 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCUA-Skill: Develop Skills for Computer Using Agent
Jan 28, 2026Computer-Using Agents (CUAs) aim to autonomously operate computer systems to complete real-world tasks. However, existing agentic systems remain difficult to scale and lag behind human performance. A key limitation is the absence of reusable and structured skill abstractions that capture how humans interact with graphical user interfaces and how to leverage these skills. We introduce CUA-Skill, a computer-using agentic skill base that encodes human computer-use knowledge as skills coupled with parameterized execution and composition graphs. CUA-Skill is a large-scale library of carefully engineered skills spanning common Windows applications, serving as a practical infrastructure and tool substrate for scalable, reliable agent development. Built upon this skill base, we construct CUA-Skill Agent, an end-to-end computer-using agent that supports dynamic skill retrieval, argument instantiation, and memory-aware failure recovery. Our results demonstrate that CUA-Skill substantially improves execution success rates and robustness on challenging end-to-end agent benchmarks, establishing a strong foundation for future computer-using agent development. On WindowsAgentArena, CUA-Skill Agent achieves state-of-the-art 57.5% (best of three) successful rate while being significantly more efficient than prior and concurrent approaches. The project page is available at https://microsoft.github.io/cua_skill/.
Hierarchical Self-Attention: Generalizing Neural Attention Mechanics to Multi-Scale Problems
Sep 18, 2025



Transformers and their attention mechanism have been revolutionary in the field of Machine Learning. While originally proposed for the language data, they quickly found their way to the image, video, graph, etc. data modalities with various signal geometries. Despite this versatility, generalizing the attention mechanism to scenarios where data is presented at different scales from potentially different modalities is not straightforward. The attempts to incorporate hierarchy and multi-modality within transformers are largely based on ad hoc heuristics, which are not seamlessly generalizable to similar problems with potentially different structures. To address this problem, in this paper, we take a fundamentally different approach: we first propose a mathematical construct to represent multi-modal, multi-scale data. We then mathematically derive the neural attention mechanics for the proposed construct from the first principle of entropy minimization. We show that the derived formulation is optimal in the sense of being the closest to the standard Softmax attention while incorporating the inductive biases originating from the hierarchical/geometric information of the problem. We further propose an efficient algorithm based on dynamic programming to compute our derived attention mechanism. By incorporating it within transformers, we show that the proposed hierarchical attention mechanism not only can be employed to train transformer models in hierarchical/multi-modal settings from scratch, but it can also be used to inject hierarchical information into classical, pre-trained transformer models post training, resulting in more efficient models in zero-shot manner.
Instruction Agent: Enhancing Agent with Expert Demonstration
Sep 08, 2025Graphical user interface (GUI) agents have advanced rapidly but still struggle with complex tasks involving novel UI elements, long-horizon actions, and personalized trajectories. In this work, we introduce Instruction Agent, a GUI agent that leverages expert demonstrations to solve such tasks, enabling completion of otherwise difficult workflows. Given a single demonstration, the agent extracts step-by-step instructions and executes them by strictly following the trajectory intended by the user, which avoids making mistakes during execution. The agent leverages the verifier and backtracker modules further to improve robustness. Both modules are critical to understand the current outcome from each action and handle unexpected interruptions(such as pop-up windows) during execution. Our experiments show that Instruction Agent achieves a 60% success rate on a set of tasks in OSWorld that all top-ranked agents failed to complete. The Instruction Agent offers a practical and extensible framework, bridging the gap between current GUI agents and reliable real-world GUI task automation.
Can Open-source LLMs Enhance Data Synthesis for Toxic Detection?: An Experimental Study
Dec 03, 2024



