 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLABench: A Large-Scale Benchmark for Language-Conditioned Robotics Manipulation with Long-Horizon Reasoning Tasks
Dec 24, 2024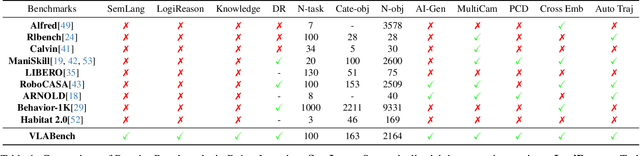
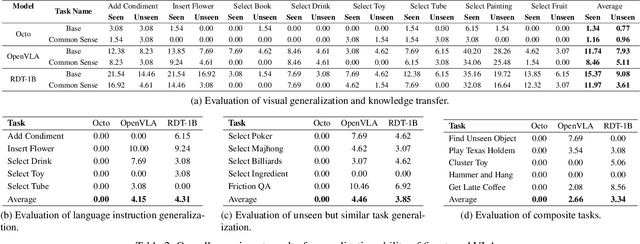

General-purposed embodied agents are designed to understand the users' natural instructions or intentions and act precisely to complete universal tasks. Recently, methods based on foundation models especially Vision-Language-Action models (VLAs) have shown a substantial potential to solve language-conditioned manipulation (LCM) tasks well. However, existing benchmarks do not adequately meet the needs of VLAs and relative algorithms. To better define such general-purpose tasks in the context of LLMs and advance the research in VLAs, we present VLABench, an open-source benchmark for evaluating universal LCM task learning. VLABench provides 100 carefully designed categories of tasks, with strong randomization in each category of task and a total of 2000+ objects. VLABench stands out from previous benchmarks in four key aspects: 1) tasks requiring world knowledge and common sense transfer, 2) natural language instructions with implicit human intentions rather than templates, 3) long-horizon tasks demanding multi-step reasoning, and 4) evaluation of both action policies and language model capabilities. The benchmark assesses multiple competencies including understanding of mesh\&texture, spatial relationship, semantic instruction, physical laws, knowledge transfer and reasoning, etc. To support the downstream finetuning, we provide high-quality training data collected via an automated framework incorporating heuristic skills and prior information. The experimental results indicate that both the current state-of-the-art pretrained VLAs and the workflow based on VLMs face challenges in our tasks.
Comprehensive Multi-Modal Prototypes are Simple and Effective Classifiers for Vast-Vocabulary Object Detection
Dec 23, 2024



Enabling models to recognize vast open-world categories has been a longstanding pursuit in object detection. By leveraging the generalization capabilities of vision-language models, current open-world detectors can recognize a broader range of vocabularies, despite being trained on limited categories. However, when the scale of the category vocabularies during training expands to a real-world level, previous classifiers aligned with coarse class names significantly reduce the recognition performance of these detectors. In this paper, we introduce Prova, a multi-modal prototype classifier for vast-vocabulary object detection. Prova extracts comprehensive multi-modal prototypes as initialization of alignment classifiers to tackle the vast-vocabulary object recognition failure problem. On V3Det, this simple method greatly enhances the performance among one-stage, two-stage, and DETR-based detectors with only additional projection layers in both supervised and open-vocabulary settings. In particular, Prova improves Faster R-CNN, FCOS, and DINO by 3.3, 6.2, and 2.9 AP respectively in the supervised setting of V3Det. For the open-vocabulary setting, Prova achieves a new state-of-the-art performance with 32.8 base AP and 11.0 novel AP, which is of 2.6 and 4.3 gain over the previous methods.
CreatiLayout: Siamese Multimodal Diffusion Transformer for Creative Layout-to-Image Generation
Dec 05, 2024



Diffusion models have been recognized for their ability to generate images that are not only visually appealing but also of high artistic quality. As a result, Layout-to-Image (L2I) generation has been proposed to leverage region-specific positions and descriptions to enable more precise and controllable generation. However, previous methods primarily focus on UNet-based models (e.g., SD1.5 and SDXL), and limited effort has explored Multimodal Diffusion Transformers (MM-DiTs), which have demonstrated powerful image generation capabilities. Enabling MM-DiT for layout-to-image generation seems straightforward but is challenging due to the complexity of how layout is introduced, integrated, and balanced among multiple modalities. To this end, we explore various network variants to efficiently incorporate layout guidance into MM-DiT, and ultimately present SiamLayout. To Inherit the advantages of MM-DiT, we use a separate set of network weights to process the layout, treating it as equally important as the image and text modalities. Meanwhile, to alleviate the competition among modalities, we decouple the image-layout interaction into a siamese branch alongside the image-text one and fuse them in the later stage. Moreover, we contribute a large-scale layout dataset, named LayoutSAM, which includes 2.7 million image-text pairs and 10.7 million entities. Each entity is annotated with a bounding box and a detailed description. We further construct the LayoutSAM-Eval benchmark as a comprehensive tool for evaluating the L2I generation quality. Finally, we introduce the Layout Designer, which taps into the potential of large language models in layout planning, transforming them into experts in layout generation and optimization. Our code, model, and dataset will be available at https://creatilayout.github.io.
Inst-IT: Boosting Multimodal Instance Understanding via Explicit Visual Prompt Instruction Tuning
Dec 04, 2024



