 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Policy Exploitation in Online Reinforcement Learning with Instant Retrospect Action
Jan 27, 2026Existing value-based online reinforcement learning (RL) algorithms suffer from slow policy exploitation due to ineffective exploration and delayed policy updates. To address these challenges, we propose an algorithm called Instant Retrospect Action (IRA). Specifically, we propose Q-Representation Discrepancy Evolution (RDE) to facilitate Q-network representation learning, enabling discriminative representations for neighboring state-action pairs. In addition, we adopt an explicit method to policy constraints by enabling Greedy Action Guidance (GAG). This is achieved through backtracking historical actions, which effectively enhances the policy update process. Our proposed method relies on providing the learning algorithm with accurate $k$-nearest-neighbor action value estimates and learning to design a fast-adaptable policy through policy constraints. We further propose the Instant Policy Update (IPU) mechanism, which enhances policy exploitation by systematically increasing the frequency of policy updates. We further discover that the early-stage training conservatism of the IRA method can alleviate the overestimation bias problem in value-based RL. Experimental results show that IRA can significantly improve the learning efficiency and final performance of online RL algorithms on eight MuJoCo continuous control tasks.
Mask-Guided Multi-Task Network for Face Attribute Recognition
Jan 04, 2026Face Attribute Recognition (FAR) plays a crucial role in applications such as person re-identification, face retrieval, and face editing. Conventional multi-task attribute recognition methods often process the entire feature map for feature extraction and attribute classification, which can produce redundant features due to reliance on global regions. To address these challenges, we propose a novel approach emphasizing the selection of specific feature regions for efficient feature learning. We introduce the Mask-Guided Multi-Task Network (MGMTN), which integrates Adaptive Mask Learning (AML) and Group-Global Feature Fusion (G2FF) to address the aforementioned limitations. Leveraging a pre-trained keypoint annotation model and a fully convolutional network, AML accurately localizes critical facial parts (e.g., eye and mouth groups) and generates group masks that delineate meaningful feature regions, thereby mitigating negative transfer from global region usage. Furthermore, G2FF combines group and global features to enhance FAR learning, enabling more precise attribute identification. Extensive experiments on two challenging facial attribute recognition datasets demonstrate the effectiveness of MGMTN in improving FAR performance.
FAR-AMTN: Attention Multi-Task Network for Face Attribute Recognition
Jan 04, 2026To enhance the generalization performance of Multi-Task Networks (MTN) in Face Attribute Recognition (FAR), it is crucial to share relevant information across multiple related prediction tasks effectively. Traditional MTN methods create shared low-level modules and distinct high-level modules, causing an exponential increase in model parameters with the addition of tasks. This approach also limits feature interaction at the high level, hindering the exploration of semantic relations among attributes, thereby affecting generalization negatively. In response, this study introduces FAR-AMTN, a novel Attention Multi-Task Network for FAR. It incorporates a Weight-Shared Group-Specific Attention (WSGSA) module with shared parameters to minimize complexity while improving group feature representation. Furthermore, a Cross-Group Feature Fusion (CGFF) module is utilized to foster interactions between attribute groups, enhancing feature learning. A Dynamic Weighting Strategy (DWS) is also introduced for synchronized task convergence. Experiments on the CelebA and LFWA datasets demonstrate that the proposed FAR-AMTN demonstrates superior accuracy with significantly fewer parameters compared to existing models.
* 28 pages, 8figures
Modality Dominance-Aware Optimization for Embodied RGB-Infrared Perception
Jan 02, 2026RGB-Infrared (RGB-IR) multimodal perception is fundamental to embodied multimedia systems operating in complex physical environments. Although recent cross-modal fusion methods have advanced RGB-IR detection, the optimization dynamics caused by asymmetric modality characteristics remain underexplored. In practice, disparities in information density and feature quality introduce persistent optimization bias, leading training to overemphasize a dominant modality and hindering effective fusion. To quantify this phenomenon, we propose the Modality Dominance Index (MDI), which measures modality dominance by jointly modeling feature entropy and gradient contribution. Based on MDI, we develop a Modality Dominance-Aware Cross-modal Learning (MDACL) framework that regulates cross-modal optimization. MDACL incorporates Hierarchical Cross-modal Guidance (HCG) to enhance feature alignment and Adversarial Equilibrium Regularization (AER) to balance optimization dynamics during fusion. Extensive experiments on three RGB-IR benchmarks demonstrate that MDACL effectively mitigates optimization bias and achieves SOTA performance.
