 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLBFTI: Layer-Based Facial Template Inversion for Identity-Preserving Fine-Grained Face Reconstruction
Apr 20, 2026In face recognition systems, facial templates are widely adopted for identity authentication due to their compliance with the data minimization principle. However, facial template inversion technologies have posed a severe privacy leakage risk by enabling face reconstruction from templates. This paper proposes a Layer-Based Facial Template Inversion (LBFTI) method to reconstruct identity-preserving fine-grained face images. Our scheme decomposes face images into three layers: foreground layers (including eyebrows, eyes, nose, and mouth), midground layers (skin), and background layers (other parts). LBFTI leverages dedicated generators to produce these layers, adopting a rigorous three-stage training strategy: (1) independent refined generation of foreground and midground layers, (2) fusion of foreground and midground layers with template secondary injection to produce complete panoramic face images with background layers, and (3) joint fine-tuning of all modules to optimize inter-layer coordination and identity consistency. Experiments demonstrate that our LBFTI not only outperforms state-of-the-art methods in machine authentication performance, with a 25.3% improvement in TAR, but also achieves better similarity in human perception, as validated by both quantitative metrics and a questionnaire survey.
CLIP-FTI: Fine-Grained Face Template Inversion via CLIP-Driven Attribute Conditioning
Dec 17, 2025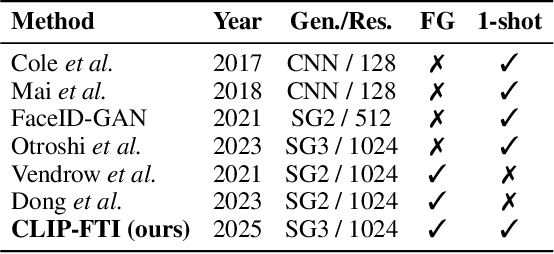
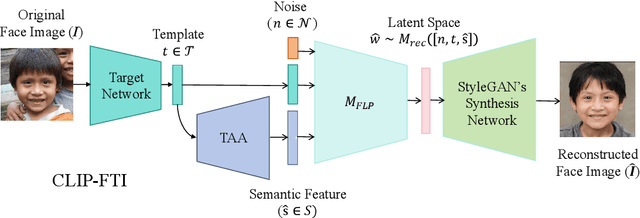
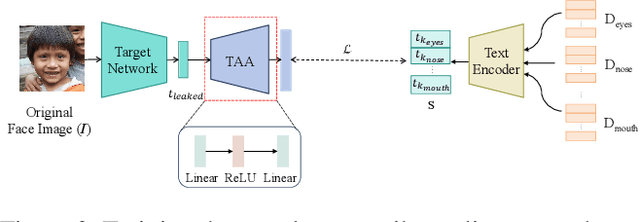
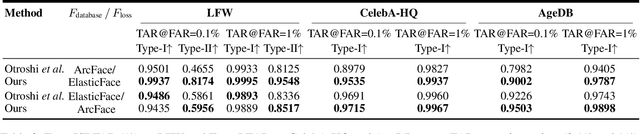
Face recognition systems store face templates for efficient matching. Once leaked, these templates pose a threat: inverting them can yield photorealistic surrogates that compromise privacy and enable impersonation. Although existing research has achieved relatively realistic face template inversion, the reconstructed facial images exhibit over-smoothed facial-part attributes (eyes, nose, mouth) and limited transferability. To address this problem, we present CLIP-FTI, a CLIP-driven fine-grained attribute conditioning framework for face template inversion. Our core idea is to use the CLIP model to obtain the semantic embeddings of facial features, in order to realize the reconstruction of specific facial feature attributes. Specifically, facial feature attribute embeddings extracted from CLIP are fused with the leaked template via a cross-modal feature interaction network and projected into the intermediate latent space of a pretrained StyleGAN. The StyleGAN generator then synthesizes face images with the same identity as the templates but with more fine-grained facial feature attributes. Experiments across multiple face recognition backbones and datasets show that our reconstructions (i) achieve higher identification accuracy and attribute similarity, (ii) recover sharper component-level attribute semantics, and (iii) improve cross-model attack transferability compared to prior reconstruction attacks. To the best of our knowledge, ours is the first method to use additional information besides the face template attack to realize face template inversion and obtains SOTA results.
Audio-FLAN: A Preliminary Release
Feb 23, 2025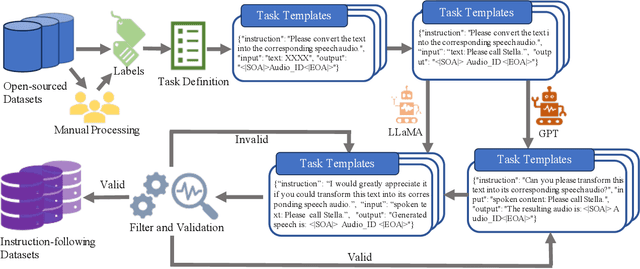

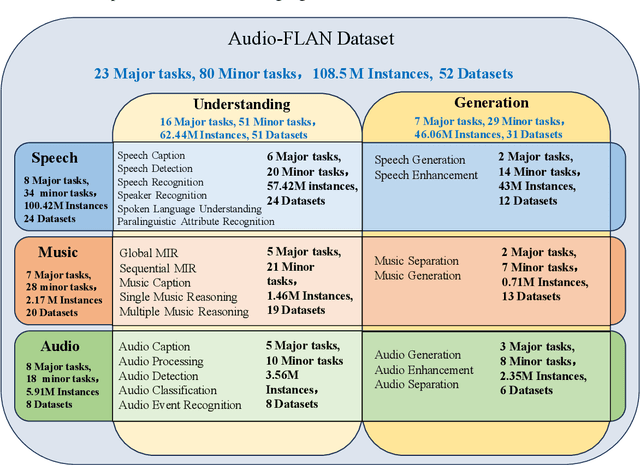

Recent advancements in audio tokenization have significantly enhanced the integration of audio capabilities into large language models (LLMs). However, audio understanding and generation are often treated as distinct tasks, hindering the development of truly unified audio-language models. While instruction tuning has demonstrated remarkable success in improving generalization and zero-shot learning across text and vision, its application to audio remains largely unexplored. A major obstacle is the lack of comprehensive datasets that unify audio understanding and generation. To address this, we introduce Audio-FLAN, a large-scale instruction-tuning dataset covering 80 diverse tasks across speech, music, and sound domains, with over 100 million instances. Audio-FLAN lays the foundation for unified audio-language models that can seamlessly handle both understanding (e.g., transcription, comprehension) and generation (e.g., speech, music, sound) tasks across a wide range of audio domains in a zero-shot manner. The Audio-FLAN dataset is available on HuggingFace and GitHub and will be continuously updated.