 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Aware Random Feature Kernel for Transformers
Mar 04, 2026Transformers excel across domains, yet their quadratic attention complexity poses a barrier to scaling. Random-feature attention, as in Performers, can reduce this cost to linear in the sequence length by approximating the softmax kernel with positive random features drawn from an isotropic distribution. In pretrained models, however, queries and keys are typically anisotropic. This induces high Monte Carlo variance in isotropic sampling schemes unless one retrains the model or uses a large feature budget. Importance sampling can address this by adapting the sampling distribution to the input geometry, but complex data-dependent proposal distributions are often intractable. We show that by data aligning the softmax kernel, we obtain an attention mechanism which can both admit a tractable minimal-variance proposal distribution for importance sampling, and exhibits better training stability. Motivated by this finding, we introduce DARKFormer, a Data-Aware Random-feature Kernel transformer that features a data-aligned kernel geometry. DARKFormer learns the random-projection covariance, efficiently realizing an importance-sampled positive random-feature estimator for its data-aligned kernel. Empirically, DARKFormer narrows the performance gap with exact softmax attention, particularly in finetuning regimes where pretrained representations are anisotropic. By combining random-feature efficiency with data-aware kernels, DARKFormer advances kernel-based attention in resource-constrained settings.
PlanGEN: A Multi-Agent Framework for Generating Planning and Reasoning Trajectories for Complex Problem Solving
Feb 22, 2025Recent agent frameworks and inference-time algorithms often struggle with complex planning problems due to limitations in verifying generated plans or reasoning and varying complexity of instances within a single task. Many existing methods for these tasks either perform task-level verification without considering constraints or apply inference-time algorithms without adapting to instance-level complexity. To address these limitations, we propose PlanGEN, a model-agnostic and easily scalable agent framework with three key components: constraint, verification, and selection agents. Specifically, our approach proposes constraint-guided iterative verification to enhance performance of inference-time algorithms--Best of N, Tree-of-Thought, and REBASE. In PlanGEN framework, the selection agent optimizes algorithm choice based on instance complexity, ensuring better adaptability to complex planning problems. Experimental results demonstrate significant improvements over the strongest baseline across multiple benchmarks, achieving state-of-the-art results on NATURAL PLAN ($\sim$8%$\uparrow$), OlympiadBench ($\sim$4%$\uparrow$), DocFinQA ($\sim$7%$\uparrow$), and GPQA ($\sim$1%$\uparrow$). Our key finding highlights that constraint-guided iterative verification improves inference-time algorithms, and adaptive selection further boosts performance on complex planning and reasoning problems.
Avoiding spurious sharpness minimization broadens applicability of SAM
Feb 04, 2025



Curvature regularization techniques like Sharpness Aware Minimization (SAM) have shown great promise in improving generalization on vision tasks. However, we find that SAM performs poorly in domains like natural language processing (NLP), often degrading performance -- even with twice the compute budget. We investigate the discrepancy across domains and find that in the NLP setting, SAM is dominated by regularization of the logit statistics -- instead of improving the geometry of the function itself. We use this observation to develop an alternative algorithm we call Functional-SAM, which regularizes curvature only through modification of the statistics of the overall function implemented by the neural network, and avoids spurious minimization through logit manipulation. Furthermore, we argue that preconditioning the SAM perturbation also prevents spurious minimization, and when combined with Functional-SAM, it gives further improvements. Our proposed algorithms show improved performance over AdamW and SAM baselines when trained for an equal number of steps, in both fixed-length and Chinchilla-style training settings, at various model scales (including billion-parameter scale). On the whole, our work highlights the importance of more precise characterizations of sharpness in broadening the applicability of curvature regularization to large language models (LLMs).
Neglected Hessian component explains mysteries in Sharpness regularization
Jan 24, 2024Recent work has shown that methods like SAM which either explicitly or implicitly penalize second order information can improve generalization in deep learning. Seemingly similar methods like weight noise and gradient penalties often fail to provide such benefits. We show that these differences can be explained by the structure of the Hessian of the loss. First, we show that a common decomposition of the Hessian can be quantitatively interpreted as separating the feature exploitation from feature exploration. The feature exploration, which can be described by the Nonlinear Modeling Error matrix (NME), is commonly neglected in the literature since it vanishes at interpolation. Our work shows that the NME is in fact important as it can explain why gradient penalties are sensitive to the choice of activation function. Using this insight we design interventions to improve performance. We also provide evidence that challenges the long held equivalence of weight noise and gradient penalties. This equivalence relies on the assumption that the NME can be ignored, which we find does not hold for modern networks since they involve significant feature learning. We find that regularizing feature exploitation but not feature exploration yields performance similar to gradient penalties.
