 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopoMamba: Topology-Aware Scanning and Fusion for Segmenting Heterogeneous Medical Visual Media
Apr 28, 2026Visual state-space models (SSMs) have shown strong potential for medical image segmentation, yet their effectiveness is often limited by two practical issues: axis-biased scan ordering weakens the modeling of oblique and curved structures, and naive multi-branch fusion tends to amplify redundant responses. We present TopoMamba, a topology-aware scan-and-fuse framework for segmenting heterogeneous medical visual media. The method combines a diagonal/anti-diagonal TopoA-Scan branch with the standard Cross-Scan branch to provide complementary structural priors, and introduces ScanCache, a device-aware caching mechanism that amortizes explicit scan-index construction across recurring resolutions. To fuse heterogeneous scan features efficiently, we further propose a lightweight HSIC Gate that regulates branch interaction using a dependence-aware scalar gating rule. We also instantiate a volumetric TopoMamba-3D for practical 3D clinical segmentation. Experiments on Synapse CT, ISIC 2017 dermoscopy, and CVC-ClinicDB endoscopy show that TopoMamba consistently improves segmentation quality over strong CNN, Transformer, and SSM baselines, with particularly clear gains on thin or curved targets such as the pancreas and gallbladder, while maintaining favorable deployment efficiency under dynamic input resolutions. These results suggest that topology-aware scan ordering and lightweight dependence-aware fusion form an effective and practical design for medical multimedia segmentation. The code will be made publicly available.
CMAMRNet: A Contextual Mask-Aware Network Enhancing Mural Restoration Through Comprehensive Mask Guidance
Aug 10, 2025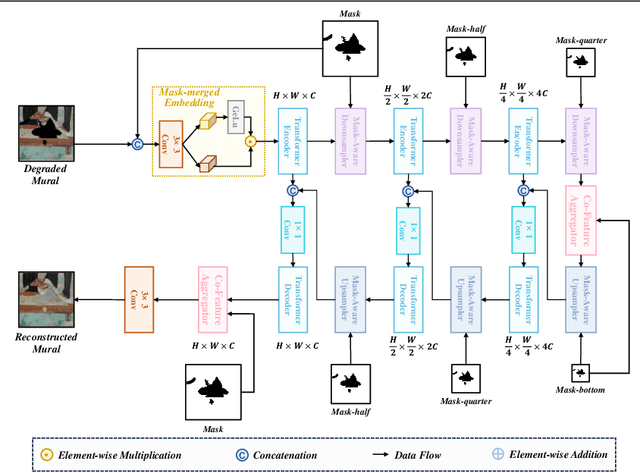
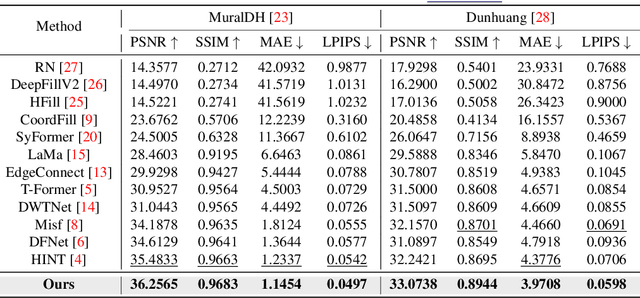
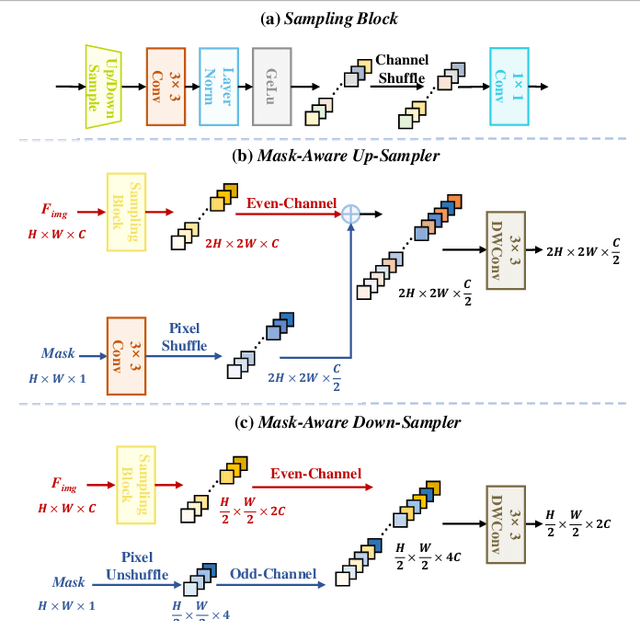
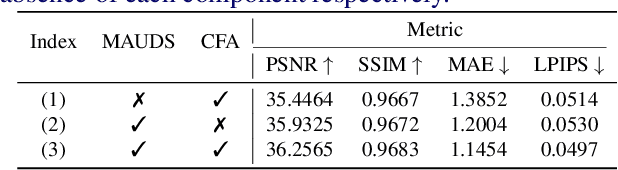
Murals, as invaluable cultural artifacts, face continuous deterioration from environmental factors and human activities. Digital restoration of murals faces unique challenges due to their complex degradation patterns and the critical need to preserve artistic authenticity. Existing learning-based methods struggle with maintaining consistent mask guidance throughout their networks, leading to insufficient focus on damaged regions and compromised restoration quality. We propose CMAMRNet, a Contextual Mask-Aware Mural Restoration Network that addresses these limitations through comprehensive mask guidance and multi-scale feature extraction. Our framework introduces two key components: (1) the Mask-Aware Up/Down-Sampler (MAUDS), which ensures consistent mask sensitivity across resolution scales through dedicated channel-wise feature selection and mask-guided feature fusion; and (2) the Co-Feature Aggregator (CFA), operating at both the highest and lowest resolutions to extract complementary features for capturing fine textures and global structures in degraded regions. Experimental results on benchmark datasets demonstrate that CMAMRNet outperforms state-of-the-art methods, effectively preserving both structural integrity and artistic details in restored murals. The code is available at~\href{https://github.com/CXH-Research/CMAMRNet}{https://github.com/CXH-Research/CMAMRNet}.
