 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParaSpeechCLAP: A Dual-Encoder Speech-Text Model for Rich Stylistic Language-Audio Pretraining
Mar 30, 2026We introduce ParaSpeechCLAP, a dual-encoder contrastive model that maps speech and text style captions into a common embedding space, supporting a wide range of intrinsic (speaker-level) and situational (utterance-level) descriptors (such as pitch, texture and emotion) far beyond the narrow set handled by existing models. We train specialized ParaSpeechCLAP-Intrinsic and ParaSpeechCLAP-Situational models alongside a unified ParaSpeechCLAP-Combined model, finding that specialization yields stronger performance on individual style dimensions while the unified model excels on compositional evaluation. We further show that ParaSpeechCLAP-Intrinsic benefits from an additional classification loss and class-balanced training. We demonstrate our models' performance on style caption retrieval, speech attribute classification and as an inference-time reward model that improves style-prompted TTS without additional training. ParaSpeechCLAP outperforms baselines on most metrics across all three applications. Our models and code are released at https://github.com/ajd12342/paraspeechclap .
Adapting Self-Supervised Speech Representations for Cross-lingual Dysarthria Detection in Parkinson's Disease
Mar 23, 2026The limited availability of dysarthric speech data makes cross-lingual detection an important but challenging problem. A key difficulty is that speech representations often encode language-dependent structure that can confound dysarthria detection. We propose a representation-level language shift (LS) that aligns source-language self-supervised speech representations with the target-language distribution using centroid-based vector adaptation estimated from healthy-control speech. We evaluate the approach on oral DDK recordings from Parkinson's disease speech datasets in Czech, German, and Spanish under both cross-lingual and multilingual settings. LS substantially improves sensitivity and F1 in cross-lingual settings, while yielding smaller but consistent gains in multilingual settings. Representation analysis further shows that LS reduces language identity in the embedding space, supporting the interpretation that LS removes language-dependent structure.
Self-Supervised Speech Models Encode Phonetic Context via Position-dependent Orthogonal Subspaces
Mar 13, 2026Transformer-based self-supervised speech models (S3Ms) are often described as contextualized, yet what this entails remains unclear. Here, we focus on how a single frame-level S3M representation can encode phones and their surrounding context. Prior work has shown that S3Ms represent phones compositionally; for example, phonological vectors such as voicing, bilabiality, and nasality vectors are superposed in the S3M representation of [m]. We extend this view by proposing that phonological information from a sequence of neighboring phones is also compositionally encoded in a single frame, such that vectors corresponding to previous, current, and next phones are superposed within a single frame-level representation. We show that this structure has several properties, including orthogonality between relative positions, and emergence of implicit phonetic boundaries. Together, our findings advance our understanding of context-dependent S3M representations.
Linear Script Representations in Speech Foundation Models Enable Zero-Shot Transliteration
Jan 06, 2026Multilingual speech foundation models such as Whisper are trained on web-scale data, where data for each language consists of a myriad of regional varieties. However, different regional varieties often employ different scripts to write the same language, rendering speech recognition output also subject to non-determinism in the output script. To mitigate this problem, we show that script is linearly encoded in the activation space of multilingual speech models, and that modifying activations at inference time enables direct control over output script. We find the addition of such script vectors to activations at test time can induce script change even in unconventional language-script pairings (e.g. Italian in Cyrillic and Japanese in Latin script). We apply this approach to inducing post-hoc control over the script of speech recognition output, where we observe competitive performance across all model sizes of Whisper.
FacEDiT: Unified Talking Face Editing and Generation via Facial Motion Infilling
Dec 16, 2025



Talking face editing and face generation have often been studied as distinct problems. In this work, we propose viewing both not as separate tasks but as subtasks of a unifying formulation, speech-conditional facial motion infilling. We explore facial motion infilling as a self-supervised pretext task that also serves as a unifying formulation of dynamic talking face synthesis. To instantiate this idea, we propose FacEDiT, a speech-conditional Diffusion Transformer trained with flow matching. Inspired by masked autoencoders, FacEDiT learns to synthesize masked facial motions conditioned on surrounding motions and speech. This formulation enables both localized generation and edits, such as substitution, insertion, and deletion, while ensuring seamless transitions with unedited regions. In addition, biased attention and temporal smoothness constraints enhance boundary continuity and lip synchronization. To address the lack of a standard editing benchmark, we introduce FacEDiTBench, the first dataset for talking face editing, featuring diverse edit types and lengths, along with new evaluation metrics. Extensive experiments validate that talking face editing and generation emerge as subtasks of speech-conditional motion infilling; FacEDiT produces accurate, speech-aligned facial edits with strong identity preservation and smooth visual continuity while generalizing effectively to talking face generation.