On the Foundations of Shortcut Learning
Oct 24, 2023



Deep-learning models can extract a rich assortment of features from data. Which features a model uses depends not only on predictivity-how reliably a feature indicates train-set labels-but also on availability-how easily the feature can be extracted, or leveraged, from inputs. The literature on shortcut learning has noted examples in which models privilege one feature over another, for example texture over shape and image backgrounds over foreground objects. Here, we test hypotheses about which input properties are more available to a model, and systematically study how predictivity and availability interact to shape models' feature use. We construct a minimal, explicit generative framework for synthesizing classification datasets with two latent features that vary in predictivity and in factors we hypothesize to relate to availability, and quantify a model's shortcut bias-its over-reliance on the shortcut (more available, less predictive) feature at the expense of the core (less available, more predictive) feature. We find that linear models are relatively unbiased, but introducing a single hidden layer with ReLU or Tanh units yields a bias. Our empirical findings are consistent with a theoretical account based on Neural Tangent Kernels. Finally, we study how models used in practice trade off predictivity and availability in naturalistic datasets, discovering availability manipulations which increase models' degree of shortcut bias. Taken together, these findings suggest that the propensity to learn shortcut features is a fundamental characteristic of deep nonlinear architectures warranting systematic study given its role in shaping how models solve tasks.
Sharpness-Aware Minimization Leads to Low-Rank Features
May 25, 2023



Sharpness-aware minimization (SAM) is a recently proposed method that minimizes the sharpness of the training loss of a neural network. While its generalization improvement is well-known and is the primary motivation, we uncover an additional intriguing effect of SAM: reduction of the feature rank which happens at different layers of a neural network. We show that this low-rank effect occurs very broadly: for different architectures such as fully-connected networks, convolutional networks, vision transformers and for different objectives such as regression, classification, language-image contrastive training. To better understand this phenomenon, we provide a mechanistic understanding of how low-rank features arise in a simple two-layer network. We observe that a significant number of activations gets entirely pruned by SAM which directly contributes to the rank reduction. We confirm this effect theoretically and check that it can also occur in deep networks, although the overall rank reduction mechanism can be more complex, especially for deep networks with pre-activation skip connections and self-attention layers. We make our code available at https://github.com/tml-epfl/sam-low-rank-features.
On student-teacher deviations in distillation: does it pay to disobey?
Jan 30, 2023



Knowledge distillation has been widely-used to improve the performance of a "student" network by hoping to mimic soft probabilities of a "teacher" network. Yet, for self-distillation to work, the student must somehow deviate from the teacher (Stanton et al., 2021). But what is the nature of these deviations, and how do they relate to gains in generalization? We investigate these questions through a series of experiments across image and language classification datasets. First, we observe that distillation consistently deviates in a characteristic way: on points where the teacher has low confidence, the student achieves even lower confidence than the teacher. Secondly, we find that deviations in the initial dynamics of training are not crucial -- simply switching to distillation loss in the middle of training can recover much of its gains. We then provide two parallel theoretical perspectives to understand the role of student-teacher deviations in our experiments, one casting distillation as a regularizer in eigenspace, and another as a gradient denoiser. Our analysis bridges several gaps between existing theory and practice by (a) focusing on gradient-descent training, (b) by avoiding label noise assumptions, and (c) by unifying several disjoint empirical and theoretical findings.