Test-Time Intensity Consistency Adaptation for Shadow Detection
Oct 10, 2024



Shadow detection is crucial for accurate scene understanding in computer vision, yet it is challenged by the diverse appearances of shadows caused by variations in illumination, object geometry, and scene context. Deep learning models often struggle to generalize to real-world images due to the limited size and diversity of training datasets. To address this, we introduce TICA, a novel framework that leverages light-intensity information during test-time adaptation to enhance shadow detection accuracy. TICA exploits the inherent inconsistencies in light intensity across shadow regions to guide the model toward a more consistent prediction. A basic encoder-decoder model is initially trained on a labeled dataset for shadow detection. Then, during the testing phase, the network is adjusted for each test sample by enforcing consistent intensity predictions between two augmented input image versions. This consistency training specifically targets both foreground and background intersection regions to identify shadow regions within images accurately for robust adaptation. Extensive evaluations on the ISTD and SBU shadow detection datasets reveal that TICA significantly demonstrates that TICA outperforms existing state-of-the-art methods, achieving superior results in balanced error rate (BER).
ForgeryTTT: Zero-Shot Image Manipulation Localization with Test-Time Training
Oct 05, 2024



Social media is increasingly plagued by realistic fake images, making it hard to trust content. Previous algorithms to detect these fakes often fail in new, real-world scenarios because they are trained on specific datasets. To address the problem, we introduce ForgeryTTT, the first method leveraging test-time training (TTT) to identify manipulated regions in images. The proposed approach fine-tunes the model for each individual test sample, improving its performance. ForgeryTTT first employs vision transformers as a shared image encoder to learn both classification and localization tasks simultaneously during the training-time training using a large synthetic dataset. Precisely, the localization head predicts a mask to highlight manipulated areas. Given such a mask, the input tokens can be divided into manipulated and genuine groups, which are then fed into the classification head to distinguish between manipulated and genuine parts. During test-time training, the predicted mask from the localization head is used for the classification head to update the image encoder for better adaptation. Additionally, using the classical dropout strategy in each token group significantly improves performance and efficiency. We test ForgeryTTT on five standard benchmarks. Despite its simplicity, ForgeryTTT achieves a 20.1% improvement in localization accuracy compared to other zero-shot methods and a 4.3% improvement over non-zero-shot techniques. Our code and data will be released upon publication.
SMAFormer: Synergistic Multi-Attention Transformer for Medical Image Segmentation
Aug 31, 2024



In medical image segmentation, specialized computer vision techniques, notably transformers grounded in attention mechanisms and residual networks employing skip connections, have been instrumental in advancing performance. Nonetheless, previous models often falter when segmenting small, irregularly shaped tumors. To this end, we introduce SMAFormer, an efficient, Transformer-based architecture that fuses multiple attention mechanisms for enhanced segmentation of small tumors and organs. SMAFormer can capture both local and global features for medical image segmentation. The architecture comprises two pivotal components. First, a Synergistic Multi-Attention (SMA) Transformer block is proposed, which has the benefits of Pixel Attention, Channel Attention, and Spatial Attention for feature enrichment. Second, addressing the challenge of information loss incurred during attention mechanism transitions and feature fusion, we design a Feature Fusion Modulator. This module bolsters the integration between the channel and spatial attention by mitigating reshaping-induced information attrition. To evaluate our method, we conduct extensive experiments on various medical image segmentation tasks, including multi-organ, liver tumor, and bladder tumor segmentation, achieving state-of-the-art results. Code and models are available at: \url{https://github.com/CXH-Research/SMAFormer}.
