 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding-based Regression
Jan 31, 2025



Language models have recently been shown capable of performing regression tasks wherein numeric predictions are represented as decoded strings. In this work, we provide theoretical grounds for this capability and furthermore investigate the utility of causal auto-regressive sequence models when they are applied to any feature representation. We find that, despite being trained in the usual way - for next-token prediction via cross-entropy loss - decoding-based regression is as performant as traditional approaches for tabular regression tasks, while being flexible enough to capture arbitrary distributions, such as in the task of density estimation.
A Watermark for Black-Box Language Models
Oct 02, 2024



Watermarking has recently emerged as an effective strategy for detecting the outputs of large language models (LLMs). Most existing schemes require \emph{white-box} access to the model's next-token probability distribution, which is typically not accessible to downstream users of an LLM API. In this work, we propose a principled watermarking scheme that requires only the ability to sample sequences from the LLM (i.e. \emph{black-box} access), boasts a \emph{distortion-free} property, and can be chained or nested using multiple secret keys. We provide performance guarantees, demonstrate how it can be leveraged when white-box access is available, and show when it can outperform existing white-box schemes via comprehensive experiments.
A Universal Class of Sharpness-Aware Minimization Algorithms
Jun 06, 2024Recently, there has been a surge in interest in developing optimization algorithms for overparameterized models as achieving generalization is believed to require algorithms with suitable biases. This interest centers on minimizing sharpness of the original loss function; the Sharpness-Aware Minimization (SAM) algorithm has proven effective. However, most literature only considers a few sharpness measures, such as the maximum eigenvalue or trace of the training loss Hessian, which may not yield meaningful insights for non-convex optimization scenarios like neural networks. Additionally, many sharpness measures are sensitive to parameter invariances in neural networks, magnifying significantly under rescaling parameters. Motivated by these challenges, we introduce a new class of sharpness measures in this paper, leading to new sharpness-aware objective functions. We prove that these measures are \textit{universally expressive}, allowing any function of the training loss Hessian matrix to be represented by appropriate hyperparameters. Furthermore, we show that the proposed objective functions explicitly bias towards minimizing their corresponding sharpness measures, and how they allow meaningful applications to models with parameter invariances (such as scale-invariances). Finally, as instances of our proposed general framework, we present \textit{Frob-SAM} and \textit{Det-SAM}, which are specifically designed to minimize the Frobenius norm and the determinant of the Hessian of the training loss, respectively. We also demonstrate the advantages of our general framework through extensive experiments.
Sharpness-Aware Minimization Leads to Low-Rank Features
May 25, 2023



Sharpness-aware minimization (SAM) is a recently proposed method that minimizes the sharpness of the training loss of a neural network. While its generalization improvement is well-known and is the primary motivation, we uncover an additional intriguing effect of SAM: reduction of the feature rank which happens at different layers of a neural network. We show that this low-rank effect occurs very broadly: for different architectures such as fully-connected networks, convolutional networks, vision transformers and for different objectives such as regression, classification, language-image contrastive training. To better understand this phenomenon, we provide a mechanistic understanding of how low-rank features arise in a simple two-layer network. We observe that a significant number of activations gets entirely pruned by SAM which directly contributes to the rank reduction. We confirm this effect theoretically and check that it can also occur in deep networks, although the overall rank reduction mechanism can be more complex, especially for deep networks with pre-activation skip connections and self-attention layers. We make our code available at https://github.com/tml-epfl/sam-low-rank-features.