Sharpness-Aware Minimization Improves Language Model Generalization
Oct 16, 2021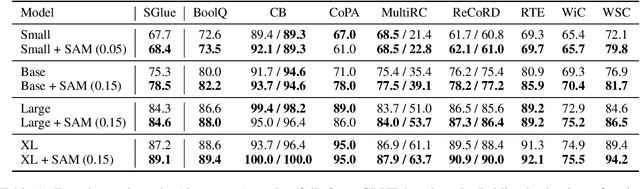
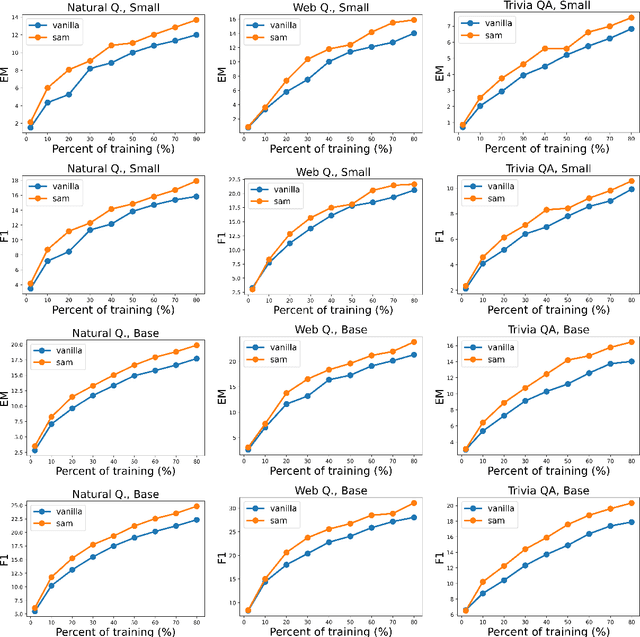
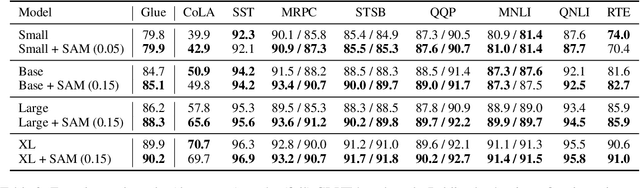
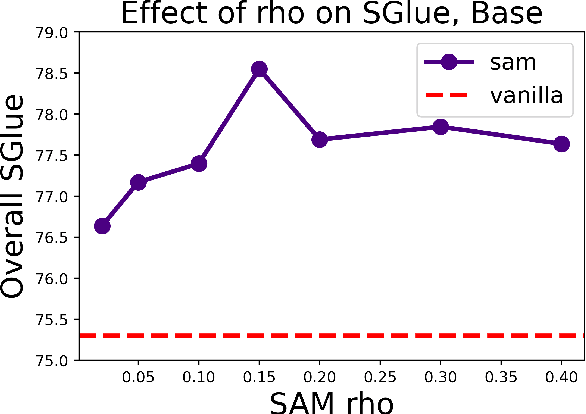
The allure of superhuman-level capabilities has led to considerable interest in language models like GPT-3 and T5, wherein the research has, by and large, revolved around new model architectures, training tasks, and loss objectives, along with substantial engineering efforts to scale up model capacity and dataset size. Comparatively little work has been done to improve the generalization of these models through better optimization. In this work, we show that Sharpness-Aware Minimization (SAM), a recently proposed optimization procedure that encourages convergence to flatter minima, can substantially improve the generalization of language models without much computational overhead. We show that SAM is able to boost performance on SuperGLUE, GLUE, Web Questions, Natural Questions, Trivia QA, and TyDiQA, with particularly large gains when training data for these tasks is limited.
