 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP-FTI: Fine-Grained Face Template Inversion via CLIP-Driven Attribute Conditioning
Dec 17, 2025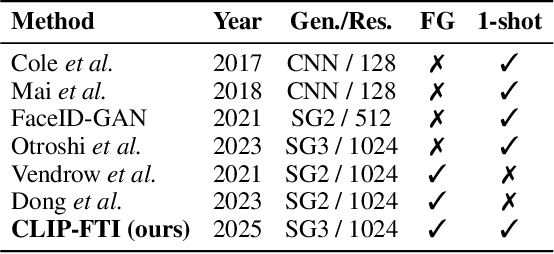
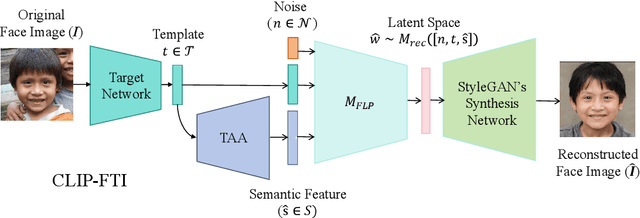
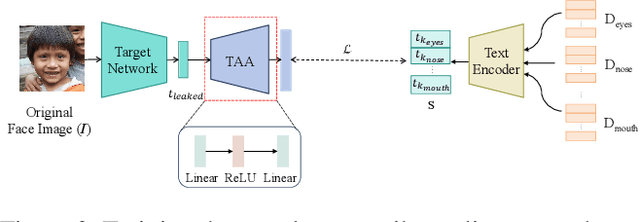
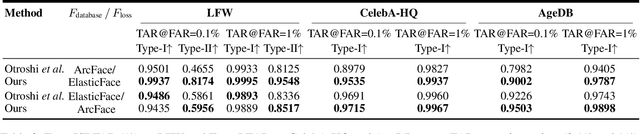
Face recognition systems store face templates for efficient matching. Once leaked, these templates pose a threat: inverting them can yield photorealistic surrogates that compromise privacy and enable impersonation. Although existing research has achieved relatively realistic face template inversion, the reconstructed facial images exhibit over-smoothed facial-part attributes (eyes, nose, mouth) and limited transferability. To address this problem, we present CLIP-FTI, a CLIP-driven fine-grained attribute conditioning framework for face template inversion. Our core idea is to use the CLIP model to obtain the semantic embeddings of facial features, in order to realize the reconstruction of specific facial feature attributes. Specifically, facial feature attribute embeddings extracted from CLIP are fused with the leaked template via a cross-modal feature interaction network and projected into the intermediate latent space of a pretrained StyleGAN. The StyleGAN generator then synthesizes face images with the same identity as the templates but with more fine-grained facial feature attributes. Experiments across multiple face recognition backbones and datasets show that our reconstructions (i) achieve higher identification accuracy and attribute similarity, (ii) recover sharper component-level attribute semantics, and (iii) improve cross-model attack transferability compared to prior reconstruction attacks. To the best of our knowledge, ours is the first method to use additional information besides the face template attack to realize face template inversion and obtains SOTA results.
Fine-Grained DINO Tuning with Dual Supervision for Face Forgery Detection
Nov 15, 2025The proliferation of sophisticated deepfakes poses significant threats to information integrity. While DINOv2 shows promise for detection, existing fine-tuning approaches treat it as generic binary classification, overlooking distinct artifacts inherent to different deepfake methods. To address this, we propose a DeepFake Fine-Grained Adapter (DFF-Adapter) for DINOv2. Our method incorporates lightweight multi-head LoRA modules into every transformer block, enabling efficient backbone adaptation. DFF-Adapter simultaneously addresses authenticity detection and fine-grained manipulation type classification, where classifying forgery methods enhances artifact sensitivity. We introduce a shared branch propagating fine-grained manipulation cues to the authenticity head. This enables multi-task cooperative optimization, explicitly enhancing authenticity discrimination with manipulation-specific knowledge. Utilizing only 3.5M trainable parameters, our parameter-efficient approach achieves detection accuracy comparable to or even surpassing that of current complex state-of-the-art methods.