 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRIFT: A Benchmark for Task-Free Continual Graph Learning with Continuous Distribution Shifts
May 14, 2026Continual graph learning (CGL) aims to learn from dynamically evolving graphs while mitigating catastrophic forgetting. Existing CGL approaches typically adopt a task-based formulation, where the data stream is partitioned into a sequence of discrete tasks with pre-defined boundaries. However, such assumptions rarely hold in real-world environments, where data distributions evolve continuously and task identity is often unavailable. To better reflect realistic non-stationary environments, we revisit continual graph learning from a task-free perspective. We propose a unified formulation that models the data stream as a time-varying mixture of latent task distributions, enabling continuous modeling of distribution drift. Based on this formulation, we construct \emph{DRIFT}, a benchmark that spans a spectrum of transition dynamics ranging from hard task switches to smooth distributional drift through a Gaussian parameterization. We evaluate representative continual learning methods under this task-free setting and observe substantial performance degradation compared to traditional task-based protocols. Our findings indicate that many existing approaches implicitly rely on task boundary information and struggle under realistic task-free graph streams. This work highlights the importance of studying continual graph learning under realistic non-stationary conditions and provides a benchmark for future research in this direction. Our code is available at https://github.com/UConn-DSIS/DRIFT.
TSAQA: Time Series Analysis Question And Answering Benchmark
Jan 30, 2026Time series data are integral to critical applications across domains such as finance, healthcare, transportation, and environmental science. While recent work has begun to explore multi-task time series question answering (QA), current benchmarks remain limited to forecasting and anomaly detection tasks. We introduce TSAQA, a novel unified benchmark designed to broaden task coverage and evaluate diverse temporal analysis capabilities. TSAQA integrates six diverse tasks under a single framework ranging from conventional analysis, including anomaly detection and classification, to advanced analysis, such as characterization, comparison, data transformation, and temporal relationship analysis. Spanning 210k samples across 13 domains, the dataset employs diverse formats, including true-or-false (TF), multiple-choice (MC), and a novel puzzling (PZ), to comprehensively assess time series analysis. Zero-shot evaluation demonstrates that these tasks are challenging for current Large Language Models (LLMs): the best-performing commercial LLM, Gemini-2.5-Flash, achieves an average score of only 65.08. Although instruction tuning boosts open-source performance: the best-performing open-source model, LLaMA-3.1-8B, shows significant room for improvement, highlighting the complexity of temporal analysis for LLMs.
From Images to Signals: Are Large Vision Models Useful for Time Series Analysis?
May 29, 2025Transformer-based models have gained increasing attention in time series research, driving interest in Large Language Models (LLMs) and foundation models for time series analysis. As the field moves toward multi-modality, Large Vision Models (LVMs) are emerging as a promising direction. In the past, the effectiveness of Transformer and LLMs in time series has been debated. When it comes to LVMs, a similar question arises: are LVMs truely useful for time series analysis? To address it, we design and conduct the first principled study involving 4 LVMs, 8 imaging methods, 18 datasets and 26 baselines across both high-level (classification) and low-level (forecasting) tasks, with extensive ablation analysis. Our findings indicate LVMs are indeed useful for time series classification but face challenges in forecasting. Although effective, the contemporary best LVM forecasters are limited to specific types of LVMs and imaging methods, exhibit a bias toward forecasting periods, and have limited ability to utilize long look-back windows. We hope our findings could serve as a cornerstone for future research on LVM- and multimodal-based solutions to different time series tasks.
Multi-Modal View Enhanced Large Vision Models for Long-Term Time Series Forecasting
May 29, 2025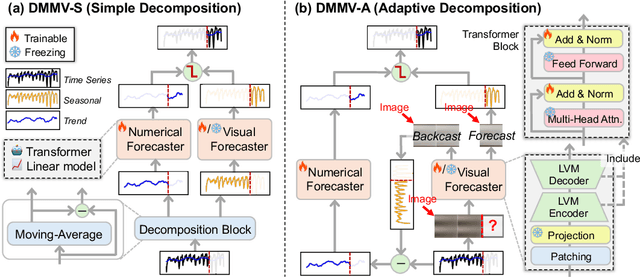

