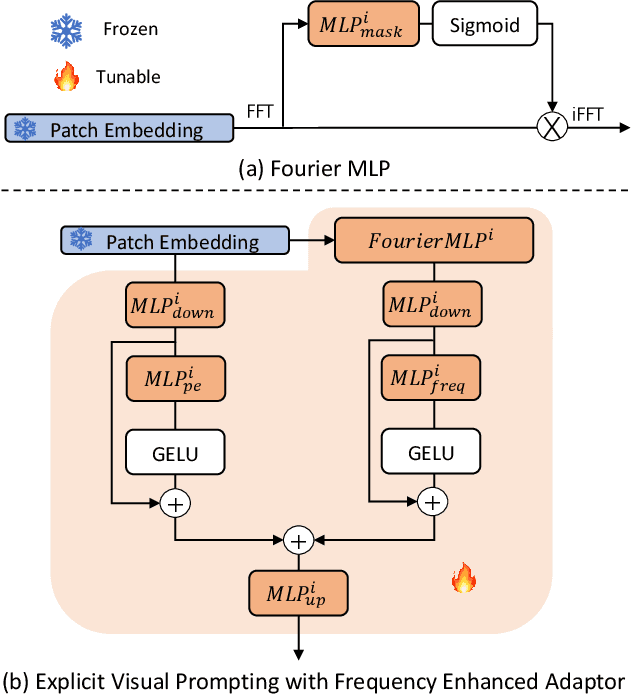
Foreground segmentation is a fundamental problem in computer vision, which includes salient object detection, forgery detection, defocus blur detection, shadow detection, and camouflage object detection. Previous works have typically relied on domain-specific solutions to address accuracy and robustness issues in those applications. In this paper, we present a unified framework for a number of foreground segmentation tasks without any task-specific designs. We take inspiration from the widely-used pre-training and then prompt tuning protocols in NLP and propose a new visual prompting model, named Explicit Visual Prompting (EVP). Different from the previous visual prompting which is typically a dataset-level implicit embedding, our key insight is to enforce the tunable parameters focusing on the explicit visual content from each individual image, i.e., the features from frozen patch embeddings and high-frequency components. Our method freezes a pre-trained model and then learns task-specific knowledge using a few extra parameters. Despite introducing only a small number of tunable parameters, EVP achieves superior performance than full fine-tuning and other parameter-efficient fine-tuning methods. Experiments in fourteen datasets across five tasks show the proposed method outperforms other task-specific methods while being considerably simple. The proposed method demonstrates the scalability in different architectures, pre-trained weights, and tasks. The code is available at: https://github.com/NiFangBaAGe/Explicit-Visual-Prompt.
Multi-Modal Face Stylization with a Generative Prior
May 29, 2023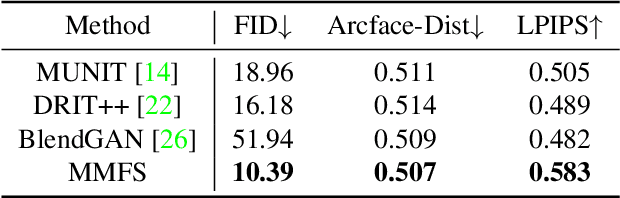
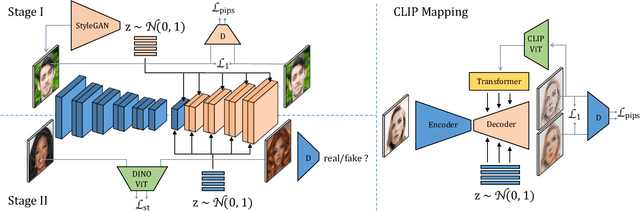


In this work, we introduce a new approach for artistic face stylization. Despite existing methods achieving impressive results in this task, there is still room for improvement in generating high-quality stylized faces with diverse styles and accurate facial reconstruction. Our proposed framework, MMFS, supports multi-modal face stylization by leveraging the strengths of StyleGAN and integrates it into an encoder-decoder architecture. Specifically, we use the mid-resolution and high-resolution layers of StyleGAN as the decoder to generate high-quality faces, while aligning its low-resolution layer with the encoder to extract and preserve input facial details. We also introduce a two-stage training strategy, where we train the encoder in the first stage to align the feature maps with StyleGAN and enable a faithful reconstruction of input faces. In the second stage, the entire network is fine-tuned with artistic data for stylized face generation. To enable the fine-tuned model to be applied in zero-shot and one-shot stylization tasks, we train an additional mapping network from the large-scale Contrastive-Language-Image-Pre-training (CLIP) space to a latent $w+$ space of fine-tuned StyleGAN. Qualitative and quantitative experiments show that our framework achieves superior face stylization performance in both one-shot and zero-shot stylization tasks, outperforming state-of-the-art methods by a large margin.
ChatCAD: Interactive Computer-Aided Diagnosis on Medical Image using Large Language Models
Feb 14, 2023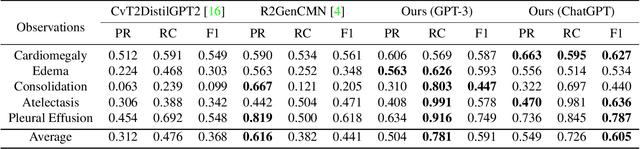



Large language models (LLMs) have recently demonstrated their potential in clinical applications, providing valuable medical knowledge and advice. For example, a large dialog LLM like ChatGPT has successfully passed part of the US medical licensing exam. However, LLMs currently have difficulty processing images, making it challenging to interpret information from medical images, which are rich in information that supports clinical decisions. On the other hand, computer-aided diagnosis (CAD) networks for medical images have seen significant success in the medical field by using advanced deep-learning algorithms to support clinical decision-making. This paper presents a method for integrating LLMs into medical-image CAD networks. The proposed framework uses LLMs to enhance the output of multiple CAD networks, such as diagnosis networks, lesion segmentation networks, and report generation networks, by summarizing and reorganizing the information presented in natural language text format. The goal is to merge the strengths of LLMs' medical domain knowledge and logical reasoning with the vision understanding capability of existing medical-image CAD models to create a more user-friendly and understandable system for patients compared to conventional CAD systems. In the future, LLM's medical knowledge can be also used to improve the performance of vision-based medical-image CAD models.