Is margin all you need? An extensive empirical study of active learning on tabular data
Oct 07, 2022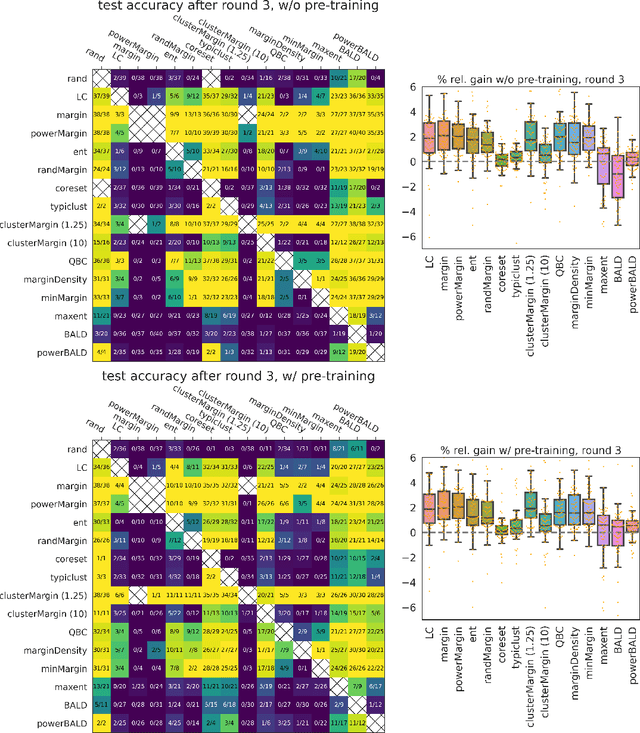
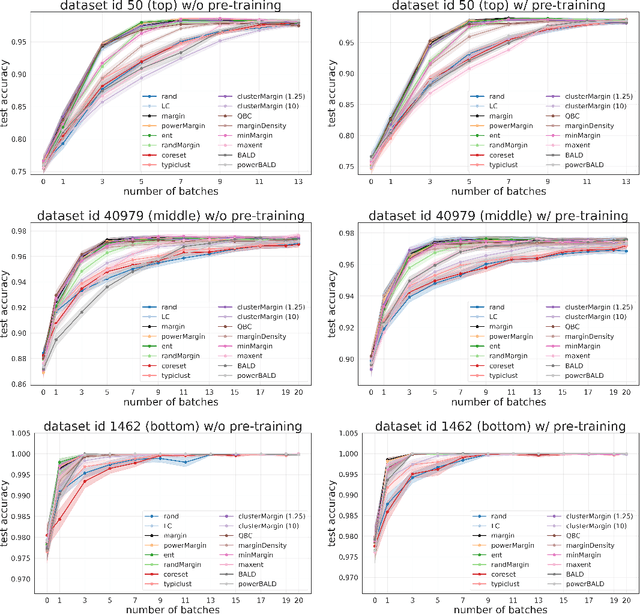
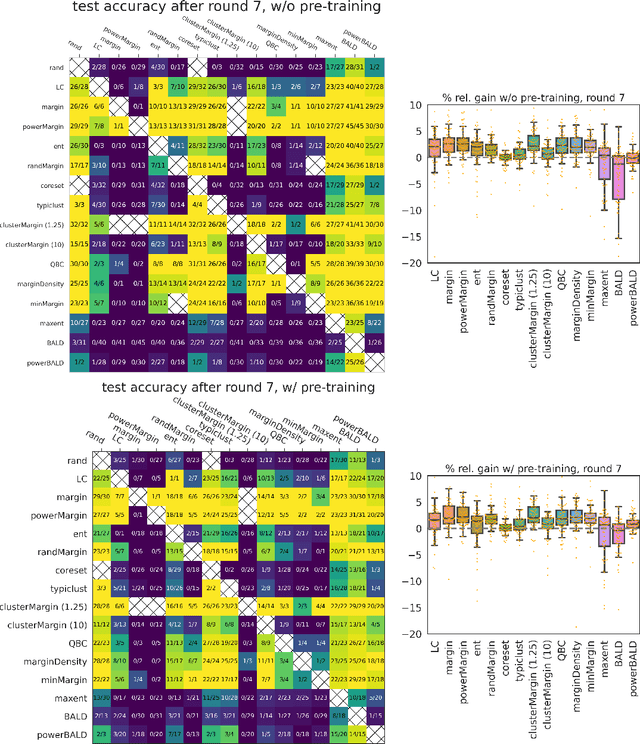
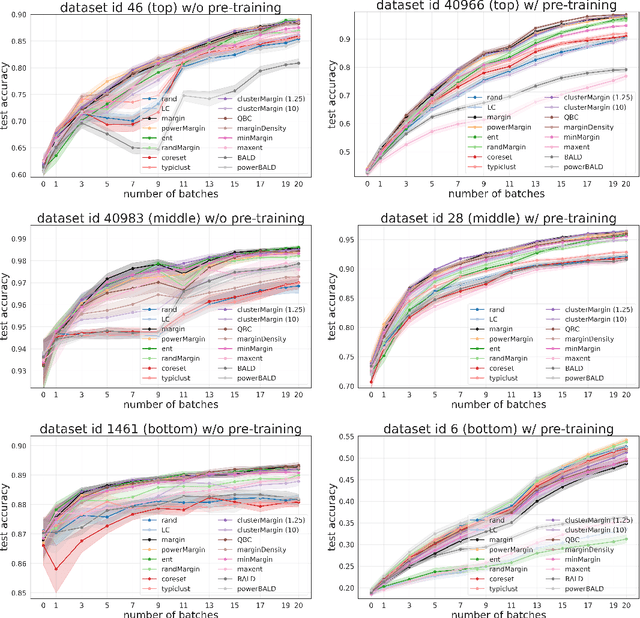
Given a labeled training set and a collection of unlabeled data, the goal of active learning (AL) is to identify the best unlabeled points to label. In this comprehensive study, we analyze the performance of a variety of AL algorithms on deep neural networks trained on 69 real-world tabular classification datasets from the OpenML-CC18 benchmark. We consider different data regimes and the effect of self-supervised model pre-training. Surprisingly, we find that the classical margin sampling technique matches or outperforms all others, including current state-of-art, in a wide range of experimental settings. To researchers, we hope to encourage rigorous benchmarking against margin, and to practitioners facing tabular data labeling constraints that hyper-parameter-free margin may often be all they need.
Confident Adaptive Language Modeling
Jul 14, 2022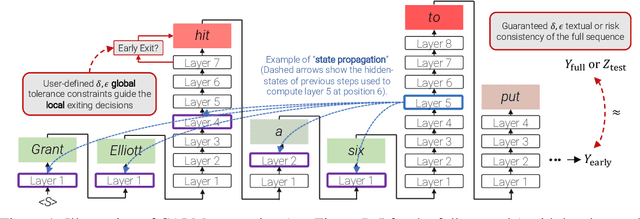
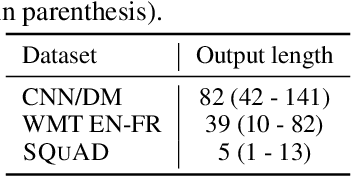
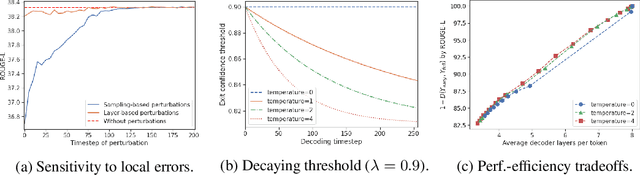
