 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Fidelity Estimation for Quantum Programs with Graph-Guided Noise Awareness
Jan 21, 2026Fidelity estimation is a critical yet resource-intensive step in testing quantum programs on noisy intermediate-scale quantum (NISQ) devices, where the required number of measurements is difficult to predefine due to hardware noise, device heterogeneity, and transpilation-induced circuit transformations. We present QuFid, an adaptive and noise-aware framework that determines measurement budgets online by leveraging circuit structure and runtime statistical feedback. QuFid models a quantum program as a directed acyclic graph (DAG) and employs a control-flow-aware random walk to characterize noise propagation along gate dependencies. Backend-specific effects are captured via transpilation-induced structural deformation metrics, which are integrated into the random-walk formulation to induce a noise-propagation operator. Circuit complexity is then quantified through the spectral characteristics of this operator, providing a principled and lightweight basis for adaptive measurement planning. Experiments on 18 quantum benchmarks executed on IBM Quantum backends show that QuFid significantly reduces measurement cost compared to fixed-shot and learning-based baselines, while consistently maintaining acceptable fidelity bias.
CoF-T2I: Video Models as Pure Visual Reasoners for Text-to-Image Generation
Jan 15, 2026Recent video generation models have revealed the emergence of Chain-of-Frame (CoF) reasoning, enabling frame-by-frame visual inference. With this capability, video models have been successfully applied to various visual tasks (e.g., maze solving, visual puzzles). However, their potential to enhance text-to-image (T2I) generation remains largely unexplored due to the absence of a clearly defined visual reasoning starting point and interpretable intermediate states in the T2I generation process. To bridge this gap, we propose CoF-T2I, a model that integrates CoF reasoning into T2I generation via progressive visual refinement, where intermediate frames act as explicit reasoning steps and the final frame is taken as output. To establish such an explicit generation process, we curate CoF-Evol-Instruct, a dataset of CoF trajectories that model the generation process from semantics to aesthetics. To further improve quality and avoid motion artifacts, we enable independent encoding operation for each frame. Experiments show that CoF-T2I significantly outperforms the base video model and achieves competitive performance on challenging benchmarks, reaching 0.86 on GenEval and 7.468 on Imagine-Bench. These results indicate the substantial promise of video models for advancing high-quality text-to-image generation.
A.S.E: A Repository-Level Benchmark for Evaluating Security in AI-Generated Code
Aug 25, 2025The increasing adoption of large language models (LLMs) in software engineering necessitates rigorous security evaluation of their generated code. However, existing benchmarks are inadequate, as they focus on isolated code snippets, employ unstable evaluation methods that lack reproducibility, and fail to connect the quality of input context with the security of the output. To address these gaps, we introduce A.S.E (AI Code Generation Security Evaluation), a benchmark for repository-level secure code generation. A.S.E constructs tasks from real-world repositories with documented CVEs, preserving full repository context like build systems and cross-file dependencies. Its reproducible, containerized evaluation framework uses expert-defined rules to provide stable, auditable assessments of security, build quality, and generation stability. Our evaluation of leading LLMs on A.S.E reveals three key findings: (1) Claude-3.7-Sonnet achieves the best overall performance. (2) The security gap between proprietary and open-source models is narrow; Qwen3-235B-A22B-Instruct attains the top security score. (3) Concise, ``fast-thinking'' decoding strategies consistently outperform complex, ``slow-thinking'' reasoning for security patching.