Effective toxic content detection relies heavily on high-quality and diverse data, which serves as the foundation for robust content moderation models. This study explores the potential of open-source LLMs for harmful data synthesis, utilizing prompt engineering and fine-tuning techniques to enhance data quality and diversity. In a two-stage evaluation, we first examine the capabilities of six open-source LLMs in generating harmful data across multiple datasets using prompt engineering. In the second stage, we fine-tune these models to improve data generation while addressing challenges such as hallucination, data duplication, and overfitting. Our findings reveal that Mistral excels in generating high-quality and diverse harmful data with minimal hallucination. Furthermore, fine-tuning enhances data quality, offering scalable and cost-effective solutions for augmenting datasets for specific toxic content detection tasks. These results emphasize the significance of data synthesis in building robust, standalone detection models and highlight the potential of open-source LLMs to advance smaller downstream content moderation systems. We implemented this approach in real-world industrial settings, demonstrating the feasibility and efficiency of fine-tuned open-source LLMs for harmful data synthesis.
Can Open-source LLMs Enhance Data Augmentation for Toxic Detection?: An Experimental Study
Nov 18, 2024High-quality, diverse harmful data is essential to addressing real-time applications in content moderation. Current state-of-the-art approaches to toxic content detection using GPT series models are costly and lack explainability. This paper investigates the use of prompt engineering and fine-tuning techniques on open-source LLMs to enhance harmful data augmentation specifically for toxic content detection. We conduct a two-stage empirical study, with stage 1 evaluating six open-source LLMs across multiple datasets using only prompt engineering and stage 2 focusing on fine-tuning. Our findings indicate that Mistral can excel in generating harmful data with minimal hallucination. While fine-tuning these models improves data quality and diversity, challenges such as data duplication and overfitting persist. Our experimental results highlight scalable, cost-effective strategies for enhancing toxic content detection systems. These findings not only demonstrate the potential of open-source LLMs in creating robust content moderation tools. The application of this method in real industrial scenarios further proves the feasibility and efficiency of the fine-tuned open-source LLMs for data augmentation. We hope our study will aid in understanding the capabilities and limitations of current models in toxic content detection and drive further advancements in this field.
VideoWebArena: Evaluating Long Context Multimodal Agents with Video Understanding Web Tasks
Oct 24, 2024



Videos are often used to learn or extract the necessary information to complete tasks in ways different than what text and static imagery alone can provide. However, many existing agent benchmarks neglect long-context video understanding, instead focusing on text or static image inputs. To bridge this gap, we introduce VideoWebArena (VideoWA), a benchmark for evaluating the capabilities of long-context multimodal agents for video understanding. VideoWA consists of 2,021 web agent tasks based on manually crafted video tutorials, which total almost four hours of content. For our benchmark, we define a taxonomy of long-context video-based agent tasks with two main areas of focus: skill retention and factual retention. While skill retention tasks evaluate whether an agent can use a given human demonstration to complete a task efficiently, the factual retention task evaluates whether an agent can retrieve instruction-relevant information from a video to complete a task. We find that the best model achieves 13.3% success on factual retention tasks and 45.8% on factual retention QA pairs, far below human performance at 73.9% and 79.3%, respectively. On skill retention tasks, long-context models perform worse with tutorials than without, exhibiting a 5% performance decrease in WebArena tasks and a 10.3% decrease in VisualWebArena tasks. Our work highlights the need to improve the agentic abilities of long-context multimodal models and provides a testbed for future development with long-context video agents.
Windows Agent Arena: Evaluating Multi-Modal OS Agents at Scale
Sep 12, 2024



Large language models (LLMs) show remarkable potential to act as computer agents, enhancing human productivity and software accessibility in multi-modal tasks that require planning and reasoning. However, measuring agent performance in realistic environments remains a challenge since: (i) most benchmarks are limited to specific modalities or domains (e.g. text-only, web navigation, Q&A, coding) and (ii) full benchmark evaluations are slow (on order of magnitude of days) given the multi-step sequential nature of tasks. To address these challenges, we introduce the Windows Agent Arena: a reproducible, general environment focusing exclusively on the Windows operating system (OS) where agents can operate freely within a real Windows OS and use the same wide range of applications, tools, and web browsers available to human users when solving tasks. We adapt the OSWorld framework (Xie et al., 2024) to create 150+ diverse Windows tasks across representative domains that require agent abilities in planning, screen understanding, and tool usage. Our benchmark is scalable and can be seamlessly parallelized in Azure for a full benchmark evaluation in as little as 20 minutes. To demonstrate Windows Agent Arena's capabilities, we also introduce a new multi-modal agent, Navi. Our agent achieves a success rate of 19.5% in the Windows domain, compared to 74.5% performance of an unassisted human. Navi also demonstrates strong performance on another popular web-based benchmark, Mind2Web. We offer extensive quantitative and qualitative analysis of Navi's performance, and provide insights into the opportunities for future research in agent development and data generation using Windows Agent Arena. Webpage: https://microsoft.github.io/WindowsAgentArena Code: https://github.com/microsoft/WindowsAgentArena
Data Processing Techniques for Modern Multimodal Models
Jul 27, 2024