Modification Takes Courage: Seamless Image Stitching via Reference-Driven Inpainting
Nov 15, 2024



Current image stitching methods often produce noticeable seams in challenging scenarios such as uneven hue and large parallax. To tackle this problem, we propose the Reference-Driven Inpainting Stitcher (RDIStitcher), which reformulates the image fusion and rectangling as a reference-based inpainting model, incorporating a larger modification fusion area and stronger modification intensity than previous methods. Furthermore, we introduce a self-supervised model training method, which enables the implementation of RDIStitcher without requiring labeled data by fine-tuning a Text-to-Image (T2I) diffusion model. Recognizing difficulties in assessing the quality of stitched images, we present the Multimodal Large Language Models (MLLMs)-based metrics, offering a new perspective on evaluating stitched image quality. Compared to the state-of-the-art (SOTA) method, extensive experiments demonstrate that our method significantly enhances content coherence and seamless transitions in the stitched images. Especially in the zero-shot experiments, our method exhibits strong generalization capabilities. Code: https://github.com/yayoyo66/RDIStitcher
CHASE: A Causal Heterogeneous Graph based Framework for Root Cause Analysis in Multimodal Microservice Systems
Jun 28, 2024In recent years, the widespread adoption of distributed microservice architectures within the industry has significantly increased the demand for enhanced system availability and robustness. Due to the complex service invocation paths and dependencies at enterprise-level microservice systems, it is challenging to locate the anomalies promptly during service invocations, thus causing intractable issues for normal system operations and maintenance. In this paper, we propose a Causal Heterogeneous grAph baSed framEwork for root cause analysis, namely CHASE, for microservice systems with multimodal data, including traces, logs, and system monitoring metrics. Specifically, related information is encoded into representative embeddings and further modeled by a multimodal invocation graph. Following that, anomaly detection is performed on each instance node with attentive heterogeneous message passing from its adjacent metric and log nodes. Finally, CHASE learns from the constructed hypergraph with hyperedges representing the flow of causality and performs root cause localization. We evaluate the proposed framework on two public microservice datasets with distinct attributes and compare with the state-of-the-art methods. The results show that CHASE achieves the average performance gain up to 36.2%(A@1) and 29.4%(Percentage@1), respectively to its best counterpart.
GFTE: Graph-based Financial Table Extraction
Mar 17, 2020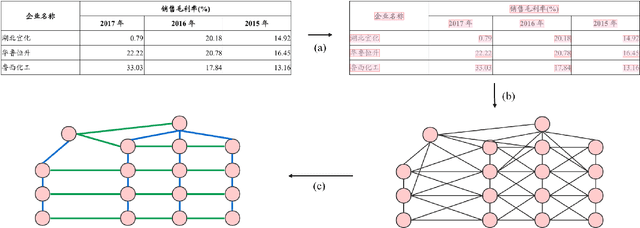
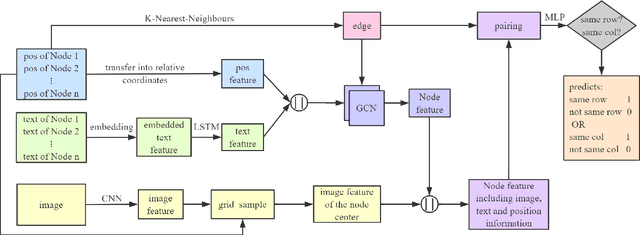
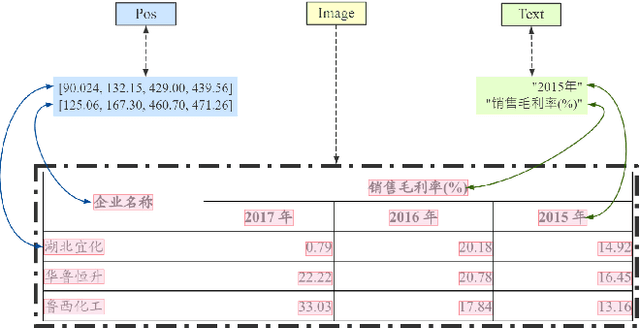
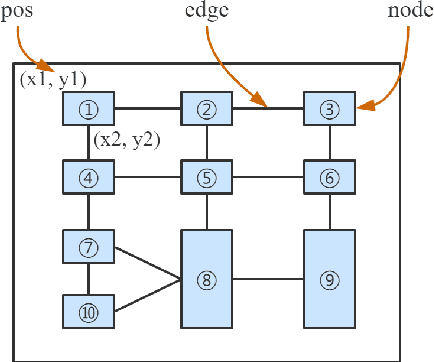
Tabular data is a crucial form of information expression, which can organize data in a standard structure for easy information retrieval and comparison. However, in financial industry and many other fields tables are often disclosed in unstructured digital files, e.g. Portable Document Format (PDF) and images, which are difficult to be extracted directly. In this paper, to facilitate deep learning based table extraction from unstructured digital files, we publish a standard Chinese dataset named FinTab, which contains more than 1,600 financial tables of diverse kinds and their corresponding structure representation in JSON. In addition, we propose a novel graph-based convolutional neural network model named GFTE as a baseline for future comparison. GFTE integrates image feature, position feature and textual feature together for precise edge prediction and reaches overall good results.