 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
On Gradient-like Explanation under a Black-box Setting: When Black-box Explanations Become as Good as White-box
Aug 18, 2023
Attribution methods shed light on the explainability of data-driven approaches such as deep learning models by revealing the most contributing features to decisions that have been made. A widely accepted way of deriving feature attributions is to analyze the gradients of the target function with respect to input features. Analysis of gradients requires full access to the target system, meaning that solutions of this kind treat the target system as a white-box. However, the white-box assumption may be untenable due to security and safety concerns, thus limiting their practical applications. As an answer to the limited flexibility, this paper presents GEEX (gradient-estimation-based explanation), an explanation method that delivers gradient-like explanations under a black-box setting. Furthermore, we integrate the proposed method with a path method. The resulting approach iGEEX (integrated GEEX) satisfies the four fundamental axioms of attribution methods: sensitivity, insensitivity, implementation invariance, and linearity. With a focus on image data, the exhaustive experiments empirically show that the proposed methods outperform state-of-the-art black-box methods and achieve competitive performance compared to the ones with full access.
Masked Diffusion as Self-supervised Representation Learner
Aug 10, 2023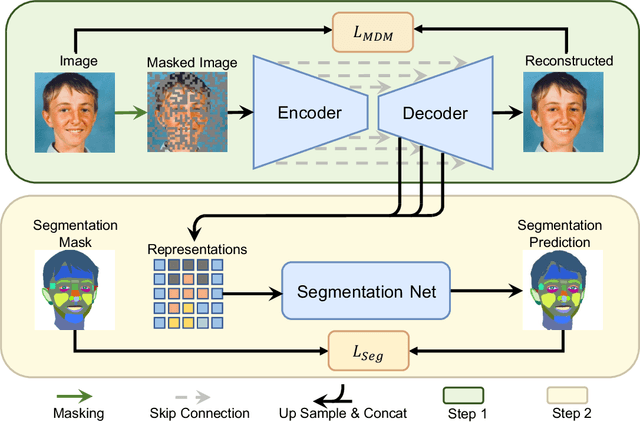
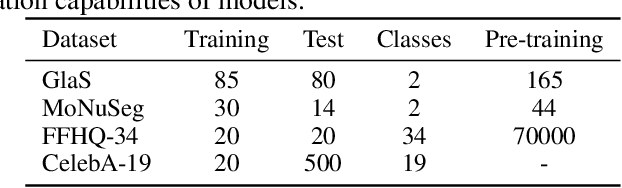
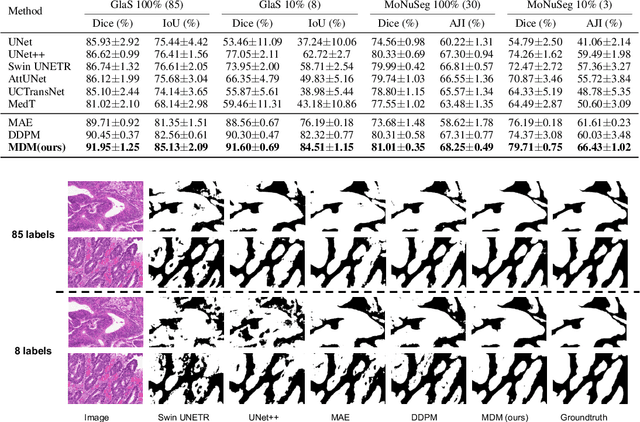

Denoising diffusion probabilistic models have recently demonstrated state-of-the-art generative performance and been used as strong pixel-level representation learners. This paper decomposes the interrelation between the generative capability and representation learning ability inherent in diffusion models. We present masked diffusion model (MDM), a scalable self-supervised representation learner that substitutes the conventional additive Gaussian noise of traditional diffusion with a masking mechanism. Our proposed approach convincingly surpasses prior benchmarks, demonstrating remarkable advancements in both medical and natural image semantic segmentation tasks, particularly within the context of few-shot scenario.