Data processing plays an significant role in current multimodal model training. In this paper. we provide an comprehensive review of common data processing techniques used in modern multimodal model training with a focus on diffusion models and multimodal large language models (MLLMs). We summarized all techniques into four categories: data quality, data quantity, data distribution and data safety. We further present our findings in the choice of data process methods in different type of models. This study aims to provide guidance to multimodal models developers with effective data processing techniques.
The Prompt Report: A Systematic Survey of Prompting Techniques
Jun 06, 2024Generative Artificial Intelligence (GenAI) systems are being increasingly deployed across all parts of industry and research settings. Developers and end users interact with these systems through the use of prompting or prompt engineering. While prompting is a widespread and highly researched concept, there exists conflicting terminology and a poor ontological understanding of what constitutes a prompt due to the area's nascency. This paper establishes a structured understanding of prompts, by assembling a taxonomy of prompting techniques and analyzing their use. We present a comprehensive vocabulary of 33 vocabulary terms, a taxonomy of 58 text-only prompting techniques, and 40 techniques for other modalities. We further present a meta-analysis of the entire literature on natural language prefix-prompting.
AMPCliff: quantitative definition and benchmarking of activity cliffs in antimicrobial peptides
Apr 15, 2024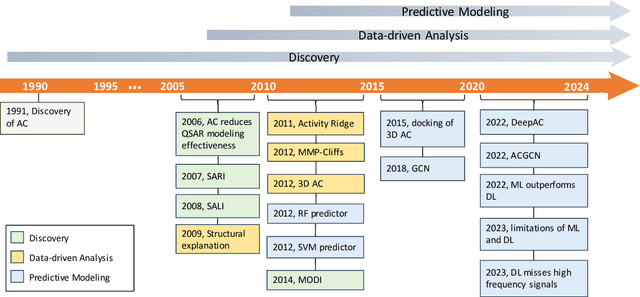

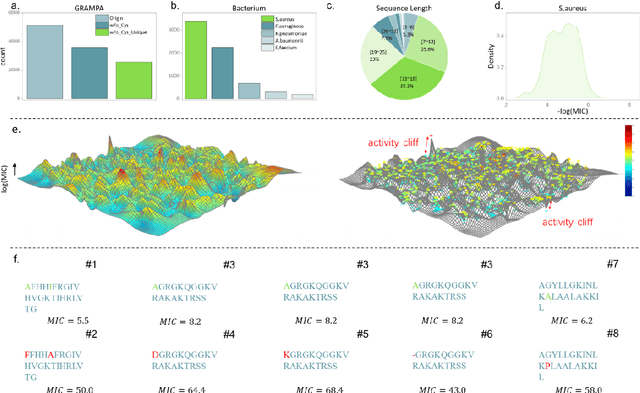
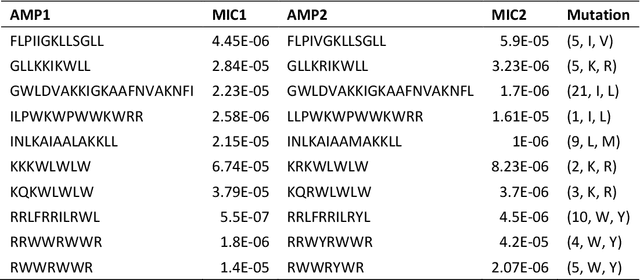
Activity cliff (AC) is a phenomenon that a pair of similar molecules differ by a small structural alternation but exhibit a large difference in their biochemical activities. The AC of small molecules has been extensively investigated but limited knowledge is accumulated about the AC phenomenon in peptides with canonical amino acids. This study introduces a quantitative definition and benchmarking framework AMPCliff for the AC phenomenon in antimicrobial peptides (AMPs) composed by canonical amino acids. A comprehensive analysis of the existing AMP dataset reveals a significant prevalence of AC within AMPs. AMPCliff quantifies the activities of AMPs by the metric minimum inhibitory concentration (MIC), and defines 0.9 as the minimum threshold for the normalized BLOSUM62 similarity score between a pair of aligned peptides with at least two-fold MIC changes. This study establishes a benchmark dataset of paired AMPs in Staphylococcus aureus from the publicly available AMP dataset GRAMPA, and conducts a rigorous procedure to evaluate various AMP AC prediction models, including nine machine learning, four deep learning algorithms, four masked language models, and four generative language models. Our analysis reveals that these models are capable of detecting AMP AC events and the pre-trained protein language ESM2 model demonstrates superior performance across the evaluations. The predictive performance of AMP activity cliffs remains to be further improved, considering that ESM2 with 33 layers only achieves the Spearman correlation coefficient=0.50 for the regression task of the MIC values on the benchmark dataset. Source code and additional resources are available at https://www.healthinformaticslab.org/supp/ or https://github.com/Kewei2023/AMPCliff-generation.