 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Softmax Loss
Papers and Code
AD-SAM: Fine-Tuning the Segment Anything Vision Foundation Model for Autonomous Driving Perception
Oct 30, 2025This paper presents the Autonomous Driving Segment Anything Model (AD-SAM), a fine-tuned vision foundation model for semantic segmentation in autonomous driving (AD). AD-SAM extends the Segment Anything Model (SAM) with a dual-encoder and deformable decoder tailored to spatial and geometric complexity of road scenes. The dual-encoder produces multi-scale fused representations by combining global semantic context from SAM's pretrained Vision Transformer (ViT-H) with local spatial detail from a trainable convolutional deep learning backbone (i.e., ResNet-50). A deformable fusion module aligns heterogeneous features across scales and object geometries. The decoder performs progressive multi-stage refinement using deformable attention. Training is guided by a hybrid loss that integrates Focal, Dice, Lovasz-Softmax, and Surface losses, improving semantic class balance, boundary precision, and optimization stability. Experiments on the Cityscapes and Berkeley DeepDrive 100K (BDD100K) benchmarks show that AD-SAM surpasses SAM, Generalized SAM (G-SAM), and a deep learning baseline (DeepLabV3) in segmentation accuracy. It achieves 68.1 mean Intersection over Union (mIoU) on Cityscapes and 59.5 mIoU on BDD100K, outperforming SAM, G-SAM, and DeepLabV3 by margins of up to +22.9 and +19.2 mIoU in structured and diverse road scenes, respectively. AD-SAM demonstrates strong cross-domain generalization with a 0.87 retention score (vs. 0.76 for SAM), and faster, more stable learning dynamics, converging within 30-40 epochs, enjoying double the learning speed of benchmark models. It maintains 0.607 mIoU with only 1000 samples, suggesting data efficiency critical for reducing annotation costs. These results confirm that targeted architectural and optimization enhancements to foundation models enable reliable and scalable AD perception.
Constrained Entropic Unlearning: A Primal-Dual Framework for Large Language Models
Jun 05, 2025Large Language Models (LLMs) deployed in real-world settings increasingly face the need to unlearn sensitive, outdated, or proprietary information. Existing unlearning methods typically formulate forgetting and retention as a regularized trade-off, combining both objectives into a single scalarized loss. This often leads to unstable optimization and degraded performance on retained data, especially under aggressive forgetting. We propose a new formulation of LLM unlearning as a constrained optimization problem: forgetting is enforced via a novel logit-margin flattening loss that explicitly drives the output distribution toward uniformity on a designated forget set, while retention is preserved through a hard constraint on a separate retain set. Compared to entropy-based objectives, our loss is softmax-free, numerically stable, and maintains non-vanishing gradients, enabling more efficient and robust optimization. We solve the constrained problem using a scalable primal-dual algorithm that exposes the trade-off between forgetting and retention through the dynamics of the dual variable. Evaluations on the TOFU and MUSE benchmarks across diverse LLM architectures demonstrate that our approach consistently matches or exceeds state-of-the-art baselines, effectively removing targeted information while preserving downstream utility.
Sinkhorn Transformations for Single-Query Postprocessing in Text-Video Retrieval
Nov 14, 2023



A recent trend in multimodal retrieval is related to postprocessing test set results via the dual-softmax loss (DSL). While this approach can bring significant improvements, it usually presumes that an entire matrix of test samples is available as DSL input. This work introduces a new postprocessing approach based on Sinkhorn transformations that outperforms DSL. Further, we propose a new postprocessing setting that does not require access to multiple test queries. We show that our approach can significantly improve the results of state of the art models such as CLIP4Clip, BLIP, X-CLIP, and DRL, thus achieving a new state-of-the-art on several standard text-video retrieval datasets both with access to the entire test set and in the single-query setting.