Vista-Morph: Unsupervised Image Registration of Visible-Thermal Facial Pairs
Jun 10, 2023
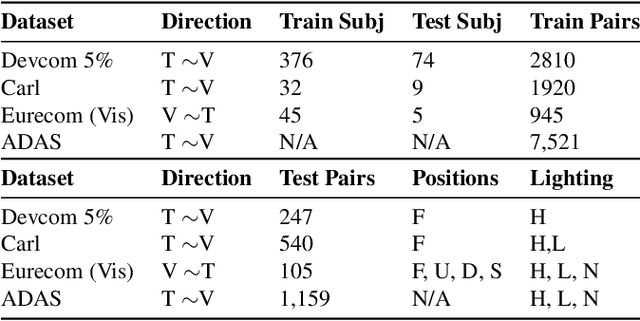
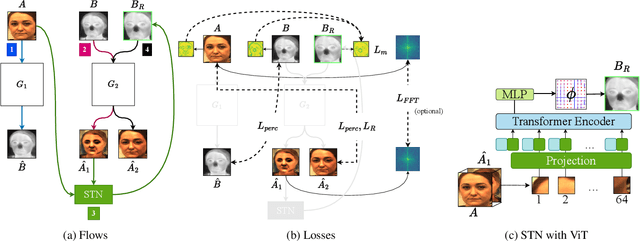
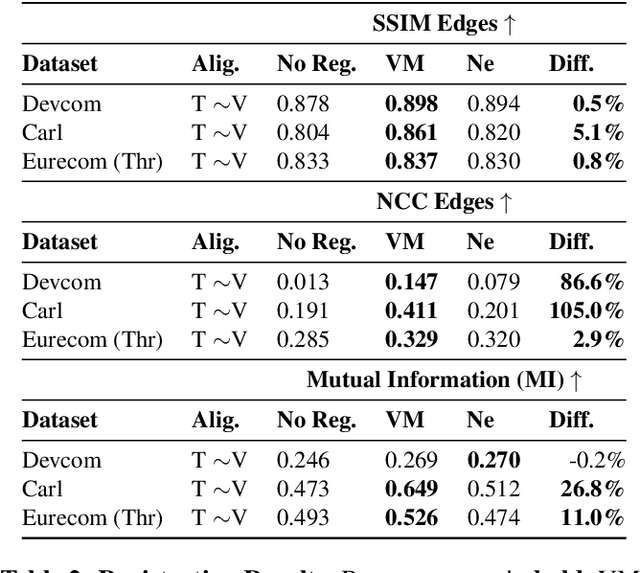
For a variety of biometric cross-spectral tasks, Visible-Thermal (VT) facial pairs are used. However, due to a lack of calibration in the lab, photographic capture between two different sensors leads to severely misaligned pairs that can lead to poor results for person re-identification and generative AI. To solve this problem, we introduce our approach for VT image registration called Vista Morph. Unlike existing VT facial registration that requires manual, hand-crafted features for pixel matching and/or a supervised thermal reference, Vista Morph is completely unsupervised without the need for a reference. By learning the affine matrix through a Vision Transformer (ViT)-based Spatial Transformer Network (STN) and Generative Adversarial Networks (GAN), Vista Morph successfully aligns facial and non-facial VT images. Our approach learns warps in Hard, No, and Low-light visual settings and is robust to geometric perturbations and erasure at test time. We conduct a downstream generative AI task to show that registering training data with Vista Morph improves subject identity of generated thermal faces when performing V2T image translation.