Large Multimodal Models (LMMs) have made significant breakthroughs with the advancement of instruction tuning. However, while existing models can understand images and videos at a holistic level, they still struggle with instance-level understanding that requires a more nuanced comprehension and alignment. Instance-level understanding is crucial, as it focuses on the specific elements that we are most interested in. Excitingly, existing works find that the state-of-the-art LMMs exhibit strong instance understanding capabilities when provided with explicit visual cues. Motivated by this, we introduce an automated annotation pipeline assisted by GPT-4o to extract instance-level information from images and videos through explicit visual prompting for instance guidance. Building upon this pipeline, we proposed Inst-IT, a solution to enhance LMMs in Instance understanding via explicit visual prompt Instruction Tuning. Inst-IT consists of a benchmark to diagnose multimodal instance-level understanding, a large-scale instruction-tuning dataset, and a continuous instruction-tuning training paradigm to effectively enhance spatial-temporal instance understanding capabilities of existing LMMs. Experimental results show that, with the boost of Inst-IT, our models not only achieve outstanding performance on Inst-IT Bench but also demonstrate significant improvements across various generic image and video understanding benchmarks. This highlights that our dataset not only boosts instance-level understanding but also strengthens the overall capabilities of generic image and video comprehension.
ForgerySleuth: Empowering Multimodal Large Language Models for Image Manipulation Detection
Nov 29, 2024



Multimodal large language models have unlocked new possibilities for various multimodal tasks. However, their potential in image manipulation detection remains unexplored. When directly applied to the IMD task, M-LLMs often produce reasoning texts that suffer from hallucinations and overthinking. To address this, in this work, we propose ForgerySleuth, which leverages M-LLMs to perform comprehensive clue fusion and generate segmentation outputs indicating specific regions that are tampered with. Moreover, we construct the ForgeryAnalysis dataset through the Chain-of-Clues prompt, which includes analysis and reasoning text to upgrade the image manipulation detection task. A data engine is also introduced to build a larger-scale dataset for the pre-training phase. Our extensive experiments demonstrate the effectiveness of ForgeryAnalysis and show that ForgerySleuth significantly outperforms existing methods in generalization, robustness, and explainability.
StableAnimator: High-Quality Identity-Preserving Human Image Animation
Nov 26, 2024Current diffusion models for human image animation struggle to ensure identity (ID) consistency. This paper presents StableAnimator, the first end-to-end ID-preserving video diffusion framework, which synthesizes high-quality videos without any post-processing, conditioned on a reference image and a sequence of poses. Building upon a video diffusion model, StableAnimator contains carefully designed modules for both training and inference striving for identity consistency. In particular, StableAnimator begins by computing image and face embeddings with off-the-shelf extractors, respectively and face embeddings are further refined by interacting with image embeddings using a global content-aware Face Encoder. Then, StableAnimator introduces a novel distribution-aware ID Adapter that prevents interference caused by temporal layers while preserving ID via alignment. During inference, we propose a novel Hamilton-Jacobi-Bellman (HJB) equation-based optimization to further enhance the face quality. We demonstrate that solving the HJB equation can be integrated into the diffusion denoising process, and the resulting solution constrains the denoising path and thus benefits ID preservation. Experiments on multiple benchmarks show the effectiveness of StableAnimator both qualitatively and quantitatively.
Enhancing LLM Reasoning via Critique Models with Test-Time and Training-Time Supervision
Nov 25, 2024