Depth-aware Test-Time Training for Zero-shot Video Object Segmentation
Mar 07, 2024



Zero-shot Video Object Segmentation (ZSVOS) aims at segmenting the primary moving object without any human annotations. Mainstream solutions mainly focus on learning a single model on large-scale video datasets, which struggle to generalize to unseen videos. In this work, we introduce a test-time training (TTT) strategy to address the problem. Our key insight is to enforce the model to predict consistent depth during the TTT process. In detail, we first train a single network to perform both segmentation and depth prediction tasks. This can be effectively learned with our specifically designed depth modulation layer. Then, for the TTT process, the model is updated by predicting consistent depth maps for the same frame under different data augmentations. In addition, we explore different TTT weight updating strategies. Our empirical results suggest that the momentum-based weight initialization and looping-based training scheme lead to more stable improvements. Experiments show that the proposed method achieves clear improvements on ZSVOS. Our proposed video TTT strategy provides significant superiority over state-of-the-art TTT methods. Our code is available at: https://nifangbaage.github.io/DATTT.
Explicit Visual Prompting for Universal Foreground Segmentations
May 29, 2023Foreground segmentation is a fundamental problem in computer vision, which includes salient object detection, forgery detection, defocus blur detection, shadow detection, and camouflage object detection. Previous works have typically relied on domain-specific solutions to address accuracy and robustness issues in those applications. In this paper, we present a unified framework for a number of foreground segmentation tasks without any task-specific designs. We take inspiration from the widely-used pre-training and then prompt tuning protocols in NLP and propose a new visual prompting model, named Explicit Visual Prompting (EVP). Different from the previous visual prompting which is typically a dataset-level implicit embedding, our key insight is to enforce the tunable parameters focusing on the explicit visual content from each individual image, i.e., the features from frozen patch embeddings and high-frequency components. Our method freezes a pre-trained model and then learns task-specific knowledge using a few extra parameters. Despite introducing only a small number of tunable parameters, EVP achieves superior performance than full fine-tuning and other parameter-efficient fine-tuning methods. Experiments in fourteen datasets across five tasks show the proposed method outperforms other task-specific methods while being considerably simple. The proposed method demonstrates the scalability in different architectures, pre-trained weights, and tasks. The code is available at: https://github.com/NiFangBaAGe/Explicit-Visual-Prompt.
Explicit Visual Prompting for Low-Level Structure Segmentations
Mar 21, 2023We consider the generic problem of detecting low-level structures in images, which includes segmenting the manipulated parts, identifying out-of-focus pixels, separating shadow regions, and detecting concealed objects. Whereas each such topic has been typically addressed with a domain-specific solution, we show that a unified approach performs well across all of them. We take inspiration from the widely-used pre-training and then prompt tuning protocols in NLP and propose a new visual prompting model, named Explicit Visual Prompting (EVP). Different from the previous visual prompting which is typically a dataset-level implicit embedding, our key insight is to enforce the tunable parameters focusing on the explicit visual content from each individual image, i.e., the features from frozen patch embeddings and the input's high-frequency components. The proposed EVP significantly outperforms other parameter-efficient tuning protocols under the same amount of tunable parameters (5.7% extra trainable parameters of each task). EVP also achieves state-of-the-art performances on diverse low-level structure segmentation tasks compared to task-specific solutions. Our code is available at: https://github.com/NiFangBaAGe/Explicit-Visual-Prompt.
CoordFill: Efficient High-Resolution Image Inpainting via Parameterized Coordinate Querying
Mar 15, 2023Image inpainting aims to fill the missing hole of the input. It is hard to solve this task efficiently when facing high-resolution images due to two reasons: (1) Large reception field needs to be handled for high-resolution image inpainting. (2) The general encoder and decoder network synthesizes many background pixels synchronously due to the form of the image matrix. In this paper, we try to break the above limitations for the first time thanks to the recent development of continuous implicit representation. In detail, we down-sample and encode the degraded image to produce the spatial-adaptive parameters for each spatial patch via an attentional Fast Fourier Convolution(FFC)-based parameter generation network. Then, we take these parameters as the weights and biases of a series of multi-layer perceptron(MLP), where the input is the encoded continuous coordinates and the output is the synthesized color value. Thanks to the proposed structure, we only encode the high-resolution image in a relatively low resolution for larger reception field capturing. Then, the continuous position encoding will be helpful to synthesize the photo-realistic high-frequency textures by re-sampling the coordinate in a higher resolution. Also, our framework enables us to query the coordinates of missing pixels only in parallel, yielding a more efficient solution than the previous methods. Experiments show that the proposed method achieves real-time performance on the 2048$\times$2048 images using a single GTX 2080 Ti GPU and can handle 4096$\times$4096 images, with much better performance than existing state-of-the-art methods visually and numerically. The code is available at: https://github.com/NiFangBaAGe/CoordFill.