 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgefacial
Papers and Code
CLIP-FTI: Fine-Grained Face Template Inversion via CLIP-Driven Attribute Conditioning
Dec 17, 2025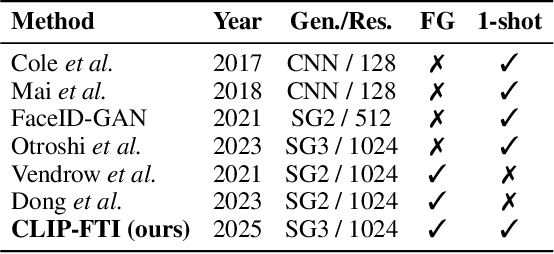
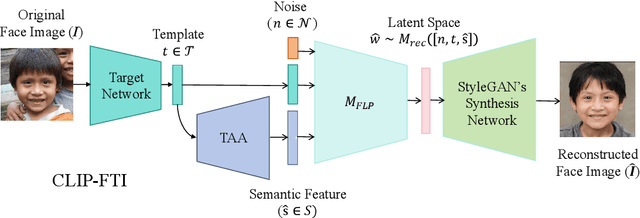
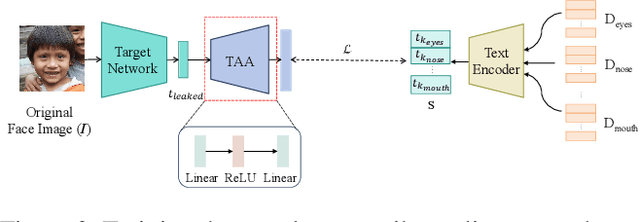
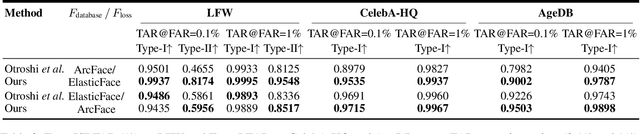
Face recognition systems store face templates for efficient matching. Once leaked, these templates pose a threat: inverting them can yield photorealistic surrogates that compromise privacy and enable impersonation. Although existing research has achieved relatively realistic face template inversion, the reconstructed facial images exhibit over-smoothed facial-part attributes (eyes, nose, mouth) and limited transferability. To address this problem, we present CLIP-FTI, a CLIP-driven fine-grained attribute conditioning framework for face template inversion. Our core idea is to use the CLIP model to obtain the semantic embeddings of facial features, in order to realize the reconstruction of specific facial feature attributes. Specifically, facial feature attribute embeddings extracted from CLIP are fused with the leaked template via a cross-modal feature interaction network and projected into the intermediate latent space of a pretrained StyleGAN. The StyleGAN generator then synthesizes face images with the same identity as the templates but with more fine-grained facial feature attributes. Experiments across multiple face recognition backbones and datasets show that our reconstructions (i) achieve higher identification accuracy and attribute similarity, (ii) recover sharper component-level attribute semantics, and (iii) improve cross-model attack transferability compared to prior reconstruction attacks. To the best of our knowledge, ours is the first method to use additional information besides the face template attack to realize face template inversion and obtains SOTA results.
Gaussian Pixel Codec Avatars: A Hybrid Representation for Efficient Rendering
Dec 17, 2025We present Gaussian Pixel Codec Avatars (GPiCA), photorealistic head avatars that can be generated from multi-view images and efficiently rendered on mobile devices. GPiCA utilizes a unique hybrid representation that combines a triangle mesh and anisotropic 3D Gaussians. This combination maximizes memory and rendering efficiency while maintaining a photorealistic appearance. The triangle mesh is highly efficient in representing surface areas like facial skin, while the 3D Gaussians effectively handle non-surface areas such as hair and beard. To this end, we develop a unified differentiable rendering pipeline that treats the mesh as a semi-transparent layer within the volumetric rendering paradigm of 3D Gaussian Splatting. We train neural networks to decode a facial expression code into three components: a 3D face mesh, an RGBA texture, and a set of 3D Gaussians. These components are rendered simultaneously in a unified rendering engine. The networks are trained using multi-view image supervision. Our results demonstrate that GPiCA achieves the realism of purely Gaussian-based avatars while matching the rendering performance of mesh-based avatars.