Chimera: Harnessing Multi-Agent LLMs for Automatic Insider Threat Simulation
Aug 12, 2025Insider threats, which can lead to severe losses, remain a major security concern. While machine learning-based insider threat detection (ITD) methods have shown promising results, their progress is hindered by the scarcity of high-quality data. Enterprise data is sensitive and rarely accessible, while publicly available datasets, when limited in scale due to cost, lack sufficient real-world coverage; and when purely synthetic, they fail to capture rich semantics and realistic user behavior. To address this, we propose Chimera, the first large language model (LLM)-based multi-agent framework that automatically simulates both benign and malicious insider activities and collects diverse logs across diverse enterprise environments. Chimera models each employee with agents that have role-specific behavior and integrates modules for group meetings, pairwise interactions, and autonomous scheduling, capturing realistic organizational dynamics. It incorporates 15 types of insider attacks (e.g., IP theft, system sabotage) and has been deployed to simulate activities in three sensitive domains: technology company, finance corporation, and medical institution, producing a new dataset, ChimeraLog. We assess ChimeraLog via human studies and quantitative analysis, confirming its diversity, realism, and presence of explainable threat patterns. Evaluations of existing ITD methods show an average F1-score of 0.83, which is significantly lower than 0.99 on the CERT dataset, demonstrating ChimeraLog's higher difficulty and utility for advancing ITD research.
From Images to Signals: Are Large Vision Models Useful for Time Series Analysis?
May 29, 2025Transformer-based models have gained increasing attention in time series research, driving interest in Large Language Models (LLMs) and foundation models for time series analysis. As the field moves toward multi-modality, Large Vision Models (LVMs) are emerging as a promising direction. In the past, the effectiveness of Transformer and LLMs in time series has been debated. When it comes to LVMs, a similar question arises: are LVMs truely useful for time series analysis? To address it, we design and conduct the first principled study involving 4 LVMs, 8 imaging methods, 18 datasets and 26 baselines across both high-level (classification) and low-level (forecasting) tasks, with extensive ablation analysis. Our findings indicate LVMs are indeed useful for time series classification but face challenges in forecasting. Although effective, the contemporary best LVM forecasters are limited to specific types of LVMs and imaging methods, exhibit a bias toward forecasting periods, and have limited ability to utilize long look-back windows. We hope our findings could serve as a cornerstone for future research on LVM- and multimodal-based solutions to different time series tasks.
Multi-Modal View Enhanced Large Vision Models for Long-Term Time Series Forecasting
May 29, 2025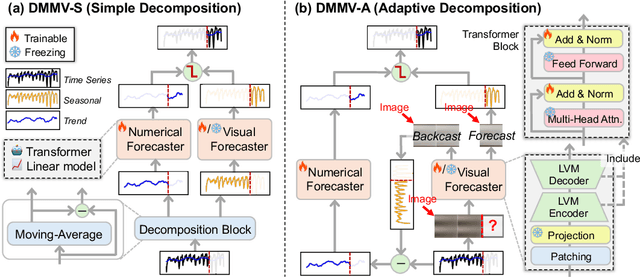

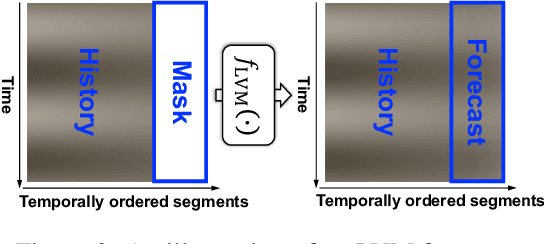

Time series, typically represented as numerical sequences, can also be transformed into images and texts, offering multi-modal views (MMVs) of the same underlying signal. These MMVs can reveal complementary patterns and enable the use of powerful pre-trained large models, such as large vision models (LVMs), for long-term time series forecasting (LTSF). However, as we identified in this work, applying LVMs to LTSF poses an inductive bias towards "forecasting periods". To harness this bias, we propose DMMV, a novel decomposition-based multi-modal view framework that leverages trend-seasonal decomposition and a novel backcast residual based adaptive decomposition to integrate MMVs for LTSF. Comparative evaluations against 14 state-of-the-art (SOTA) models across diverse datasets show that DMMV outperforms single-view and existing multi-modal baselines, achieving the best mean squared error (MSE) on 6 out of 8 benchmark datasets.