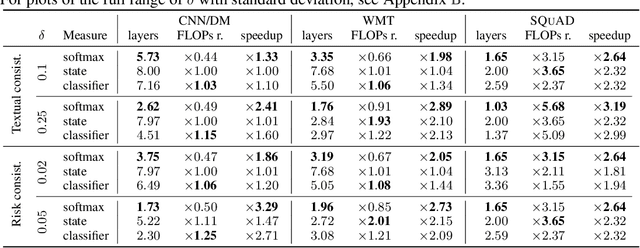
Recent advances in Transformer-based large language models (LLMs) have led to significant performance improvements across many tasks. These gains come with a drastic increase in the models' size, potentially leading to slow and costly use at inference time. In practice, however, the series of generations made by LLMs is composed of varying levels of difficulty. While certain predictions truly benefit from the models' full capacity, other continuations are more trivial and can be solved with reduced compute. In this work, we introduce Confident Adaptive Language Modeling (CALM), a framework for dynamically allocating different amounts of compute per input and generation timestep. Early exit decoding involves several challenges that we address here, such as: (1) what confidence measure to use; (2) connecting sequence-level constraints to local per-token exit decisions; and (3) attending back to missing hidden representations due to early exits in previous tokens. Through theoretical analysis and empirical experiments on three diverse text generation tasks, we demonstrate the efficacy of our framework in reducing compute -- potential speedup of up to $\times 3$ -- while provably maintaining high performance.