DPOK: Reinforcement Learning for Fine-tuning Text-to-Image Diffusion Models
May 25, 2023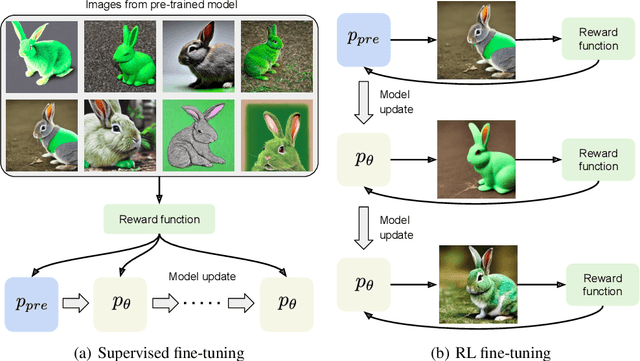


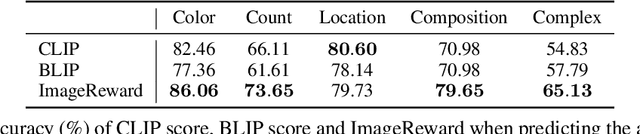
Learning from human feedback has been shown to improve text-to-image models. These techniques first learn a reward function that captures what humans care about in the task and then improve the models based on the learned reward function. Even though relatively simple approaches (e.g., rejection sampling based on reward scores) have been investigated, fine-tuning text-to-image models with the reward function remains challenging. In this work, we propose using online reinforcement learning (RL) to fine-tune text-to-image models. We focus on diffusion models, defining the fine-tuning task as an RL problem, and updating the pre-trained text-to-image diffusion models using policy gradient to maximize the feedback-trained reward. Our approach, coined DPOK, integrates policy optimization with KL regularization. We conduct an analysis of KL regularization for both RL fine-tuning and supervised fine-tuning. In our experiments, we show that DPOK is generally superior to supervised fine-tuning with respect to both image-text alignment and image quality.
Diffusion Model for Camouflaged Object Detection
Aug 01, 2023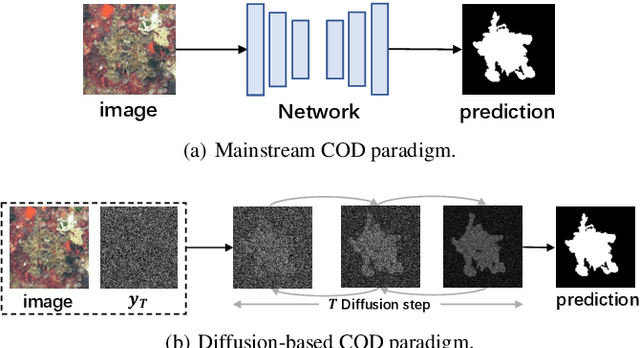
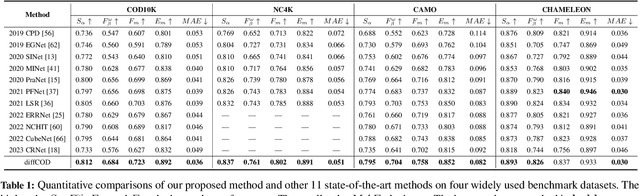
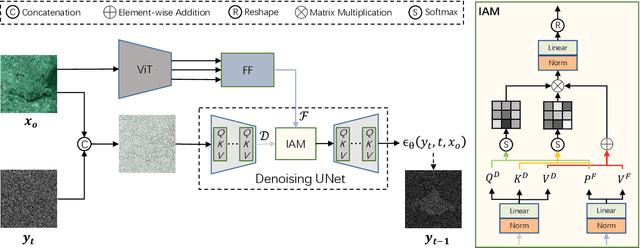
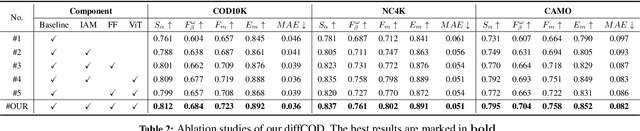
Camouflaged object detection is a challenging task that aims to identify objects that are highly similar to their background. Due to the powerful noise-to-image denoising capability of denoising diffusion models, in this paper, we propose a diffusion-based framework for camouflaged object detection, termed diffCOD, a new framework that considers the camouflaged object segmentation task as a denoising diffusion process from noisy masks to object masks. Specifically, the object mask diffuses from the ground-truth masks to a random distribution, and the designed model learns to reverse this noising process. To strengthen the denoising learning, the input image prior is encoded and integrated into the denoising diffusion model to guide the diffusion process. Furthermore, we design an injection attention module (IAM) to interact conditional semantic features extracted from the image with the diffusion noise embedding via the cross-attention mechanism to enhance denoising learning. Extensive experiments on four widely used COD benchmark datasets demonstrate that the proposed method achieves favorable performance compared to the existing 11 state-of-the-art methods, especially in the detailed texture segmentation of camouflaged objects. Our code will be made publicly available at: https://github.com/ZNan-Chen/diffCOD.