VoiceCraft-X: Unifying Multilingual, Voice-Cloning Speech Synthesis and Speech Editing
Nov 15, 2025We introduce VoiceCraft-X, an autoregressive neural codec language model which unifies multilingual speech editing and zero-shot Text-to-Speech (TTS) synthesis across 11 languages: English, Mandarin, Korean, Japanese, Spanish, French, German, Dutch, Italian, Portuguese, and Polish. VoiceCraft-X utilizes the Qwen3 large language model for phoneme-free cross-lingual text processing and a novel token reordering mechanism with time-aligned text and speech tokens to handle both tasks as a single sequence generation problem. The model generates high-quality, natural-sounding speech, seamlessly creating new audio or editing existing recordings within one framework. VoiceCraft-X shows robust performance in diverse linguistic settings, even with limited per-language data, underscoring the power of unified autoregressive approaches for advancing complex, real-world multilingual speech applications. Audio samples are available at https://zhishengzheng.com/voicecraft-x/.
Unifying Model and Layer Fusion for Speech Foundation Models
Nov 11, 2025
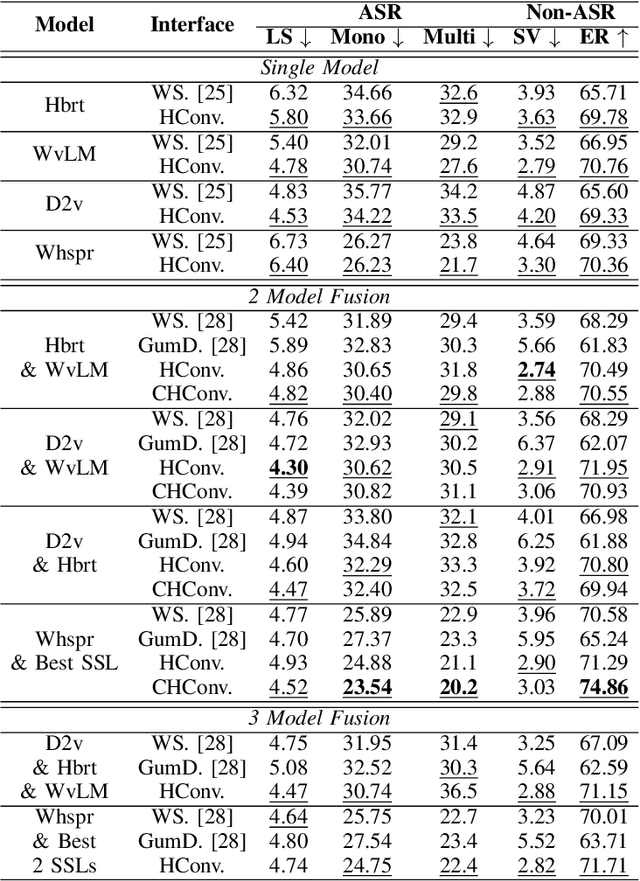
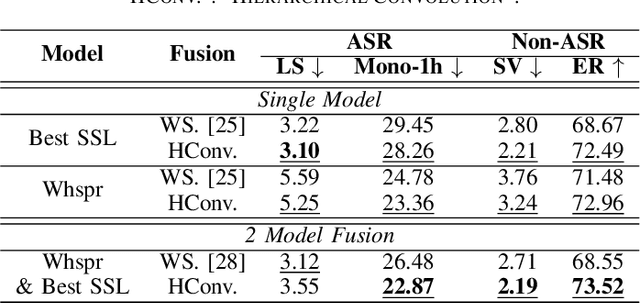
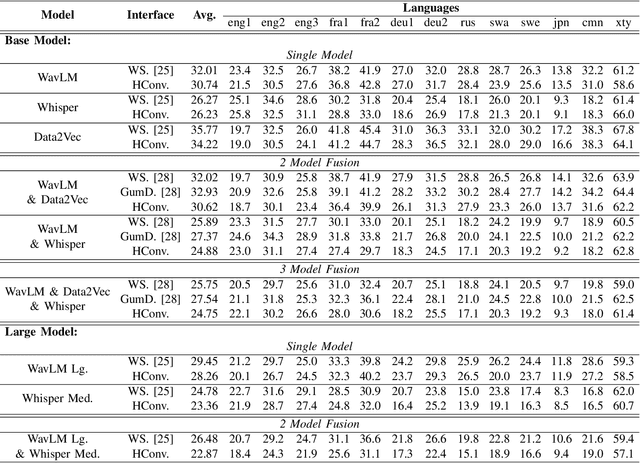
Speech Foundation Models have gained significant attention recently. Prior works have shown that the fusion of representations from multiple layers of the same model or the fusion of multiple models can improve performance on downstream tasks. We unify these two fusion strategies by proposing an interface module that enables fusion across multiple upstream speech models while integrating information across their layers. We conduct extensive experiments on different self-supervised and supervised models across various speech tasks, including ASR and paralinguistic analysis, and demonstrate that our method outperforms prior fusion approaches. We further analyze its scalability concerning model size and count, highlighting the importance of selecting appropriate upstream models. Our results show that the proposed interface provides an additional performance boost when given a suitable upstream model selection, making it a promising approach for utilizing Speech Foundation Models.
Probing the Robustness Properties of Neural Speech Codecs
May 30, 2025Neural speech codecs have revolutionized speech coding, achieving higher compression while preserving audio fidelity. Beyond compression, they have emerged as tokenization strategies, enabling language modeling on speech and driving paradigm shifts across various speech processing tasks. Despite these advancements, their robustness in noisy environments remains underexplored, raising concerns about their generalization to real-world scenarios. In this work, we systematically evaluate neural speech codecs under various noise conditions, revealing non-trivial