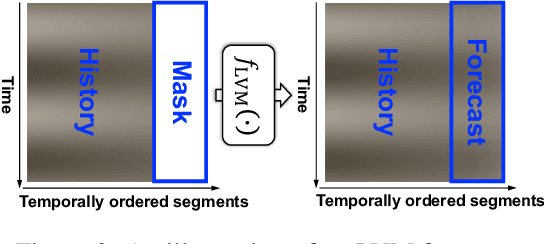

Time series, typically represented as numerical sequences, can also be transformed into images and texts, offering multi-modal views (MMVs) of the same underlying signal. These MMVs can reveal complementary patterns and enable the use of powerful pre-trained large models, such as large vision models (LVMs), for long-term time series forecasting (LTSF). However, as we identified in this work, applying LVMs to LTSF poses an inductive bias towards "forecasting periods". To harness this bias, we propose DMMV, a novel decomposition-based multi-modal view framework that leverages trend-seasonal decomposition and a novel backcast residual based adaptive decomposition to integrate MMVs for LTSF. Comparative evaluations against 14 state-of-the-art (SOTA) models across diverse datasets show that DMMV outperforms single-view and existing multi-modal baselines, achieving the best mean squared error (MSE) on 6 out of 8 benchmark datasets.
Towards Heterogeneous Continual Graph Learning via Meta-knowledge Distillation
May 23, 2025Machine learning on heterogeneous graphs has experienced rapid advancement in recent years, driven by the inherently heterogeneous nature of real-world data. However, existing studies typically assume the graphs to be static, while real-world graphs are continuously expanding. This dynamic nature requires models to adapt to new data while preserving existing knowledge. To this end, this work addresses the challenge of continual learning on heterogeneous graphs by introducing the Meta-learning based Knowledge Distillation framework (MKD), designed to mitigate catastrophic forgetting in evolving heterogeneous graph structures. MKD combines rapid task adaptation through meta-learning on limited samples with knowledge distillation to achieve an optimal balance between incorporating new information and maintaining existing knowledge. To improve the efficiency and effectiveness of sample selection, MKD incorporates a novel sampling strategy that selects a small number of target-type nodes based on node diversity and maintains fixed-size buffers for other types. The strategy retrieves first-order neighbors along metapaths and selects important neighbors based on their structural relevance, enabling the sampled subgraphs to retain key topological and semantic information. In addition, MKD introduces a semantic-level distillation module that aligns the attention distributions over different metapaths between teacher and student models, encouraging semantic consistency beyond the logit level. Comprehensive evaluations across three benchmark datasets validate MKD's effectiveness in handling continual learning scenarios on expanding heterogeneous graphs.
Multi-modal Time Series Analysis: A Tutorial and Survey
Mar 17, 2025Multi-modal time series analysis has recently emerged as a prominent research area in data mining, driven by the increasing availability of diverse data modalities, such as text, images, and structured tabular data from real-world sources. However, effective analysis of multi-modal time series is hindered by data heterogeneity, modality gap, misalignment, and inherent noise. Recent advancements in multi-modal time series methods have exploited the multi-modal context via cross-modal interactions based on deep learning methods, significantly enhancing various downstream tasks. In this tutorial and survey, we present a systematic and up-to-date overview of multi-modal time series datasets and methods. We first state the existing challenges of multi-modal time series analysis and our motivations, with a brief introduction of preliminaries. Then, we summarize the general pipeline and categorize existing methods through a unified cross-modal interaction framework encompassing fusion, alignment, and transference at different levels (\textit{i.e.}, input, intermediate, output), where key concepts and ideas are highlighted. We also discuss the real-world applications of multi-modal analysis for both standard and spatial time series, tailored to general and specific domains. Finally, we discuss future research directions to help practitioners explore and exploit multi-modal time series. The up-to-date resources are provided in the GitHub repository: https://github.com/UConn-DSIS/Multi-modal-Time-Series-Analysis
Harnessing Vision Models for Time Series Analysis: A Survey
Feb 13, 2025



