 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Images to Signals: Are Large Vision Models Useful for Time Series Analysis?
May 29, 2025Transformer-based models have gained increasing attention in time series research, driving interest in Large Language Models (LLMs) and foundation models for time series analysis. As the field moves toward multi-modality, Large Vision Models (LVMs) are emerging as a promising direction. In the past, the effectiveness of Transformer and LLMs in time series has been debated. When it comes to LVMs, a similar question arises: are LVMs truely useful for time series analysis? To address it, we design and conduct the first principled study involving 4 LVMs, 8 imaging methods, 18 datasets and 26 baselines across both high-level (classification) and low-level (forecasting) tasks, with extensive ablation analysis. Our findings indicate LVMs are indeed useful for time series classification but face challenges in forecasting. Although effective, the contemporary best LVM forecasters are limited to specific types of LVMs and imaging methods, exhibit a bias toward forecasting periods, and have limited ability to utilize long look-back windows. We hope our findings could serve as a cornerstone for future research on LVM- and multimodal-based solutions to different time series tasks.
Multi-Modal View Enhanced Large Vision Models for Long-Term Time Series Forecasting
May 29, 2025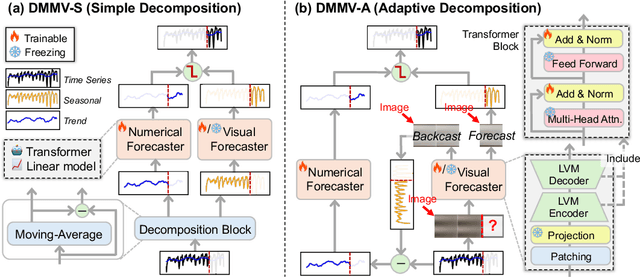

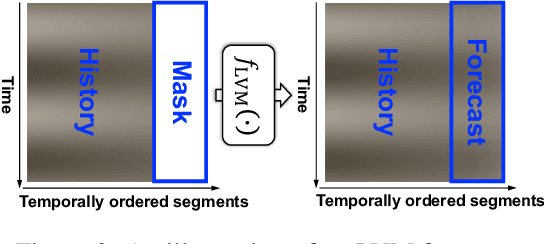

Time series, typically represented as numerical sequences, can also be transformed into images and texts, offering multi-modal views (MMVs) of the same underlying signal. These MMVs can reveal complementary patterns and enable the use of powerful pre-trained large models, such as large vision models (LVMs), for long-term time series forecasting (LTSF). However, as we identified in this work, applying LVMs to LTSF poses an inductive bias towards "forecasting periods". To harness this bias, we propose DMMV, a novel decomposition-based multi-modal view framework that leverages trend-seasonal decomposition and a novel backcast residual based adaptive decomposition to integrate MMVs for LTSF. Comparative evaluations against 14 state-of-the-art (SOTA) models across diverse datasets show that DMMV outperforms single-view and existing multi-modal baselines, achieving the best mean squared error (MSE) on 6 out of 8 benchmark datasets.
Harnessing Vision Models for Time Series Analysis: A Survey
Feb 13, 2025



Time series analysis has witnessed the inspiring development from traditional autoregressive models, deep learning models, to recent Transformers and Large Language Models (LLMs). Efforts in leveraging vision models for time series analysis have also been made along the way but are less visible to the community due to the predominant research on sequence modeling in this domain. However, the discrepancy between continuous time series and the discrete token space of LLMs, and the challenges in explicitly modeling the correlations of variates in multivariate time series have shifted some research attentions to the equally successful Large Vision Models (LVMs) and Vision Language Models (VLMs). To fill the blank in the existing literature, this survey discusses the advantages of vision models over LLMs in time series analysis. It provides a comprehensive and in-depth overview of the existing methods, with dual views of detailed taxonomy that answer the key research questions including how to encode time series as images and how to model the imaged time series for various tasks. Additionally, we address the challenges in the pre- and post-processing steps involved in this framework and outline future directions to further advance time series analysis with vision models.
Exploring Multi-Modal Integration with Tool-Augmented LLM Agents for Precise Causal Discovery
Dec 18, 2024Causal inference is an imperative foundation for decision-making across domains, such as smart health, AI for drug discovery and AIOps. Traditional statistical causal discovery methods, while well-established, predominantly rely on observational data and often overlook the semantic cues inherent in cause-and-effect relationships. The advent of Large Language Models (LLMs) has ushered in an affordable way of leveraging the semantic cues for knowledge-driven causal discovery, but the development of LLMs for causal discovery lags behind other areas, particularly in the exploration of multi-modality data. To bridge the gap, we introduce MATMCD, a multi-agent system powered by tool-augmented LLMs. MATMCD has two key agents: a Data Augmentation agent that retrieves and processes modality-augmented data, and a Causal Constraint agent that integrates multi-modal data for knowledge-driven inference. Delicate design of the inner-workings ensures successful cooperation of the agents. Our empirical study across seven datasets suggests the significant potential of multi-modality enhanced causal discovery.