RepQuant: Towards Accurate Post-Training Quantization of Large Transformer Models via Scale Reparameterization
Feb 08, 2024



Large transformer models have demonstrated remarkable success. Post-training quantization (PTQ), which requires only a small dataset for calibration and avoids end-to-end retraining, is a promising solution for compressing these large models. Regrettably, existing PTQ methods typically exhibit non-trivial performance loss. We find that the performance bottleneck stems from over-consideration of hardware compatibility in the quantization process, compelling them to reluctantly employ simple quantizers, albeit at the expense of accuracy. With the above insights, we propose RepQuant, a novel PTQ framework with quantization-inference decoupling paradigm to address the above issues. RepQuant employs complex quantizers in the quantization process and simplified quantizers in the inference process, and performs mathematically equivalent transformations between the two through quantization scale reparameterization, thus ensuring both accurate quantization and efficient inference. More specifically, we focus on two components with extreme distributions: LayerNorm activations and Softmax activations. Initially, we apply channel-wise quantization and log$\sqrt{2}$ quantization, respectively, which are tailored to their distributions. In particular, for the former, we introduce a learnable per-channel dual clipping scheme, which is designed to efficiently identify outliers in the unbalanced activations with fine granularity. Then, we reparameterize the scales to hardware-friendly layer-wise quantization and log2 quantization for inference. Moreover, quantized weight reconstruction is seamlessly integrated into the above procedure to further push the performance limits. Extensive experiments are performed on different large-scale transformer variants on multiple tasks, including vision, language, and multi-modal transformers, and RepQuant encouragingly demonstrates significant performance advantages.
TagCLIP: A Local-to-Global Framework to Enhance Open-Vocabulary Multi-Label Classification of CLIP Without Training
Dec 20, 2023



Contrastive Language-Image Pre-training (CLIP) has demonstrated impressive capabilities in open-vocabulary classification. The class token in the image encoder is trained to capture the global features to distinguish different text descriptions supervised by contrastive loss, making it highly effective for single-label classification. However, it shows poor performance on multi-label datasets because the global feature tends to be dominated by the most prominent class and the contrastive nature of softmax operation aggravates it. In this study, we observe that the multi-label classification results heavily rely on discriminative local features but are overlooked by CLIP. As a result, we dissect the preservation of patch-wise spatial information in CLIP and proposed a local-to-global framework to obtain image tags. It comprises three steps: (1) patch-level classification to obtain coarse scores; (2) dual-masking attention refinement (DMAR) module to refine the coarse scores; (3) class-wise reidentification (CWR) module to remedy predictions from a global perspective. This framework is solely based on frozen CLIP and significantly enhances its multi-label classification performance on various benchmarks without dataset-specific training. Besides, to comprehensively assess the quality and practicality of generated tags, we extend their application to the downstream task, i.e., weakly supervised semantic segmentation (WSSS) with generated tags as image-level pseudo labels. Experiments demonstrate that this classify-then-segment paradigm dramatically outperforms other annotation-free segmentation methods and validates the effectiveness of generated tags. Our code is available at https://github.com/linyq2117/TagCLIP.
Unicom: Universal and Compact Representation Learning for Image Retrieval
Apr 12, 2023Modern image retrieval methods typically rely on fine-tuning pre-trained encoders to extract image-level descriptors. However, the most widely used models are pre-trained on ImageNet-1K with limited classes. The pre-trained feature representation is therefore not universal enough to generalize well to the diverse open-world classes. In this paper, we first cluster the large-scale LAION400M into one million pseudo classes based on the joint textual and visual features extracted by the CLIP model. Due to the confusion of label granularity, the automatically clustered dataset inevitably contains heavy inter-class conflict. To alleviate such conflict, we randomly select partial inter-class prototypes to construct the margin-based softmax loss. To further enhance the low-dimensional feature representation, we randomly select partial feature dimensions when calculating the similarities between embeddings and class-wise prototypes. The dual random partial selections are with respect to the class dimension and the feature dimension of the prototype matrix, making the classification conflict-robust and the feature embedding compact. Our method significantly outperforms state-of-the-art unsupervised and supervised image retrieval approaches on multiple benchmarks. The code and pre-trained models are released to facilitate future research https://github.com/deepglint/unicom.