The Low-Rank Simplicity Bias in Deep Networks
Mar 18, 2021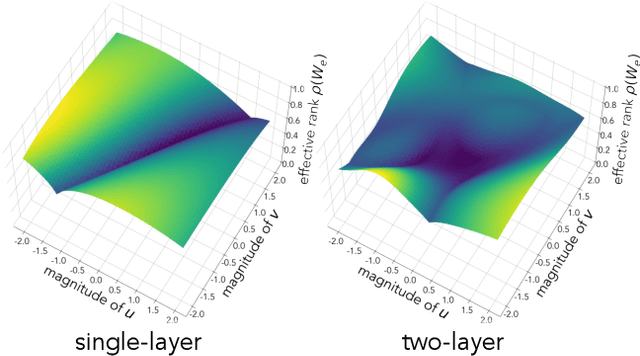
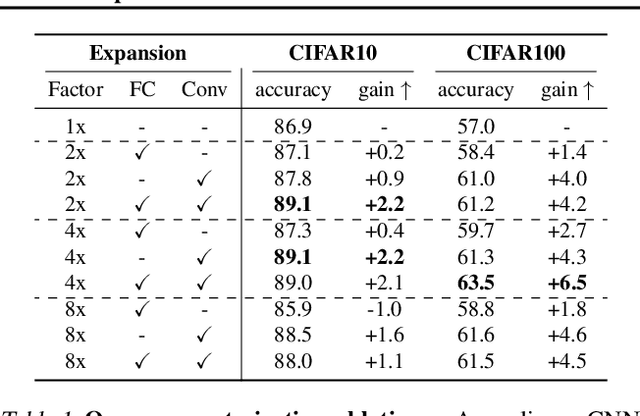
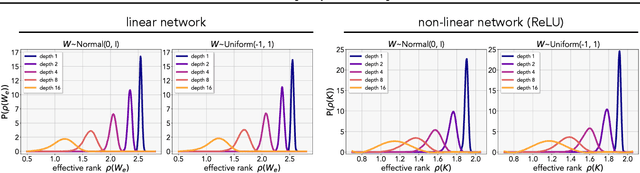
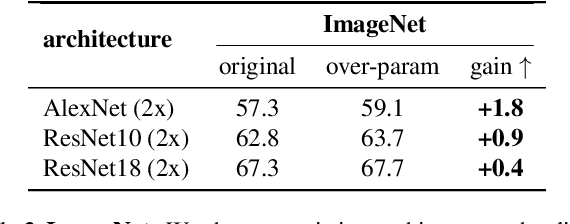
Modern deep neural networks are highly over-parameterized compared to the data on which they are trained, yet they often generalize remarkably well. A flurry of recent work has asked: why do deep networks not overfit to their training data? We investigate the hypothesis that deeper nets are implicitly biased to find lower rank solutions and that these are the solutions that generalize well. We prove for the asymptotic case that the percent volume of low effective-rank solutions increases monotonically as linear neural networks are made deeper. We then show empirically that our claim holds true on finite width models. We further empirically find that a similar result holds for non-linear networks: deeper non-linear networks learn a feature space whose kernel has a lower rank. We further demonstrate how linear over-parameterization of deep non-linear models can be used to induce low-rank bias, improving generalization performance without changing the effective model capacity. We evaluate on various model architectures and demonstrate that linearly over-parameterized models outperform existing baselines on image classification tasks, including ImageNet.
NeurIPS 2020 Competition: Predicting Generalization in Deep Learning
Dec 14, 2020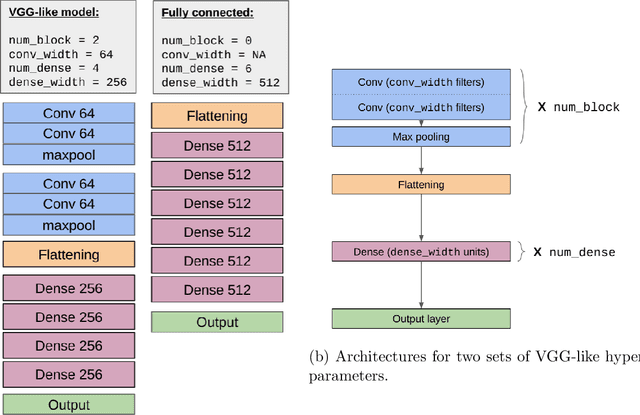
Understanding generalization in deep learning is arguably one of the most important questions in deep learning. Deep learning has been successfully adopted to a large number of problems ranging from pattern recognition to complex decision making, but many recent researchers have raised many concerns about deep learning, among which the most important is generalization. Despite numerous attempts, conventional statistical learning approaches have yet been able to provide a satisfactory explanation on why deep learning works. A recent line of works aims to address the problem by trying to predict the generalization performance through complexity measures. In this competition, we invite the community to propose complexity measures that can accurately predict generalization of models. A robust and general complexity measure would potentially lead to a better understanding of deep learning's underlying mechanism and behavior of deep models on unseen data, or shed light on better generalization bounds. All these outcomes will be important for making deep learning more robust and reliable.