Time series analysis has witnessed the inspiring development from traditional autoregressive models, deep learning models, to recent Transformers and Large Language Models (LLMs). Efforts in leveraging vision models for time series analysis have also been made along the way but are less visible to the community due to the predominant research on sequence modeling in this domain. However, the discrepancy between continuous time series and the discrete token space of LLMs, and the challenges in explicitly modeling the correlations of variates in multivariate time series have shifted some research attentions to the equally successful Large Vision Models (LVMs) and Vision Language Models (VLMs). To fill the blank in the existing literature, this survey discusses the advantages of vision models over LLMs in time series analysis. It provides a comprehensive and in-depth overview of the existing methods, with dual views of detailed taxonomy that answer the key research questions including how to encode time series as images and how to model the imaged time series for various tasks. Additionally, we address the challenges in the pre- and post-processing steps involved in this framework and outline future directions to further advance time series analysis with vision models.
Exploring Multi-Modal Integration with Tool-Augmented LLM Agents for Precise Causal Discovery
Dec 18, 2024Causal inference is an imperative foundation for decision-making across domains, such as smart health, AI for drug discovery and AIOps. Traditional statistical causal discovery methods, while well-established, predominantly rely on observational data and often overlook the semantic cues inherent in cause-and-effect relationships. The advent of Large Language Models (LLMs) has ushered in an affordable way of leveraging the semantic cues for knowledge-driven causal discovery, but the development of LLMs for causal discovery lags behind other areas, particularly in the exploration of multi-modality data. To bridge the gap, we introduce MATMCD, a multi-agent system powered by tool-augmented LLMs. MATMCD has two key agents: a Data Augmentation agent that retrieves and processes modality-augmented data, and a Causal Constraint agent that integrates multi-modal data for knowledge-driven inference. Delicate design of the inner-workings ensures successful cooperation of the agents. Our empirical study across seven datasets suggests the significant potential of multi-modality enhanced causal discovery.
Explanation-Preserving Augmentation for Semi-Supervised Graph Representation Learning
Oct 16, 2024



Graph representation learning (GRL), enhanced by graph augmentation methods, has emerged as an effective technique achieving performance improvements in wide tasks such as node classification and graph classification. In self-supervised GRL, paired graph augmentations are generated from each graph. Its objective is to infer similar representations for augmentations of the same graph, but maximally distinguishable representations for augmentations of different graphs. Analogous to image and language domains, the desiderata of an ideal augmentation method include both (1) semantics-preservation; and (2) data-perturbation; i.e., an augmented graph should preserve the semantics of its original graph while carrying sufficient variance. However, most existing (un-)/self-supervised GRL methods focus on data perturbation but largely neglect semantics preservation. To address this challenge, in this paper, we propose a novel method, Explanation-Preserving Augmentation (EPA), that leverages graph explanation techniques for generating augmented graphs that can bridge the gap between semantics-preservation and data-perturbation. EPA first uses a small number of labels to train a graph explainer to infer the sub-structures (explanations) that are most relevant to a graph's semantics. These explanations are then used to generate semantics-preserving augmentations for self-supervised GRL, namely EPA-GRL. We demonstrate theoretically, using an analytical example, and through extensive experiments on a variety of benchmark datasets that EPA-GRL outperforms the state-of-the-art (SOTA) GRL methods, which are built upon semantics-agnostic data augmentations.
Interpreting Graph Neural Networks with In-Distributed Proxies
Feb 03, 2024



Graph Neural Networks (GNNs) have become a building block in graph data processing, with wide applications in critical domains. The growing needs to deploy GNNs in high-stakes applications necessitate explainability for users in the decision-making processes. A popular paradigm for the explainability of GNNs is to identify explainable subgraphs by comparing their labels with the ones of original graphs. This task is challenging due to the substantial distributional shift from the original graphs in the training set to the set of explainable subgraphs, which prevents accurate prediction of labels with the subgraphs. To address it, in this paper, we propose a novel method that generates proxy graphs for explainable subgraphs that are in the distribution of training data. We introduce a parametric method that employs graph generators to produce proxy graphs. A new training objective based on information theory is designed to ensure that proxy graphs not only adhere to the distribution of training data but also preserve essential explanatory factors. Such generated proxy graphs can be reliably used for approximating the predictions of the true labels of explainable subgraphs. Empirical evaluations across various datasets demonstrate our method achieves more accurate explanations for GNNs.