Improving Text-Audio Retrieval by Text-aware Attention Pooling and Prior Matrix Revised Loss
Mar 19, 2023In text-audio retrieval (TAR) tasks, due to the heterogeneity of contents between text and audio, the semantic information contained in the text is only similar to certain frames within the audio. Yet, existing works aggregate the entire audio without considering the text, such as mean-pooling over the frames, which is likely to encode misleading audio information not described in the given text. In this paper, we present a text-aware attention pooling (TAP) module for TAR, which is essentially a scaled dot product attention for a text to attend to its most semantically similar frames. Furthermore, previous methods only conduct the softmax for every single-side retrieval, ignoring the potential cross-retrieval information. By exploring the intrinsic prior of each text-audio pair, we introduce a prior matrix revised (PMR) loss to filter the hard case with high (or low) text-to-audio but low (or high) audio-to-text similarity scores, thus achieving the dual optimal match. Experiments show that our TAP significantly outperforms various text-agnostic pooling functions. Moreover, our PMR loss also shows stable performance gains on multiple datasets.
Improving Video-Text Retrieval by Multi-Stream Corpus Alignment and Dual Softmax Loss
Sep 13, 2021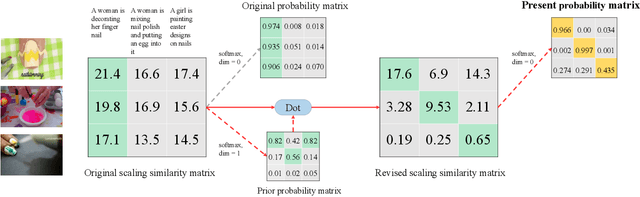
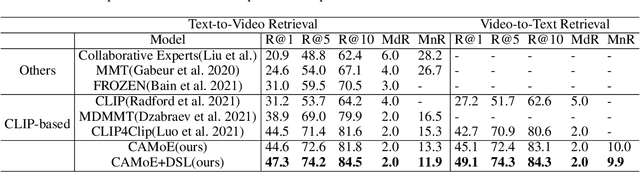
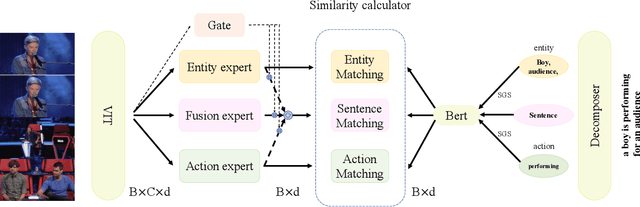
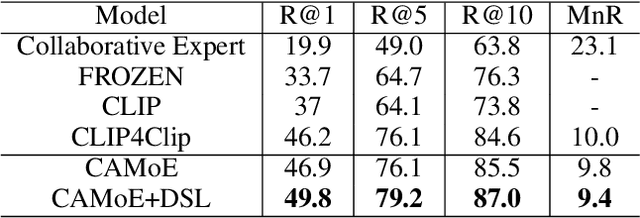
Employing large-scale pre-trained model CLIP to conduct video-text retrieval task (VTR) has become a new trend, which exceeds previous VTR methods. Though, due to the heterogeneity of structures and contents between video and text, previous CLIP-based models are prone to overfitting in the training phase, resulting in relatively poor retrieval performance. In this paper, we propose a multi-stream Corpus Alignment network with single gate Mixture-of-Experts (CAMoE) and a novel Dual Softmax Loss (DSL) to solve the two heterogeneity. The CAMoE employs Mixture-of-Experts (MoE) to extract multi-perspective video representations, including action, entity, scene, etc., then align them with the corresponding part of the text. In this stage, we conduct massive explorations towards the feature extraction module and feature alignment module. DSL is proposed to avoid the one-way optimum-match which occurs in previous contrastive methods. Introducing the intrinsic prior of each pair in a batch, DSL serves as a reviser to correct the similarity matrix and achieves the dual optimal match. DSL is easy to implement with only one-line code but improves significantly. The results show that the proposed CAMoE and DSL are of strong efficiency, and each of them is capable of achieving State-of-The-Art (SOTA) individually on various benchmarks such as MSR-VTT, MSVD, and LSMDC. Further, with both of them, the performance is advanced to a big extend, surpassing the previous SOTA methods for around 4.6\% R@1 in MSR-VTT.
