 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanoramic Multimodal Semantic Occupancy Prediction for Quadruped Robots
Mar 13, 2026Panoramic imagery provides holistic 360° visual coverage for perception in quadruped robots. However, existing occupancy prediction methods are mainly designed for wheeled autonomous driving and rely heavily on RGB cues, limiting their robustness in complex environments. To bridge this gap, (1) we present PanoMMOcc, the first real-world panoramic multimodal occupancy dataset for quadruped robots, featuring four sensing modalities across diverse scenes. (2) We propose a panoramic multimodal occupancy perception framework, VoxelHound, tailored for legged mobility and spherical imaging. Specifically, we design (i) a Vertical Jitter Compensation (VJC) module to mitigate severe viewpoint perturbations caused by body pitch and roll during mobility, enabling more consistent spatial reasoning, and (ii) an effective Multimodal Information Prompt Fusion (MIPF) module that jointly leverages panoramic visual cues and auxiliary modalities to enhance volumetric occupancy prediction. (3) We establish a benchmark based on PanoMMOcc and provide detailed data analysis to enable systematic evaluation of perception methods under challenging embodied scenarios. Extensive experiments demonstrate that VoxelHound achieves state-of-the-art performance on PanoMMOcc (+4.16%} in mIoU). The dataset and code will be publicly released to facilitate future research on panoramic multimodal 3D perception for embodied robotic systems at https://github.com/SXDR/PanoMMOcc, along with the calibration tools released at https://github.com/losehu/CameraLiDAR-Calib.
Spherical-GOF: Geometry-Aware Panoramic Gaussian Opacity Fields for 3D Scene Reconstruction
Mar 09, 2026Omnidirectional images are increasingly used in robotics and vision due to their wide field of view. However, extending 3D Gaussian Splatting (3DGS) to panoramic camera models remains challenging, as existing formulations are designed for perspective projections and naive adaptations often introduce distortion and geometric inconsistencies. We present Spherical-GOF, an omnidirectional Gaussian rendering framework built upon Gaussian Opacity Fields (GOF). Unlike projection-based rasterization, Spherical-GOF performs GOF ray sampling directly on the unit sphere in spherical ray space, enabling consistent ray-Gaussian interactions for panoramic rendering. To make the spherical ray casting efficient and robust, we derive a conservative spherical bounding rule for fast ray-Gaussian culling and introduce a spherical filtering scheme that adapts Gaussian footprints to distortion-varying panoramic pixel sampling. Extensive experiments on standard panoramic benchmarks (OmniBlender and OmniPhotos) demonstrate competitive photometric quality and substantially improved geometric consistency. Compared with the strongest baseline, Spherical-GOF reduces depth reprojection error by 57% and improves cycle inlier ratio by 21%. Qualitative results show cleaner depth and more coherent normal maps, with strong robustness to global panorama rotations. We further validate generalization on OmniRob, a real-world robotic omnidirectional dataset introduced in this work, featuring UAV and quadruped platforms. The source code and the OmniRob dataset will be released at https://github.com/1170632760/Spherical-GOF.
Generative Bayesian Spectrum Cartography: Unified Reconstruction and Active Sensing via Diffusion Models
Dec 23, 2025High-fidelity spectrum cartography is pivotal for spectrum management and wireless situational awareness, yet it remains a challenging ill-posed inverse problem due to the sparsity and irregularity of observations. Furthermore, existing approaches often decouple reconstruction from sensing, lacking a principled mechanism for informative sampling. To address these limitations, this paper proposes a unified diffusion-based Bayesian framework that jointly addresses spectrum reconstruction and active sensing. We formulate the reconstruction task as a conditional generation process driven by a learned diffusion prior. Specifically, we derive tractable, closed-form posterior transition kernels for the reverse diffusion process, which enforce consistency with both linear Gaussian and non-linear quantized measurements. Leveraging the intrinsic probabilistic nature of diffusion models, we further develop an uncertainty-aware active sampling strategy. This strategy quantifies reconstruction uncertainty to adaptively guide sensing agents toward the most informative locations, thereby maximizing spectral efficiency. Extensive experiments demonstrate that the proposed framework significantly outperforms state-of-the-art interpolation, sparsity-based, and deep learning baselines in terms of reconstruction accuracy, sampling efficiency, and robustness to low-bit quantization.