Toward Zero-shot Character Recognition: A Gold Standard Dataset with Radical-level Annotations
Aug 01, 2023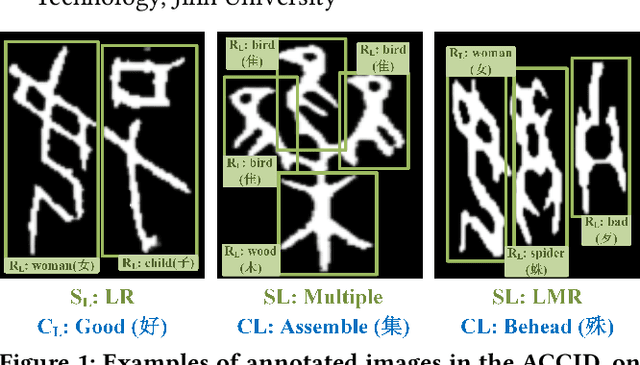
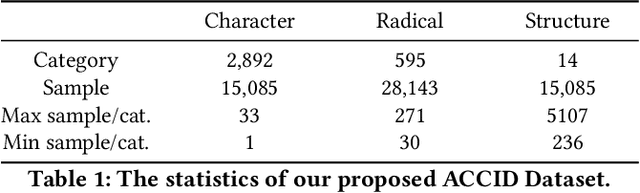
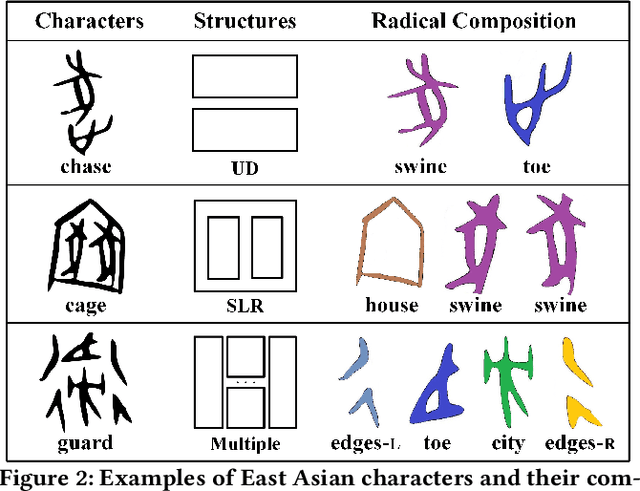

Optical character recognition (OCR) methods have been applied to diverse tasks, e.g., street view text recognition and document analysis. Recently, zero-shot OCR has piqued the interest of the research community because it considers a practical OCR scenario with unbalanced data distribution. However, there is a lack of benchmarks for evaluating such zero-shot methods that apply a divide-and-conquer recognition strategy by decomposing characters into radicals. Meanwhile, radical recognition, as another important OCR task, also lacks radical-level annotation for model training. In this paper, we construct an ancient Chinese character image dataset that contains both radical-level and character-level annotations to satisfy the requirements of the above-mentioned methods, namely, ACCID, where radical-level annotations include radical categories, radical locations, and structural relations. To increase the adaptability of ACCID, we propose a splicing-based synthetic character algorithm to augment the training samples and apply an image denoising method to improve the image quality. By introducing character decomposition and recombination, we propose a baseline method for zero-shot OCR. The experimental results demonstrate the validity of ACCID and the baseline model quantitatively and qualitatively.