Egocentric Video-Language Pretraining @ EPIC-KITCHENS-100 Multi-Instance Retrieval Challenge 2022
Jul 04, 2022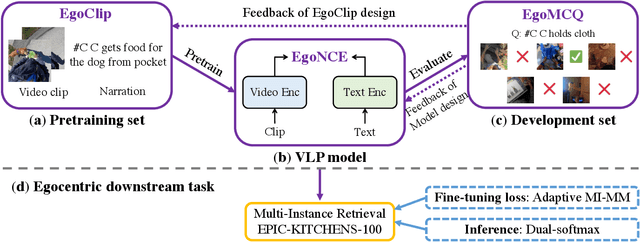
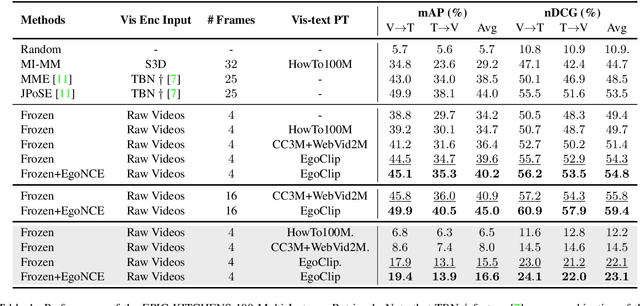
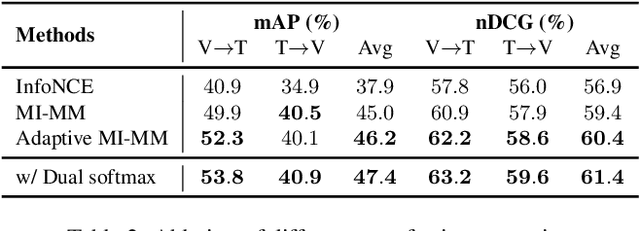
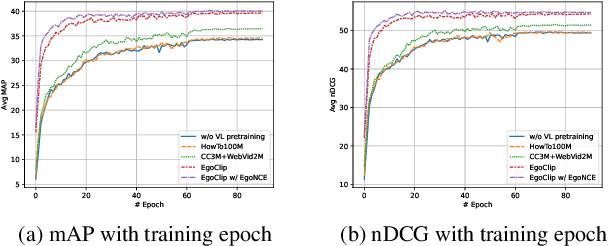
In this report, we propose a video-language pretraining (VLP) based solution \cite{kevin2022egovlp} for the EPIC-KITCHENS-100 Multi-Instance Retrieval (MIR) challenge. Especially, we exploit the recently released Ego4D dataset \cite{grauman2021ego4d} to pioneer Egocentric VLP from pretraining dataset, pretraining objective, and development set. Based on the above three designs, we develop a pretrained video-language model that is able to transfer its egocentric video-text representation to MIR benchmark. Furthermore, we devise an adaptive multi-instance max-margin loss to effectively fine-tune the model and equip the dual-softmax technique for reliable inference. Our best single model obtains strong performance on the challenge test set with 47.39% mAP and 61.44% nDCG. The code is available at https://github.com/showlab/EgoVLP.