Unifying Language Learning Paradigms
May 10, 2022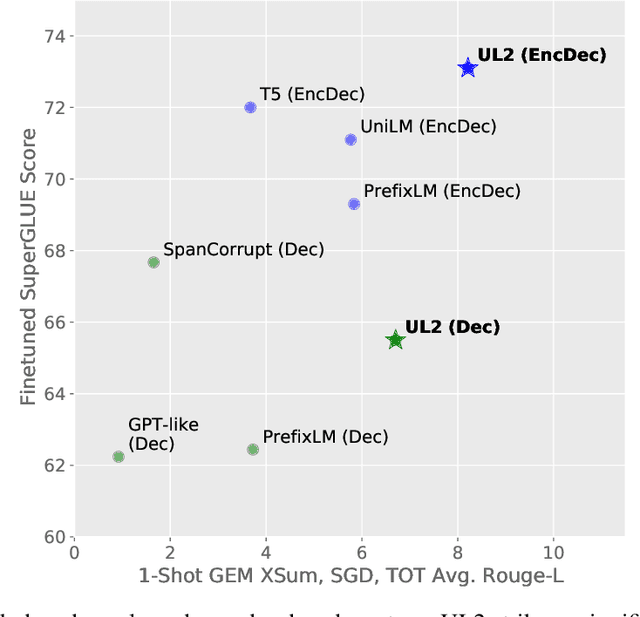

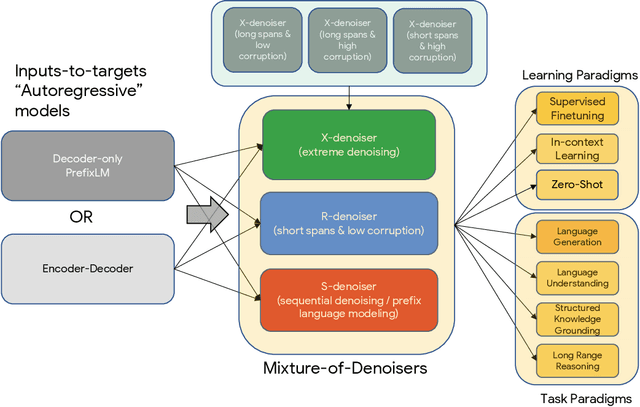
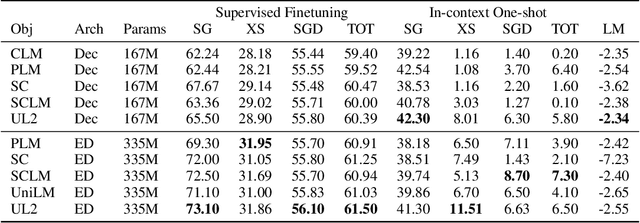
Existing pre-trained models are generally geared towards a particular class of problems. To date, there seems to be still no consensus on what the right architecture and pre-training setup should be. This paper presents a unified framework for pre-training models that are universally effective across datasets and setups. We begin by disentangling architectural archetypes with pre-training objectives -- two concepts that are commonly conflated. Next, we present a generalized and unified perspective for self-supervision in NLP and show how different pre-training objectives can be cast as one another and how interpolating between different objectives can be effective. We then propose Mixture-of-Denoisers (MoD), a pre-training objective that combines diverse pre-training paradigms together. We furthermore introduce a notion of mode switching, wherein downstream fine-tuning is associated with specific pre-training schemes. We conduct extensive ablative experiments to compare multiple pre-training objectives and find that our method pushes the Pareto-frontier by outperforming T5 and/or GPT-like models across multiple diverse setups. Finally, by scaling our model up to 20B parameters, we achieve SOTA performance on 50 well-established supervised NLP tasks ranging from language generation (with automated and human evaluation), language understanding, text classification, question answering, commonsense reasoning, long text reasoning, structured knowledge grounding and information retrieval. Our model also achieve strong results at in-context learning, outperforming 175B GPT-3 on zero-shot SuperGLUE and tripling the performance of T5-XXL on one-shot summarization. We release Flax-based T5X model checkpoints for the 20B model at \url{https://github.com/google-research/google-research/tree/master/ul2}.