Training large language models (LLMs) to spend more time thinking and reflection before responding is crucial for effectively solving complex reasoning tasks in fields such as science, coding, and mathematics. However, the effectiveness of mechanisms like self-reflection and self-correction depends on the model's capacity to accurately assess its own performance, which can be limited by factors such as initial accuracy, question difficulty, and the lack of external feedback. In this paper, we delve into a two-player paradigm that separates the roles of reasoning and critique models, where the critique model provides step-level feedback to supervise the reasoning (actor) model during both test-time and train-time. We first propose AutoMathCritique, an automated and scalable framework for collecting critique data, resulting in a dataset of $76,321$ responses paired with step-level feedback. Fine-tuning language models with this dataset enables them to generate natural language feedback for mathematical reasoning. We demonstrate that the critique models consistently improve the actor's performance on difficult queries at test-time, especially when scaling up inference-time computation. Motivated by these findings, we introduce the critique-based supervision to the actor's self-training process, and propose a critique-in-the-loop self-improvement method. Experiments show that the method improves the actor's exploration efficiency and solution diversity, especially on challenging queries, leading to a stronger reasoning model. Lastly, we take the preliminary step to explore training self-talk reasoning models via critique supervision and showcase its potential. Our code and datasets are at \href{https://mathcritique.github.io/}{https://mathcritique.github.io/}.
REDUCIO! Generating 1024$\times$1024 Video within 16 Seconds using Extremely Compressed Motion Latents
Nov 20, 2024



Commercial video generation models have exhibited realistic, high-fidelity results but are still restricted to limited access. One crucial obstacle for large-scale applications is the expensive training and inference cost. In this paper, we argue that videos contain much more redundant information than images, thus can be encoded by very few motion latents based on a content image. Towards this goal, we design an image-conditioned VAE to encode a video to an extremely compressed motion latent space. This magic Reducio charm enables 64x reduction of latents compared to a common 2D VAE, without sacrificing the quality. Training diffusion models on such a compact representation easily allows for generating 1K resolution videos. We then adopt a two-stage video generation paradigm, which performs text-to-image and text-image-to-video sequentially. Extensive experiments show that our Reducio-DiT achieves strong performance in evaluation, though trained with limited GPU resources. More importantly, our method significantly boost the efficiency of video LDMs both in training and inference. We train Reducio-DiT in around 3.2K training hours in total and generate a 16-frame 1024*1024 video clip within 15.5 seconds on a single A100 GPU. Code released at https://github.com/microsoft/Reducio-VAE .
Llama Scope: Extracting Millions of Features from Llama-3.1-8B with Sparse Autoencoders
Oct 27, 2024



Sparse Autoencoders (SAEs) have emerged as a powerful unsupervised method for extracting sparse representations from language models, yet scalable training remains a significant challenge. We introduce a suite of 256 SAEs, trained on each layer and sublayer of the Llama-3.1-8B-Base model, with 32K and 128K features. Modifications to a state-of-the-art SAE variant, Top-K SAEs, are evaluated across multiple dimensions. In particular, we assess the generalizability of SAEs trained on base models to longer contexts and fine-tuned models. Additionally, we analyze the geometry of learned SAE latents, confirming that \emph{feature splitting} enables the discovery of new features. The Llama Scope SAE checkpoints are publicly available at~\url{https://huggingface.co/fnlp/Llama-Scope}, alongside our scalable training, interpretation, and visualization tools at \url{https://github.com/OpenMOSS/Language-Model-SAEs}. These contributions aim to advance the open-source Sparse Autoencoder ecosystem and support mechanistic interpretability research by reducing the need for redundant SAE training.
DreamMesh: Jointly Manipulating and Texturing Triangle Meshes for Text-to-3D Generation
Sep 11, 2024



Learning radiance fields (NeRF) with powerful 2D diffusion models has garnered popularity for text-to-3D generation. Nevertheless, the implicit 3D representations of NeRF lack explicit modeling of meshes and textures over surfaces, and such surface-undefined way may suffer from the issues, e.g., noisy surfaces with ambiguous texture details or cross-view inconsistency. To alleviate this, we present DreamMesh, a novel text-to-3D architecture that pivots on well-defined surfaces (triangle meshes) to generate high-fidelity explicit 3D model. Technically, DreamMesh capitalizes on a distinctive coarse-to-fine scheme. In the coarse stage, the mesh is first deformed by text-guided Jacobians and then DreamMesh textures the mesh with an interlaced use of 2D diffusion models in a tuning free manner from multiple viewpoints. In the fine stage, DreamMesh jointly manipulates the mesh and refines the texture map, leading to high-quality triangle meshes with high-fidelity textured materials. Extensive experiments demonstrate that DreamMesh significantly outperforms state-of-the-art text-to-3D methods in faithfully generating 3D content with richer textual details and enhanced geometry. Our project page is available at https://dreammesh.github.io.