Hallucinating 360°: Panoramic Street-View Generation via Local Scenes Diffusion and Probabilistic Prompting
Jul 09, 2025



Panoramic perception holds significant potential for autonomous driving, enabling vehicles to acquire a comprehensive 360{\deg} surround view in a single shot. However, autonomous driving is a data-driven task. Complete panoramic data acquisition requires complex sampling systems and annotation pipelines, which are time-consuming and labor-intensive. Although existing street view generation models have demonstrated strong data regeneration capabilities, they can only learn from the fixed data distribution of existing datasets and cannot achieve high-quality, controllable panoramic generation. In this paper, we propose the first panoramic generation method Percep360 for autonomous driving. Percep360 enables coherent generation of panoramic data with control signals based on the stitched panoramic data. Percep360 focuses on two key aspects: coherence and controllability. Specifically, to overcome the inherent information loss caused by the pinhole sampling process, we propose the Local Scenes Diffusion Method (LSDM). LSDM reformulates the panorama generation as a spatially continuous diffusion process, bridging the gaps between different data distributions. Additionally, to achieve the controllable generation of panoramic images, we propose a Probabilistic Prompting Method (PPM). PPM dynamically selects the most relevant control cues, enabling controllable panoramic image generation. We evaluate the effectiveness of the generated images from three perspectives: image quality assessment (i.e., no-reference and with reference), controllability, and their utility in real-world Bird's Eye View (BEV) segmentation. Notably, the generated data consistently outperforms the original stitched images in no-reference quality metrics and enhances downstream perception models. The source code will be publicly available at https://github.com/Bryant-Teng/Percep360.
Drift-Aware Federated Learning: A Causal Perspective
Mar 12, 2025Federated learning (FL) facilitates collaborative model training among multiple clients while preserving data privacy, often resulting in enhanced performance compared to models trained by individual clients. However, factors such as communication frequency and data distribution can contribute to feature drift, hindering the attainment of optimal training performance. This paper examine the relationship between model update drift and global as well as local optimizer from causal perspective. The influence of the global optimizer on feature drift primarily arises from the participation frequency of certain clients in server updates, whereas the effect of the local optimizer is typically associated with imbalanced data distributions.To mitigate this drift, we propose a novel framework termed Causal drift-Aware Federated lEarning (CAFE). CAFE exploits the causal relationship between feature-invariant components and classification outcomes to independently calibrate local client sample features and classifiers during the training phase. In the inference phase, it eliminated the drifts in the global model that favor frequently communicating clients.Experimental results demonstrate that CAFE's integration of feature calibration, parameter calibration, and historical information effectively reduces both drift towards majority classes and tendencies toward frequently communicating nodes.
Omnidirectional Multi-Object Tracking