LATR: 3D Lane Detection from Monocular Images with Transformer
Aug 08, 2023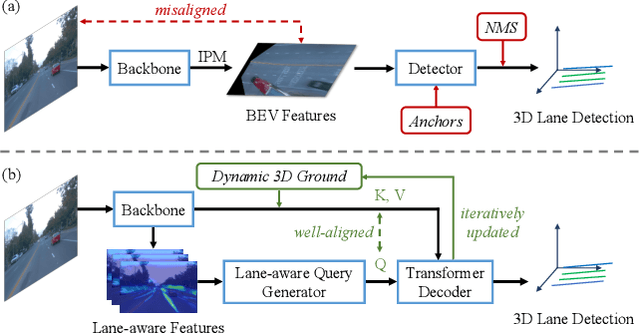
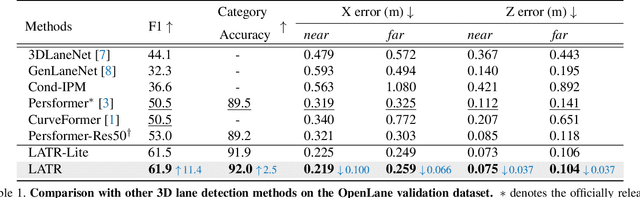
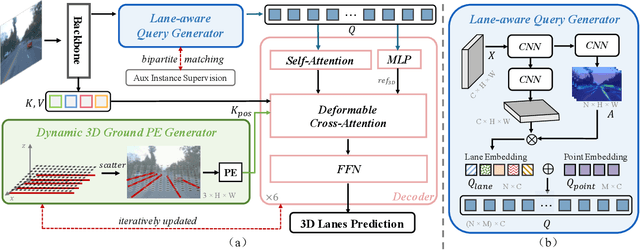
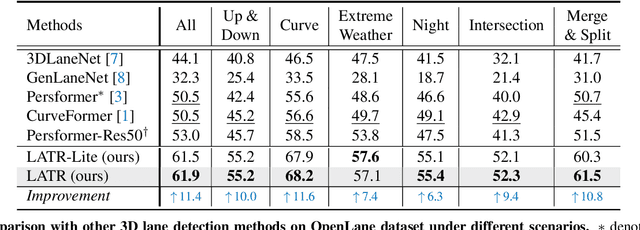
3D lane detection from monocular images is a fundamental yet challenging task in autonomous driving. Recent advances primarily rely on structural 3D surrogates (e.g., bird's eye view) that are built from front-view image features and camera parameters. However, the depth ambiguity in monocular images inevitably causes misalignment between the constructed surrogate feature map and the original image, posing a great challenge for accurate lane detection. To address the above issue, we present a novel LATR model, an end-to-end 3D lane detector that uses 3D-aware front-view features without transformed view representation. Specifically, LATR detects 3D lanes via cross-attention based on query and key-value pairs, constructed using our lane-aware query generator and dynamic 3D ground positional embedding. On the one hand, each query is generated based on 2D lane-aware features and adopts a hybrid embedding to enhance the lane information. On the other hand, 3D space information is injected as positional embedding from an iteratively-updated 3D ground plane. LATR outperforms previous state-of-the-art methods on both synthetic Apollo and realistic OpenLane by large margins (e.g., 11.4 gains in terms of F1 score on OpenLane). Code will be released at https://github.com/JMoonr/LATR.