POLAR: A Portrait OLAT Dataset and Generative Framework for Illumination-Aware Face Modeling
Dec 16, 2025Face relighting aims to synthesize realistic portraits under novel illumination while preserving identity and geometry. However, progress remains constrained by the limited availability of large-scale, physically consistent illumination data. To address this, we introduce POLAR, a large-scale and physically calibrated One-Light-at-a-Time (OLAT) dataset containing over 200 subjects captured under 156 lighting directions, multiple views, and diverse expressions. Building upon POLAR, we develop a flow-based generative model POLARNet that predicts per-light OLAT responses from a single portrait, capturing fine-grained and direction-aware illumination effects while preserving facial identity. Unlike diffusion or background-conditioned methods that rely on statistical or contextual cues, our formulation models illumination as a continuous, physically interpretable transformation between lighting states, enabling scalable and controllable relighting. Together, POLAR and POLARNet form a unified illumination learning framework that links real data, generative synthesis, and physically grounded relighting, establishing a self-sustaining "chicken-and-egg" cycle for scalable and reproducible portrait illumination. Our project page: https://rex0191.github.io/POLAR/.
FacEDiT: Unified Talking Face Editing and Generation via Facial Motion Infilling
Dec 16, 2025



Talking face editing and face generation have often been studied as distinct problems. In this work, we propose viewing both not as separate tasks but as subtasks of a unifying formulation, speech-conditional facial motion infilling. We explore facial motion infilling as a self-supervised pretext task that also serves as a unifying formulation of dynamic talking face synthesis. To instantiate this idea, we propose FacEDiT, a speech-conditional Diffusion Transformer trained with flow matching. Inspired by masked autoencoders, FacEDiT learns to synthesize masked facial motions conditioned on surrounding motions and speech. This formulation enables both localized generation and edits, such as substitution, insertion, and deletion, while ensuring seamless transitions with unedited regions. In addition, biased attention and temporal smoothness constraints enhance boundary continuity and lip synchronization. To address the lack of a standard editing benchmark, we introduce FacEDiTBench, the first dataset for talking face editing, featuring diverse edit types and lengths, along with new evaluation metrics. Extensive experiments validate that talking face editing and generation emerge as subtasks of speech-conditional motion infilling; FacEDiT produces accurate, speech-aligned facial edits with strong identity preservation and smooth visual continuity while generalizing effectively to talking face generation.
Impact of Robot Facial-Audio Expressions on Human Robot Trust Dynamics and Trust Repair
Dec 16, 2025



Despite recent advances in robotics and human-robot collaboration in the AEC industry, trust has mostly been treated as a static factor, with little guidance on how it changes across events during collaboration. This paper investigates how a robot's task performance and its expressive responses after outcomes shape the dynamics of human trust over time. To this end, we designed a controlled within-subjects study with two construction-inspired tasks, Material Delivery (physical assistance) and Information Gathering (perceptual assistance), and measured trust repeatedly (four times per task) using the 14-item Trust Perception Scale for HRI plus a redelegation choice. The robot produced two multimodal expressions, a "glad" display with a brief confirmation after success, and a "sad" display with an apology and a request for a second chance after failure. The study was conducted in a lab environment with 30 participants and a quadruped platform, and we evaluated trust dynamics and repair across both tasks. Results show that robot success reliably increases trust, failure causes sharp drops, and apology-based expressions partially restores trust (44% recovery in Material Delivery; 38% in Information Gathering). Item-level analysis indicates that recovered trust was driven mostly by interaction and communication factors, with competence recovering partially and autonomy aspects changing least. Additionally, age group and prior attitudes moderated trust dynamics with younger participants showed larger but shorter-lived changes, mid-20s participants exhibited the most durable repair, and older participants showed most conservative dynamics. This work provides a foundation for future efforts that adapt repair strategies to task demands and user profiles to support safe, productive adoption of robots on construction sites.
ViBES: A Conversational Agent with Behaviorally-Intelligent 3D Virtual Body
Dec 16, 2025



Human communication is inherently multimodal and social: words, prosody, and body language jointly carry intent. Yet most prior systems model human behavior as a translation task co-speech gesture or text-to-motion that maps a fixed utterance to motion clips-without requiring agentic decision-making about when to move, what to do, or how to adapt across multi-turn dialogue. This leads to brittle timing, weak social grounding, and fragmented stacks where speech, text, and motion are trained or inferred in isolation. We introduce ViBES (Voice in Behavioral Expression and Synchrony), a conversational 3D agent that jointly plans language and movement and executes dialogue-conditioned body actions. Concretely, ViBES is a speech-language-behavior (SLB) model with a mixture-of-modality-experts (MoME) backbone: modality-partitioned transformer experts for speech, facial expression, and body motion. The model processes interleaved multimodal token streams with hard routing by modality (parameters are split per expert), while sharing information through cross-expert attention. By leveraging strong pretrained speech-language models, the agent supports mixed-initiative interaction: users can speak, type, or issue body-action directives mid-conversation, and the system exposes controllable behavior hooks for streaming responses. We further benchmark on multi-turn conversation with automatic metrics of dialogue-motion alignment and behavior quality, and observe consistent gains over strong co-speech and text-to-motion baselines. ViBES goes beyond "speech-conditioned motion generation" toward agentic virtual bodies where language, prosody, and movement are jointly generated, enabling controllable, socially competent 3D interaction. Code and data will be made available at: ai.stanford.edu/~juze/ViBES/
Quality-Aware Framework for Video-Derived Respiratory Signals
Dec 16, 2025



Video-based respiratory rate (RR) estimation is often unreliable due to inconsistent signal quality across extraction methods. We present a predictive, quality-aware framework that integrates heterogeneous signal sources with dynamic assessment of reliability. Ten signals are extracted from facial remote photoplethysmography (rPPG), upper-body motion, and deep learning pipelines, and analyzed using four spectral estimators: Welch's method, Multiple Signal Classification (MUSIC), Fast Fourier Transform (FFT), and peak detection. Segment-level quality indices are then used to train machine learning models that predict accuracy or select the most reliable signal. This enables adaptive signal fusion and quality-based segment filtering. Experiments on three public datasets (OMuSense-23, COHFACE, MAHNOB-HCI) show that the proposed framework achieves lower RR estimation errors than individual methods in most cases, with performance gains depending on dataset characteristics. These findings highlight the potential of quality-driven predictive modeling to deliver scalable and generalizable video-based respiratory monitoring solutions.