ED2LM: Encoder-Decoder to Language Model for Faster Document Re-ranking Inference
Apr 25, 2022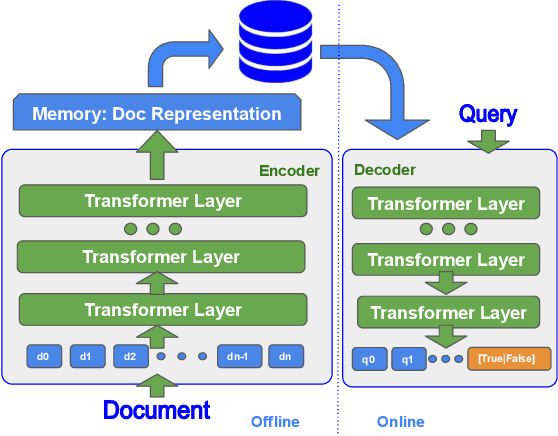
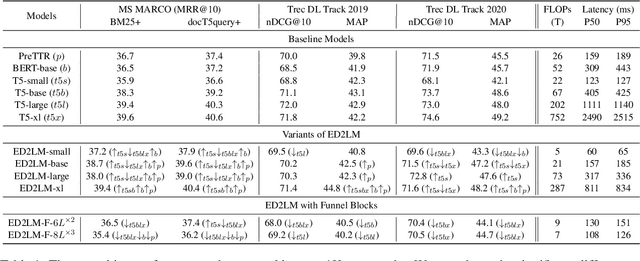
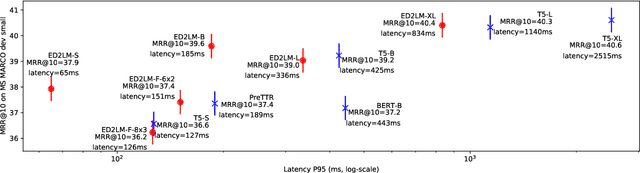
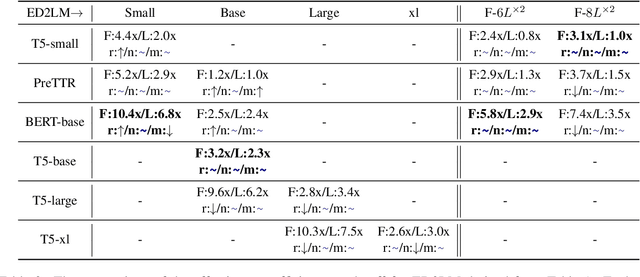
State-of-the-art neural models typically encode document-query pairs using cross-attention for re-ranking. To this end, models generally utilize an encoder-only (like BERT) paradigm or an encoder-decoder (like T5) approach. These paradigms, however, are not without flaws, i.e., running the model on all query-document pairs at inference-time incurs a significant computational cost. This paper proposes a new training and inference paradigm for re-ranking. We propose to finetune a pretrained encoder-decoder model using in the form of document to query generation. Subsequently, we show that this encoder-decoder architecture can be decomposed into a decoder-only language model during inference. This results in significant inference time speedups since the decoder-only architecture only needs to learn to interpret static encoder embeddings during inference. Our experiments show that this new paradigm achieves results that are comparable to the more expensive cross-attention ranking approaches while being up to 6.8X faster. We believe this work paves the way for more efficient neural rankers that leverage large pretrained models.
Transformer Memory as a Differentiable Search Index
Feb 16, 2022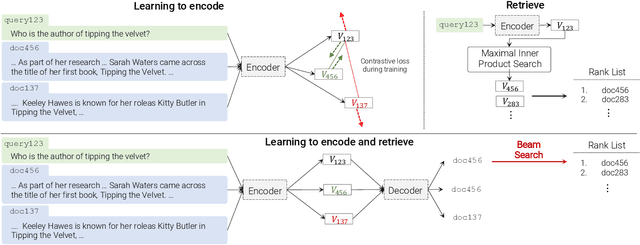
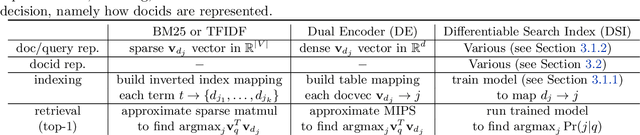
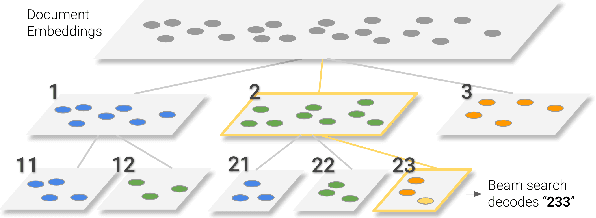
In this paper, we demonstrate that information retrieval can be accomplished with a single Transformer, in which all information about the corpus is encoded in the parameters of the model. To this end, we introduce the Differentiable Search Index (DSI), a new paradigm that learns a text-to-text model that maps string queries directly to relevant docids; in other words, a DSI model answers queries directly using only its parameters, dramatically simplifying the whole retrieval process. We study variations in how documents and their identifiers are represented, variations in training procedures, and the interplay between models and corpus sizes. Experiments demonstrate that given appropriate design choices, DSI significantly outperforms strong baselines such as dual encoder models. Moreover, DSI demonstrates strong generalization capabilities, outperforming a BM25 baseline in a zero-shot setup.