LOTUS: Learning to Optimize Task-based US representations
Jul 29, 2023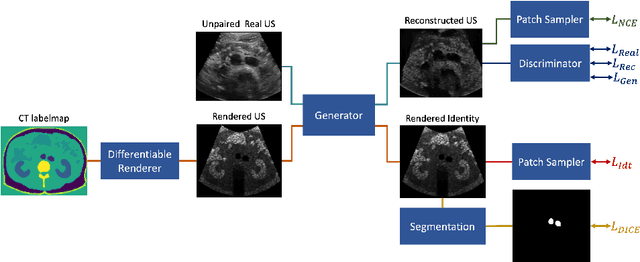

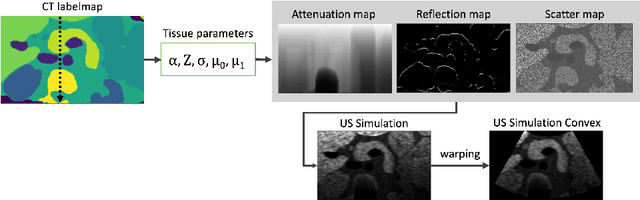
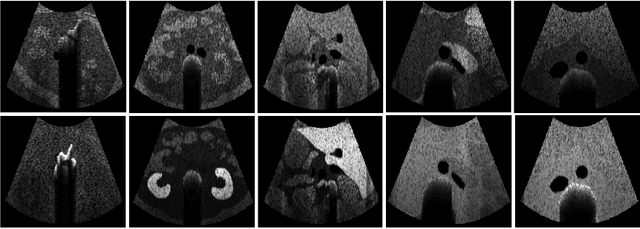
Anatomical segmentation of organs in ultrasound images is essential to many clinical applications, particularly for diagnosis and monitoring. Existing deep neural networks require a large amount of labeled data for training in order to achieve clinically acceptable performance. Yet, in ultrasound, due to characteristic properties such as speckle and clutter, it is challenging to obtain accurate segmentation boundaries, and precise pixel-wise labeling of images is highly dependent on the expertise of physicians. In contrast, CT scans have higher resolution and improved contrast, easing organ identification. In this paper, we propose a novel approach for learning to optimize task-based ultra-sound image representations. Given annotated CT segmentation maps as a simulation medium, we model acoustic propagation through tissue via ray-casting to generate ultrasound training data. Our ultrasound simulator is fully differentiable and learns to optimize the parameters for generating physics-based ultrasound images guided by the downstream segmentation task. In addition, we train an image adaptation network between real and simulated images to achieve simultaneous image synthesis and automatic segmentation on US images in an end-to-end training setting. The proposed method is evaluated on aorta and vessel segmentation tasks and shows promising quantitative results. Furthermore, we also conduct qualitative results of optimized image representations on other organs.
Self-Enhancement Improves Text-Image Retrieval in Foundation Visual-Language Models
Jun 11, 2023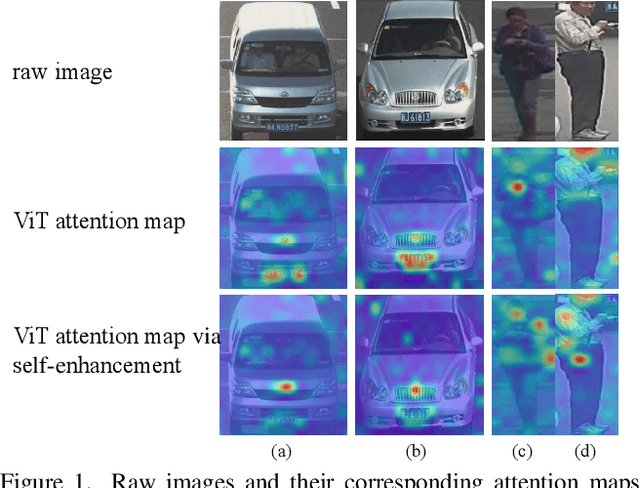
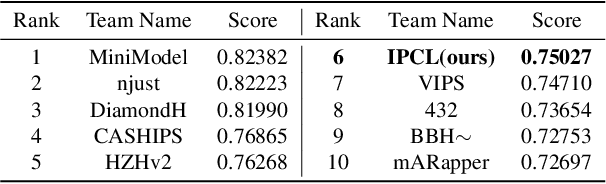
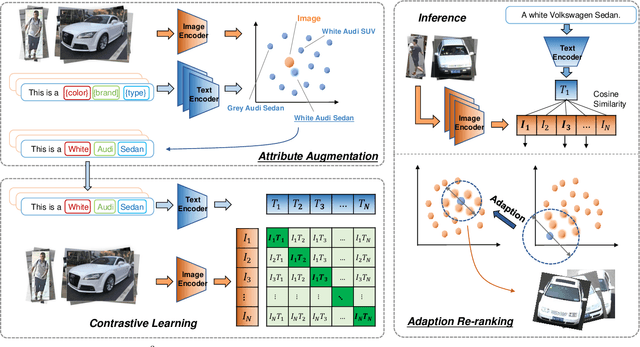

The emergence of cross-modal foundation models has introduced numerous approaches grounded in text-image retrieval. However, on some domain-specific retrieval tasks, these models fail to focus on the key attributes required. To address this issue, we propose a self-enhancement framework, A^{3}R, based on the CLIP-ViT/G-14, one of the largest cross-modal models. First, we perform an Attribute Augmentation strategy to enrich the textual description for fine-grained representation before model learning. Then, we propose an Adaption Re-ranking method to unify the representation space of textual query and candidate images and re-rank candidate images relying on the adapted query after model learning. The proposed framework is validated to achieve a salient improvement over the baseline and other teams' solutions in the cross-modal image retrieval track of the 1st foundation model challenge without introducing any additional samples. The code is available at \url{https://github.com/CapricornGuang/A3R}.