Mar 06, 2025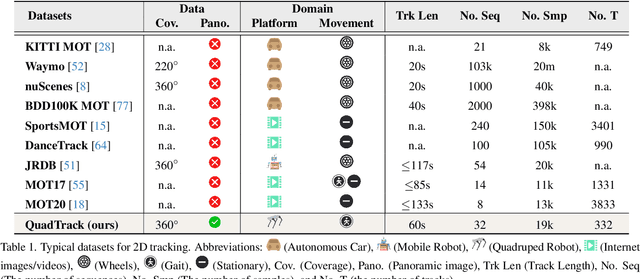
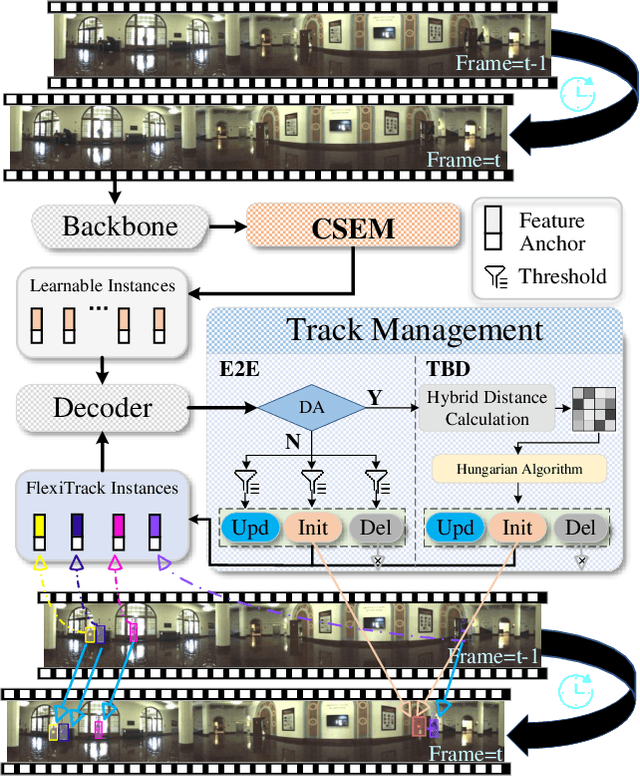
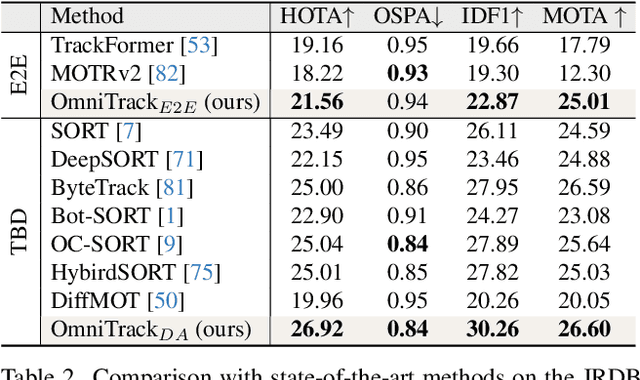
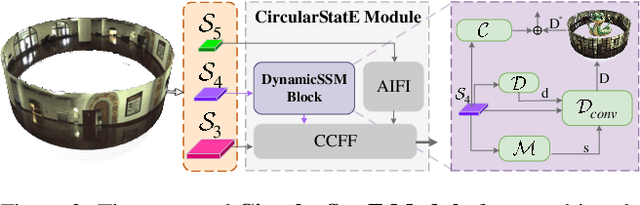
Panoramic imagery, with its 360{\deg} field of view, offers comprehensive information to support Multi-Object Tracking (MOT) in capturing spatial and temporal relationships of surrounding objects. However, most MOT algorithms are tailored for pinhole images with limited views, impairing their effectiveness in panoramic settings. Additionally, panoramic image distortions, such as resolution loss, geometric deformation, and uneven lighting, hinder direct adaptation of existing MOT methods, leading to significant performance degradation. To address these challenges, we propose OmniTrack, an omnidirectional MOT framework that incorporates Tracklet Management to introduce temporal cues, FlexiTrack Instances for object localization and association, and the CircularStatE Module to alleviate image and geometric distortions. This integration enables tracking in large field-of-view scenarios, even under rapid sensor motion. To mitigate the lack of panoramic MOT datasets, we introduce the QuadTrack dataset--a comprehensive panoramic dataset collected by a quadruped robot, featuring diverse challenges such as wide fields of view, intense motion, and complex environments. Extensive experiments on the public JRDB dataset and the newly introduced QuadTrack benchmark demonstrate the state-of-the-art performance of the proposed framework. OmniTrack achieves a HOTA score of 26.92% on JRDB, representing an improvement of 3.43%, and further achieves 23.45% on QuadTrack, surpassing the baseline by 6.81%. The dataset and code will be made publicly available at https://github.com/xifen523/OmniTrack.
Enriching Multimodal Sentiment Analysis through Textual Emotional Descriptions of Visual-Audio Content
Dec 12, 2024



Multimodal Sentiment Analysis (MSA) stands as a critical research frontier, seeking to comprehensively unravel human emotions by amalgamating text, audio, and visual data. Yet, discerning subtle emotional nuances within audio and video expressions poses a formidable challenge, particularly when emotional polarities across various segments appear similar. In this paper, our objective is to spotlight emotion-relevant attributes of audio and visual modalities to facilitate multimodal fusion in the context of nuanced emotional shifts in visual-audio scenarios. To this end, we introduce DEVA, a progressive fusion framework founded on textual sentiment descriptions aimed at accentuating emotional features of visual-audio content. DEVA employs an Emotional Description Generator (EDG) to transmute raw audio and visual data into textualized sentiment descriptions, thereby amplifying their emotional characteristics. These descriptions are then integrated with the source data to yield richer, enhanced features. Furthermore, DEVA incorporates the Text-guided Progressive Fusion Module (TPF), leveraging varying levels of text as a core modality guide. This module progressively fuses visual-audio minor modalities to alleviate disparities between text and visual-audio modalities. Experimental results on widely used sentiment analysis benchmark datasets, including MOSI, MOSEI, and CH-SIMS, underscore significant enhancements compared to state-of-the-art models. Moreover, fine-grained emotion experiments corroborate the robust sensitivity of DEVA to subtle emotional variations.