USTM: Unified Spatial and Temporal Modeling for Continuous Sign Language Recognition
Dec 15, 2025Continuous sign language recognition (CSLR) requires precise spatio-temporal modeling to accurately recognize sequences of gestures in videos. Existing frameworks often rely on CNN-based spatial backbones combined with temporal convolution or recurrent modules. These techniques fail in capturing fine-grained hand and facial cues and modeling long-range temporal dependencies. To address these limitations, we propose the Unified Spatio-Temporal Modeling (USTM) framework, a spatio-temporal encoder that effectively models complex patterns using a combination of a Swin Transformer backbone enhanced with lightweight temporal adapter with positional embeddings (TAPE). Our framework captures fine-grained spatial features alongside short and long-term temporal context, enabling robust sign language recognition from RGB videos without relying on multi-stream inputs or auxiliary modalities. Extensive experiments on benchmarked datasets including PHOENIX14, PHOENIX14T, and CSL-Daily demonstrate that USTM achieves state-of-the-art performance against RGB-based as well as multi-modal CSLR approaches, while maintaining competitive performance against multi-stream approaches. These results highlight the strength and efficacy of the USTM framework for CSLR. The code is available at https://github.com/gufranSabri/USTM
JoVA: Unified Multimodal Learning for Joint Video-Audio Generation
Dec 15, 2025In this paper, we present JoVA, a unified framework for joint video-audio generation. Despite recent encouraging advances, existing methods face two critical limitations. First, most existing approaches can only generate ambient sounds and lack the capability to produce human speech synchronized with lip movements. Second, recent attempts at unified human video-audio generation typically rely on explicit fusion or modality-specific alignment modules, which introduce additional architecture design and weaken the model simplicity of the original transformers. To address these issues, JoVA employs joint self-attention across video and audio tokens within each transformer layer, enabling direct and efficient cross-modal interaction without the need for additional alignment modules. Furthermore, to enable high-quality lip-speech synchronization, we introduce a simple yet effective mouth-area loss based on facial keypoint detection, which enhances supervision on the critical mouth region during training without compromising architectural simplicity. Extensive experiments on benchmarks demonstrate that JoVA outperforms or is competitive with both unified and audio-driven state-of-the-art methods in lip-sync accuracy, speech quality, and overall video-audio generation fidelity. Our results establish JoVA as an elegant framework for high-quality multimodal generation.
Soul: Breathe Life into Digital Human for High-fidelity Long-term Multimodal Animation
Dec 15, 2025We propose a multimodal-driven framework for high-fidelity long-term digital human animation termed $\textbf{Soul}$, which generates semantically coherent videos from a single-frame portrait image, text prompts, and audio, achieving precise lip synchronization, vivid facial expressions, and robust identity preservation. We construct Soul-1M, containing 1 million finely annotated samples with a precise automated annotation pipeline (covering portrait, upper-body, full-body, and multi-person scenes) to mitigate data scarcity, and we carefully curate Soul-Bench for comprehensive and fair evaluation of audio-/text-guided animation methods. The model is built on the Wan2.2-5B backbone, integrating audio-injection layers and multiple training strategies together with threshold-aware codebook replacement to ensure long-term generation consistency. Meanwhile, step/CFG distillation and a lightweight VAE are used to optimize inference efficiency, achieving an 11.4$\times$ speedup with negligible quality loss. Extensive experiments show that Soul significantly outperforms current leading open-source and commercial models on video quality, video-text alignment, identity preservation, and lip-synchronization accuracy, demonstrating broad applicability in real-world scenarios such as virtual anchors and film production. Project page at https://zhangzjn.github.io/projects/Soul/