R-LPIPS: An Adversarially Robust Perceptual Similarity Metric
Jul 31, 2023
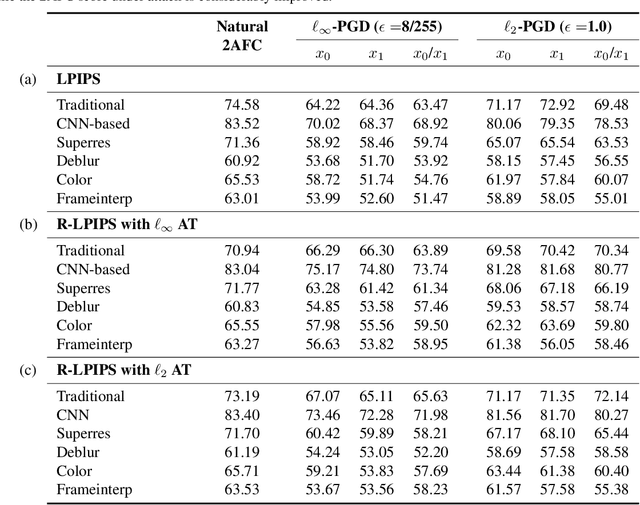
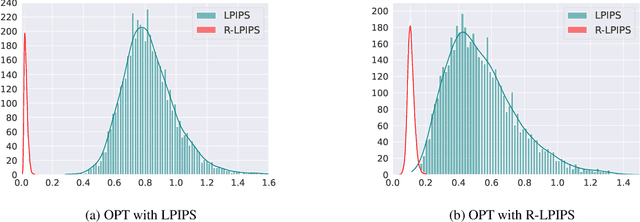
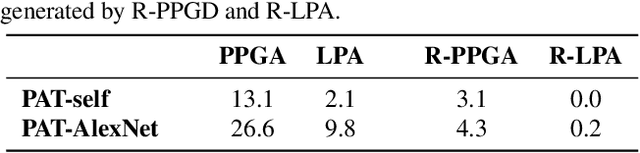
Similarity metrics have played a significant role in computer vision to capture the underlying semantics of images. In recent years, advanced similarity metrics, such as the Learned Perceptual Image Patch Similarity (LPIPS), have emerged. These metrics leverage deep features extracted from trained neural networks and have demonstrated a remarkable ability to closely align with human perception when evaluating relative image similarity. However, it is now well-known that neural networks are susceptible to adversarial examples, i.e., small perturbations invisible to humans crafted to deliberately mislead the model. Consequently, the LPIPS metric is also sensitive to such adversarial examples. This susceptibility introduces significant security concerns, especially considering the widespread adoption of LPIPS in large-scale applications. In this paper, we propose the Robust Learned Perceptual Image Patch Similarity (R-LPIPS) metric, a new metric that leverages adversarially trained deep features. Through a comprehensive set of experiments, we demonstrate the superiority of R-LPIPS compared to the classical LPIPS metric. The code is available at https://github.com/SaraGhazanfari/R-LPIPS.