Rebalanced Siamese Contrastive Mining for Long-Tailed Recognition
Mar 22, 2022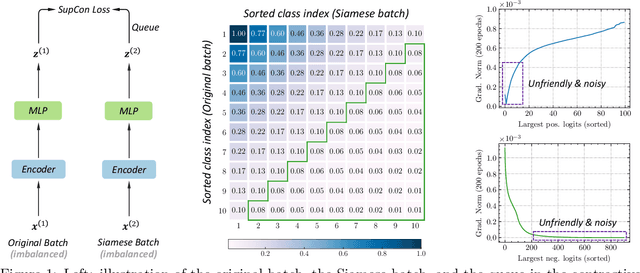
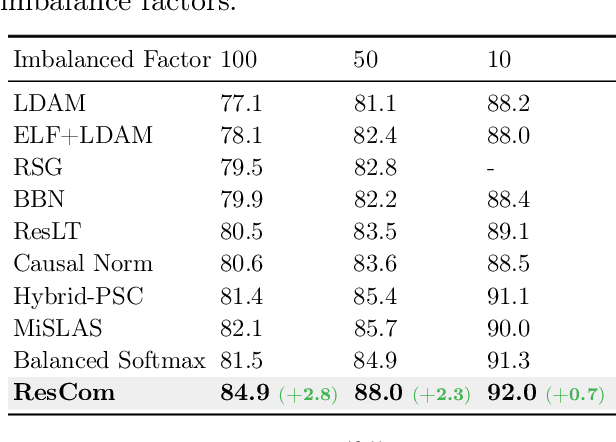
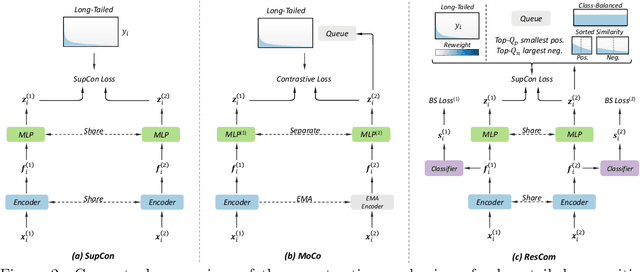
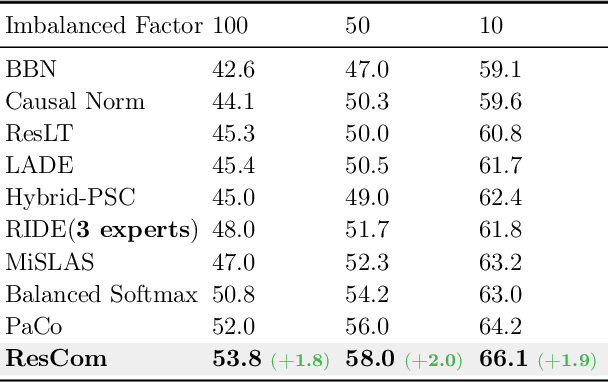
Deep neural networks perform poorly on heavily class-imbalanced datasets. Given the promising performance of contrastive learning, we propose $\mathbf{Re}$balanced $\mathbf{S}$iamese $\mathbf{Co}$ntrastive $\mathbf{m}$ining ( $\mathbf{ResCom}$) to tackle imbalanced recognition. Based on the mathematical analysis and simulation results, we claim that supervised contrastive learning suffers a dual class-imbalance problem at both the original batch and Siamese batch levels, which is more serious than long-tailed classification learning. In this paper, at the original batch level, we introduce a class-balanced supervised contrastive loss to assign adaptive weights for different classes. At the Siamese batch level, we present a class-balanced queue, which maintains the same number of keys for all classes. Furthermore, we note that the contrastive loss gradient with respect to the contrastive logits can be decoupled into the positives and negatives, and easy positives and easy negatives will make the contrastive gradient vanish. We propose supervised hard positive and negative pairs mining to pick up informative pairs for contrastive computation and improve representation learning. Finally, to approximately maximize the mutual information between the two views, we propose Siamese Balanced Softmax and joint it with the contrastive loss for one-stage training. ResCom outperforms the previous methods by large margins on multiple long-tailed recognition benchmarks. Our code will be made publicly available at: https://github.com/dvlab-research/ResCom.