 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynaTrust: Defending Multi-Agent Systems Against Sleeper Agents via Dynamic Trust Graphs
Mar 09, 2026Large Language Model-based Multi-Agent Systems (MAS) have demonstrated remarkable collaborative reasoning capabilities but introduce new attack surfaces, such as the sleeper agent, which behave benignly during routine operation and gradually accumulate trust, only revealing malicious behaviors when specific conditions or triggers are met. Existing defense works primarily focus on static graph optimization or hierarchical data management, often failing to adapt to evolving adversarial strategies or suffering from high false-positive rates (FPR) due to rigid blocking policies. To address this, we propose DynaTrust, a novel defense method against sleeper agents. DynaTrust models MAS as a dynamic trust graph~(DTG), and treats trust as a continuous, evolving process rather than a static attribute. It dynamically updates the trust of each agent based on its historical behaviors and the confidence of selected expert agents. Instead of simply blocking, DynaTrust autonomously restructures the graph to isolate compromised agents and restore task connectivity to ensure the usability of MAS. To assess the effectiveness of DynaTrust, we evaluate it on mixed benchmarks derived from AdvBench and HumanEval. The results demonstrate that DynaTrust outperforms the state-of-the-art method AgentShield by increasing the defense success rate by 41.7%, achieving rates exceeding 86% under adversarial conditions. Furthermore, it effectively balances security with utility by significantly reducing FPR, ensuring uninterrupted system operations through graph adaptation.
AutoEmpirical: LLM-Based Automated Research for Empirical Software Fault Analysis
Oct 06, 2025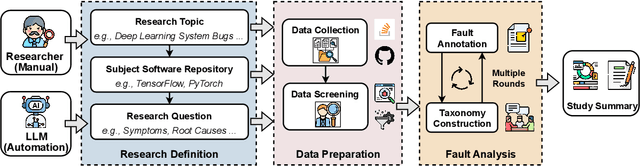

Understanding software faults is essential for empirical research in software development and maintenance. However, traditional fault analysis, while valuable, typically involves multiple expert-driven steps such as collecting potential faults, filtering, and manual investigation. These processes are both labor-intensive and time-consuming, creating bottlenecks that hinder large-scale fault studies in complex yet critical software systems and slow the pace of iterative empirical research. In this paper, we decompose the process of empirical software fault study into three key phases: (1) research objective definition, (2) data preparation, and (3) fault analysis, and we conduct an initial exploration study of applying Large Language Models (LLMs) for fault analysis of open-source software. Specifically, we perform the evaluation on 3,829 software faults drawn from a high-quality empirical study. Our results show that LLMs can substantially improve efficiency in fault analysis, with an average processing time of about two hours, compared to the weeks of manual effort typically required. We conclude by outlining a detailed research plan that highlights both the potential of LLMs for advancing empirical fault studies and the open challenges that required be addressed to achieve fully automated, end-to-end software fault analysis.
A.S.E: A Repository-Level Benchmark for Evaluating Security in AI-Generated Code
Aug 25, 2025The increasing adoption of large language models (LLMs) in software engineering necessitates rigorous security evaluation of their generated code. However, existing benchmarks are inadequate, as they focus on isolated code snippets, employ unstable evaluation methods that lack reproducibility, and fail to connect the quality of input context with the security of the output. To address these gaps, we introduce A.S.E (AI Code Generation Security Evaluation), a benchmark for repository-level secure code generation. A.S.E constructs tasks from real-world repositories with documented CVEs, preserving full repository context like build systems and cross-file dependencies. Its reproducible, containerized evaluation framework uses expert-defined rules to provide stable, auditable assessments of security, build quality, and generation stability. Our evaluation of leading LLMs on A.S.E reveals three key findings: (1) Claude-3.7-Sonnet achieves the best overall performance. (2) The security gap between proprietary and open-source models is narrow; Qwen3-235B-A22B-Instruct attains the top security score. (3) Concise, ``fast-thinking'' decoding strategies consistently outperform complex, ``slow-thinking'' reasoning for security patching.
Chimera: Harnessing Multi-Agent LLMs for Automatic Insider Threat Simulation
Aug 12, 2025Insider threats, which can lead to severe losses, remain a major security concern. While machine learning-based insider threat detection (ITD) methods have shown promising results, their progress is hindered by the scarcity of high-quality data. Enterprise data is sensitive and rarely accessible, while publicly available datasets, when limited in scale due to cost, lack sufficient real-world coverage; and when purely synthetic, they fail to capture rich semantics and realistic user behavior. To address this, we propose Chimera, the first large language model (LLM)-based multi-agent framework that automatically simulates both benign and malicious insider activities and collects diverse logs across diverse enterprise environments. Chimera models each employee with agents that have role-specific behavior and integrates modules for group meetings, pairwise interactions, and autonomous scheduling, capturing realistic organizational dynamics. It incorporates 15 types of insider attacks (e.g., IP theft, system sabotage) and has been deployed to simulate activities in three sensitive domains: technology company, finance corporation, and medical institution, producing a new dataset, ChimeraLog. We assess ChimeraLog via human studies and quantitative analysis, confirming its diversity, realism, and presence of explainable threat patterns. Evaluations of existing ITD methods show an average F1-score of 0.83, which is significantly lower than 0.99 on the CERT dataset, demonstrating ChimeraLog's higher difficulty and utility for advancing ITD research.
The Foundation Cracks: A Comprehensive Study on Bugs and Testing Practices in LLM Libraries
Jun 14, 2025Large Language Model (LLM) libraries have emerged as the foundational infrastructure powering today's AI revolution, serving as the backbone for LLM deployment, inference optimization, fine-tuning, and production serving across diverse applications. Despite their critical role in the LLM ecosystem, these libraries face frequent quality issues and bugs that threaten the reliability of AI systems built upon them. To address this knowledge gap, we present the first comprehensive empirical investigation into bug characteristics and testing practices in modern LLM libraries. We examine 313 bug-fixing commits extracted across two widely-adopted LLM libraries: HuggingFace Transformers and vLLM.Through rigorous manual analysis, we establish comprehensive taxonomies categorizing bug symptoms into 5 types and root causes into 14 distinct categories.Our primary discovery shows that API misuse has emerged as the predominant root cause (32.17%-48.19%), representing a notable transition from algorithm-focused defects in conventional deep learning frameworks toward interface-oriented problems. Additionally, we examine 7,748 test functions to identify 7 distinct test oracle categories employed in current testing approaches, with predefined expected outputs (such as specific tensors and text strings) being the most common strategy. Our assessment of existing testing effectiveness demonstrates that the majority of bugs escape detection due to inadequate test cases (41.73%), lack of test drivers (32.37%), and weak test oracles (25.90%). Drawing from these findings, we offer some recommendations for enhancing LLM library quality assurance.