Channel-Adaptive Wireless Image Semantic Transmission with Learnable Prompts
Nov 15, 2024



Recent developments in Deep learning based Joint Source-Channel Coding (DeepJSCC) have demonstrated impressive capabilities within wireless semantic communications system. However, existing DeepJSCC methodologies exhibit limited generalization ability across varying channel conditions, necessitating the preparation of multiple models. Optimal performance is only attained when the channel status during testing aligns precisely with the training channel status, which is very inconvenient for real-life applications. In this paper, we introduce a novel DeepJSCC framework, termed Prompt JSCC (PJSCC), which incorporates a learnable prompt to implicitly integrate the physical channel state into the transmission system. Specifically, the Channel State Prompt (CSP) module is devised to generate prompts based on diverse SNR and channel distribution models. Through the interaction of latent image features with channel features derived from the CSP module, the DeepJSCC process dynamically adapts to varying channel conditions without necessitating retraining. Comparative analyses against leading DeepJSCC methodologies and traditional separate coding approaches reveal that the proposed PJSCC achieves optimal image reconstruction performance across different SNR settings and various channel models, as assessed by Peak Signal-to-Noise Ratio (PSNR) and Learning-based Perceptual Image Patch Similarity (LPIPS) metrics. Furthermore, in real-world scenarios, PJSCC shows excellent memory efficiency and scalability, rendering it readily deployable on resource-constrained platforms to facilitate semantic communications.
DecomCAM: Advancing Beyond Saliency Maps through Decomposition and Integration
May 29, 2024Interpreting complex deep networks, notably pre-trained vision-language models (VLMs), is a formidable challenge. Current Class Activation Map (CAM) methods highlight regions revealing the model's decision-making basis but lack clear saliency maps and detailed interpretability. To bridge this gap, we propose DecomCAM, a novel decomposition-and-integration method that distills shared patterns from channel activation maps. Utilizing singular value decomposition, DecomCAM decomposes class-discriminative activation maps into orthogonal sub-saliency maps (OSSMs), which are then integrated together based on their contribution to the target concept. Extensive experiments on six benchmarks reveal that DecomCAM not only excels in locating accuracy but also achieves an optimizing balance between interpretability and computational efficiency. Further analysis unveils that OSSMs correlate with discernible object components, facilitating a granular understanding of the model's reasoning. This positions DecomCAM as a potential tool for fine-grained interpretation of advanced deep learning models. The code is avaible at https://github.com/CapricornGuang/DecomCAM.
A2CI: A Cloud-based, Service-oriented Geospatial Cyberinfrastructure to Support Atmospheric Research
Mar 15, 2024Big earth science data offers the scientific community great opportunities. Many more studies at large-scales, over long-terms and at high resolution can now be conducted using the rich information collected by remote sensing satellites, ground-based sensor networks, and even social media input. However, the hundreds of terabytes of information collected and compiled on an hourly basis by NASA and other government agencies present a significant challenge for atmospheric scientists seeking to improve the understanding of the Earth atmospheric system. These challenges include effective discovery, organization, analysis and visualization of large amounts of data. This paper reports the outcomes of an NSF-funded project that developed a geospatial cyberinfrastructure -- the A2CI (Atmospheric Analysis Cyberinfrastructure) -- to support atmospheric research. We first introduce the service-oriented system framework then describe in detail the implementation of the data discovery module, data management module, data integration module, data analysis and visualization modules following the cloud computing principles-Data-as-a-Service, Software-as-a-Service, Platform-as-a-Service and Infrastructure-as-a-Service. We demonstrate the graphic user interface by performing an analysis between Sea Surface Temperature and the intensity of tropical storms in the North Atlantic and Pacific oceans. We expect this work to contribute to the technical advancement of cyberinfrastructure research as well as to the development of an online, collaborative scientific analysis system for atmospheric science.