Harnessing Vision Models for Time Series Analysis: A Survey
Feb 13, 2025



Time series analysis has witnessed the inspiring development from traditional autoregressive models, deep learning models, to recent Transformers and Large Language Models (LLMs). Efforts in leveraging vision models for time series analysis have also been made along the way but are less visible to the community due to the predominant research on sequence modeling in this domain. However, the discrepancy between continuous time series and the discrete token space of LLMs, and the challenges in explicitly modeling the correlations of variates in multivariate time series have shifted some research attentions to the equally successful Large Vision Models (LVMs) and Vision Language Models (VLMs). To fill the blank in the existing literature, this survey discusses the advantages of vision models over LLMs in time series analysis. It provides a comprehensive and in-depth overview of the existing methods, with dual views of detailed taxonomy that answer the key research questions including how to encode time series as images and how to model the imaged time series for various tasks. Additionally, we address the challenges in the pre- and post-processing steps involved in this framework and outline future directions to further advance time series analysis with vision models.
Rethinking Membership Inference Attacks Against Transfer Learning
Jan 20, 2025Transfer learning, successful in knowledge translation across related tasks, faces a substantial privacy threat from membership inference attacks (MIAs). These attacks, despite posing significant risk to ML model's training data, remain limited-explored in transfer learning. The interaction between teacher and student models in transfer learning has not been thoroughly explored in MIAs, potentially resulting in an under-examined aspect of privacy vulnerabilities within transfer learning. In this paper, we propose a new MIA vector against transfer learning, to determine whether a specific data point was used to train the teacher model while only accessing the student model in a white-box setting. Our method delves into the intricate relationship between teacher and student models, analyzing the discrepancies in hidden layer representations between the student model and its shadow counterpart. These identified differences are then adeptly utilized to refine the shadow model's training process and to inform membership inference decisions effectively. Our method, evaluated across four datasets in diverse transfer learning tasks, reveals that even when an attacker only has access to the student model, the teacher model's training data remains susceptible to MIAs. We believe our work unveils the unexplored risk of membership inference in transfer learning.
HyperSMOTE: A Hypergraph-based Oversampling Approach for Imbalanced Node Classifications
Sep 09, 2024



Hypergraphs are increasingly utilized in both unimodal and multimodal data scenarios due to their superior ability to model and extract higher-order relationships among nodes, compared to traditional graphs. However, current hypergraph models are encountering challenges related to imbalanced data, as this imbalance can lead to biases in the model towards the more prevalent classes. While the existing techniques, such as GraphSMOTE, have improved classification accuracy for minority samples in graph data, they still fall short when addressing the unique structure of hypergraphs. Inspired by SMOTE concept, we propose HyperSMOTE as a solution to alleviate the class imbalance issue in hypergraph learning. This method involves a two-step process: initially synthesizing minority class nodes, followed by the nodes integration into the original hypergraph. We synthesize new nodes based on samples from minority classes and their neighbors. At the same time, in order to solve the problem on integrating the new node into the hypergraph, we train a decoder based on the original hypergraph incidence matrix to adaptively associate the augmented node to hyperedges. We conduct extensive evaluation on multiple single-modality datasets, such as Cora, Cora-CA and Citeseer, as well as multimodal conversation dataset MELD to verify the effectiveness of HyperSMOTE, showing an average performance gain of 3.38% and 2.97% on accuracy, respectively.
UltraGelBot: Autonomous Gel Dispenser for Robotic Ultrasound
Jun 28, 2024Telerobotic and Autonomous Robotic Ultrasound Systems (RUS) help alleviate the need for operator-dependability in free-hand ultrasound examinations. However, the state-of-the-art RUSs still rely on a human operator to apply the ultrasound gel. The lack of standardization in this process often leads to poor imaging of the scanned region. The reason for this has to do with air-gaps between the probe and the human body. In this paper, we developed a end-of-arm tool for RUS, referred to as UltraGelBot. This bot can autonomously detect and dispense the gel. It uses a deep learning model to detect the gel from images acquired using an on-board camera. A motorized mechanism is also developed, which will use this feedback and dispense the gel. Experiments on phantom revealed that UltraGelBot increases the acquired image quality by $18.6\%$ and reduces the procedure time by $37.2\%$.