differences in their robustness. We further examine their linearity properties, uncovering non-linear distortions which partly explain observed variations in robustness. Lastly, we analyze their frequency response to identify factors affecting audio fidelity. Our findings provide critical insights into codec behavior and future codec design, as well as emphasizing the importance of noise robustness for their real-world integration.
VoiceStar: Robust Zero-Shot Autoregressive TTS with Duration Control and Extrapolation
May 26, 2025We present VoiceStar, the first zero-shot TTS model that achieves both output duration control and extrapolation. VoiceStar is an autoregressive encoder-decoder neural codec language model, that leverages a novel Progress-Monitoring Rotary Position Embedding (PM-RoPE) and is trained with Continuation-Prompt Mixed (CPM) training. PM-RoPE enables the model to better align text and speech tokens, indicates the target duration for the generated speech, and also allows the model to generate speech waveforms much longer in duration than those seen during. CPM training also helps to mitigate the training/inference mismatch, and significantly improves the quality of the generated speech in terms of speaker similarity and intelligibility. VoiceStar outperforms or is on par with current state-of-the-art models on short-form benchmarks such as Librispeech and Seed-TTS, and significantly outperforms these models on long-form/extrapolation benchmarks (20-50s) in terms of intelligibility and naturalness. Code and model weights: https://github.com/jasonppy/VoiceStar
Rhapsody: A Dataset for Highlight Detection in Podcasts
May 26, 2025Podcasts have become daily companions for half a billion users. Given the enormous amount of podcast content available, highlights provide a valuable signal that helps viewers get the gist of an episode and decide if they want to invest in listening to it in its entirety. However, identifying highlights automatically is challenging due to the unstructured and long-form nature of the content. We introduce Rhapsody, a dataset of 13K podcast episodes paired with segment-level highlight scores derived from YouTube's 'most replayed' feature. We frame the podcast highlight detection as a segment-level binary classification task. We explore various baseline approaches, including zero-shot prompting of language models and lightweight finetuned language models using segment-level classification heads. Our experimental results indicate that even state-of-the-art language models like GPT-4o and Gemini struggle with this task, while models finetuned with in-domain data significantly outperform their zero-shot performance. The finetuned model benefits from leveraging both speech signal features and transcripts. These findings highlight the challenges for fine-grained information access in long-form spoken media.