ExT5: Towards Extreme Multi-Task Scaling for Transfer Learning
Nov 22, 2021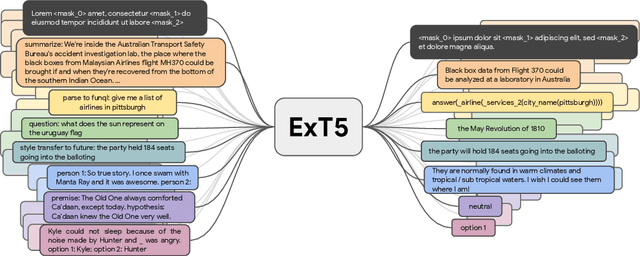
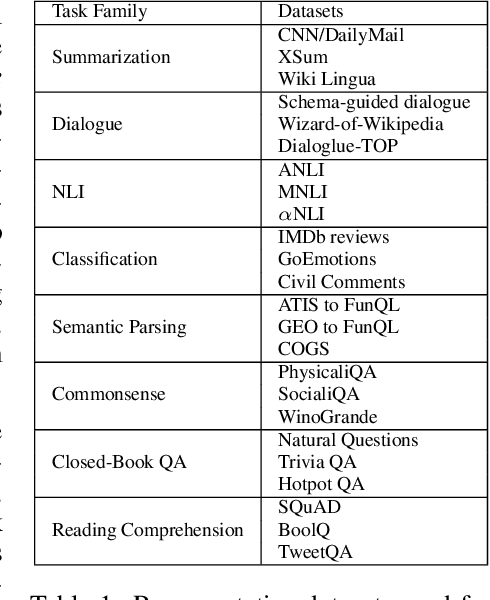
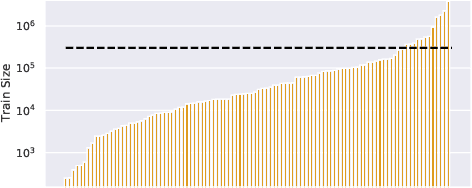
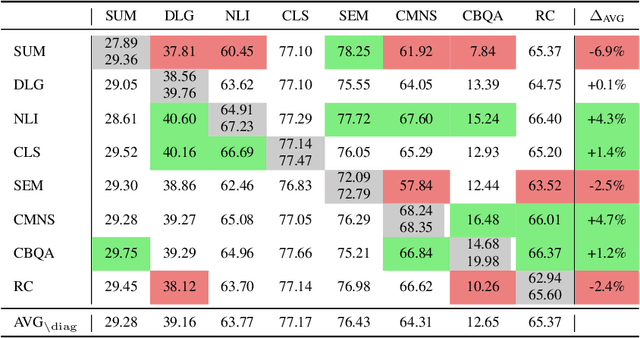
Despite the recent success of multi-task learning and transfer learning for natural language processing (NLP), few works have systematically studied the effect of scaling up the number of tasks during pre-training. Towards this goal, this paper introduces ExMix (Extreme Mixture): a massive collection of 107 supervised NLP tasks across diverse domains and task-families. Using ExMix, we study the effect of multi-task pre-training at the largest scale to date, and analyze co-training transfer amongst common families of tasks. Through this analysis, we show that manually curating an ideal set of tasks for multi-task pre-training is not straightforward, and that multi-task scaling can vastly improve models on its own. Finally, we propose ExT5: a model pre-trained using a multi-task objective of self-supervised span denoising and supervised ExMix. Via extensive experiments, we show that ExT5 outperforms strong T5 baselines on SuperGLUE, GEM, Rainbow, Closed-Book QA tasks, and several tasks outside of ExMix. ExT5 also significantly improves sample efficiency while pre-training.