 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal View Enhanced Large Vision Models for Long-Term Time Series Forecasting
Paper and Code
May 29, 2025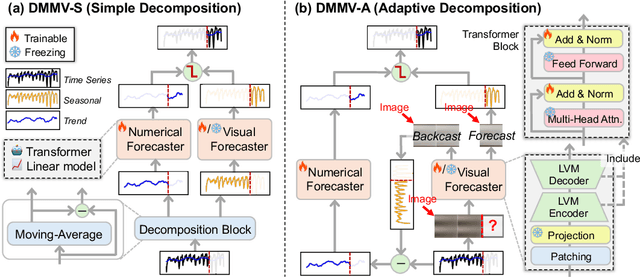

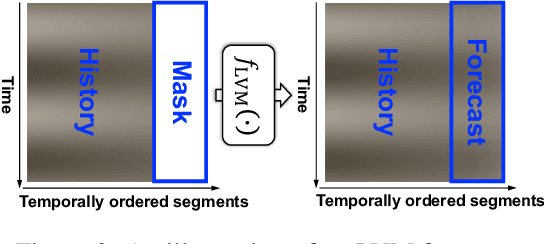

Time series, typically represented as numerical sequences, can also be transformed into images and texts, offering multi-modal views (MMVs) of the same underlying signal. These MMVs can reveal complementary patterns and enable the use of powerful pre-trained large models, such as large vision models (LVMs), for long-term time series forecasting (LTSF). However, as we identified in this work, applying LVMs to LTSF poses an inductive bias towards "forecasting periods". To harness this bias, we propose DMMV, a novel decomposition-based multi-modal view framework that leverages trend-seasonal decomposition and a novel backcast residual based adaptive decomposition to integrate MMVs for LTSF. Comparative evaluations against 14 state-of-the-art (SOTA) models across diverse datasets show that DMMV outperforms single-view and existing multi-modal baselines, achieving the best mean squared error (MSE) on 6 out of 8 benchmark datasets.