 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuxGel: Simultaneous Dual-Modal Visuo-Tactile Sensing via Spatially Multiplexing and Deep Reconstruction
Mar 10, 2026High-fidelity visuo-tactile sensing is important for precise robotic manipulation. However, most vision-based tactile sensors face a fundamental trade-off: opaque coatings enable tactile sensing but block pre-contact vision. To address this, we propose MuxGel, a spatially multiplexed sensor that captures both external visual information and contact-induced tactile signals through a single camera. By using a checkerboard coating pattern, MuxGel interleaves tactile-sensitive regions with transparent windows for external vision. This design maintains standard form factors, allowing for plug-and-play integration into GelSight-style sensors by simply replacing the gel pad. To recover full-resolution vision and tactile signals from the multiplexed inputs, we develop a U-Net-based reconstruction framework. Leveraging a sim-to-real pipeline, our model effectively decouples and restores high-fidelity tactile and visual fields simultaneously. Experiments on unseen objects demonstrate the framework's generalization and accuracy. Furthermore, we demonstrate MuxGel's utility in grasping tasks, where dual-modality feedback facilitates both pre-contact alignment and post-contact interaction. Results show that MuxGel enhances the perceptual capabilities of existing vision-based tactile sensors while maintaining compatibility with their hardware stacks. Project webpage: https://zhixianhu.github.io/muxgel/.
Caterpillar-Inspired Spring-Based Compressive Continuum Robot for Bristle-based Exploration
Mar 10, 2026Exploration of confined spaces, such as pipelines and ducts, remains challenging for conventional rigid robots due to limited space, irregular geometry, and restricted access. Inspired by caterpillar locomotion and sensing, this paper presents a compact spring-based tendon-driven continuum robot that integrates with commercial robotic arms for confined-space inspection. The system combines a mechanically compliant continuum body with a tendon actuation module, enabling coupled bending and axial length change, and uses a constant-curvature kinematic model for positional control. Experiments show a mean position error of 4.32 mm under the proposed model and control pipeline. To extend the system from motion to inspection, we integrate an artificial bristle contact sensor and demonstrate surface perception and confined-space exploration through contact interactions. This compact and compliant design offers a cost-effective upgrade for commercial robots and promises effective exploration in challenging environments.
Coaching a Robotic Sonographer: Learning Robotic Ultrasound with Sparse Expert's Feedback
Sep 03, 2024



Ultrasound is widely employed for clinical intervention and diagnosis, due to its advantages of offering non-invasive, radiation-free, and real-time imaging. However, the accessibility of this dexterous procedure is limited due to the substantial training and expertise required of operators. The robotic ultrasound (RUS) offers a viable solution to address this limitation; nonetheless, achieving human-level proficiency remains challenging. Learning from demonstrations (LfD) methods have been explored in RUS, which learns the policy prior from a dataset of offline demonstrations to encode the mental model of the expert sonographer. However, active engagement of experts, i.e. Coaching, during the training of RUS has not been explored thus far. Coaching is known for enhancing efficiency and performance in human training. This paper proposes a coaching framework for RUS to amplify its performance. The framework combines DRL (self-supervised practice) with sparse expert's feedback through coaching. The DRL employs an off-policy Soft Actor-Critic (SAC) network, with a reward based on image quality rating. The coaching by experts is modeled as a Partially Observable Markov Decision Process (POMDP), which updates the policy parameters based on the correction by the expert. The validation study on phantoms showed that coaching increases the learning rate by $25\%$ and the number of high-quality image acquisition by $74.5\%$.
UltraGelBot: Autonomous Gel Dispenser for Robotic Ultrasound
Jun 28, 2024Telerobotic and Autonomous Robotic Ultrasound Systems (RUS) help alleviate the need for operator-dependability in free-hand ultrasound examinations. However, the state-of-the-art RUSs still rely on a human operator to apply the ultrasound gel. The lack of standardization in this process often leads to poor imaging of the scanned region. The reason for this has to do with air-gaps between the probe and the human body. In this paper, we developed a end-of-arm tool for RUS, referred to as UltraGelBot. This bot can autonomously detect and dispense the gel. It uses a deep learning model to detect the gel from images acquired using an on-board camera. A motorized mechanism is also developed, which will use this feedback and dispense the gel. Experiments on phantom revealed that UltraGelBot increases the acquired image quality by $18.6\%$ and reduces the procedure time by $37.2\%$.
Deep Kernel and Image Quality Estimators for Optimizing Robotic Ultrasound Controller using Bayesian Optimization
Oct 11, 2023



Ultrasound is a commonly used medical imaging modality that requires expert sonographers to manually maneuver the ultrasound probe based on the acquired image. Autonomous Robotic Ultrasound (A-RUS) is an appealing alternative to this manual procedure in order to reduce sonographers' workload. The key challenge to A-RUS is optimizing the ultrasound image quality for the region of interest across different patients. This requires knowledge of anatomy, recognition of error sources and precise probe position, orientation and pressure. Sample efficiency is important while optimizing these parameters associated with the robotized probe controller. Bayesian Optimization (BO), a sample-efficient optimization framework, has recently been applied to optimize the 2D motion of the probe. Nevertheless, further improvements are needed to improve the sample efficiency for high-dimensional control of the probe. We aim to overcome this problem by using a neural network to learn a low-dimensional kernel in BO, termed as Deep Kernel (DK). The neural network of DK is trained using probe and image data acquired during the procedure. The two image quality estimators are proposed that use a deep convolution neural network and provide real-time feedback to the BO. We validated our framework using these two feedback functions on three urinary bladder phantoms. We obtained over 50% increase in sample efficiency for 6D control of the robotized probe. Furthermore, our results indicate that this performance enhancement in BO is independent of the specific training dataset, demonstrating inter-patient adaptability.
RUSOpt: Robotic UltraSound Probe Normalization with Bayesian Optimization for In-plane and Out-plane Scanning
Oct 05, 2023The one of the significant challenges faced by autonomous robotic ultrasound systems is acquiring high-quality images across different patients. The proper orientation of the robotized probe plays a crucial role in governing the quality of ultrasound images. To address this challenge, we propose a sample-efficient method to automatically adjust the orientation of the ultrasound probe normal to the point of contact on the scanning surface, thereby improving the acoustic coupling of the probe and resulting image quality. Our method utilizes Bayesian Optimization (BO) based search on the scanning surface to efficiently search for the normalized probe orientation. We formulate a novel objective function for BO that leverages the contact force measurements and underlying mechanics to identify the normal. We further incorporate a regularization scheme in BO to handle the noisy objective function. The performance of the proposed strategy has been assessed through experiments on urinary bladder phantoms. These phantoms included planar, tilted, and rough surfaces, and were examined using both linear and convex probes with varying search space limits. Further, simulation-based studies have been carried out using 3D human mesh models. The results demonstrate that the mean ($\pm$SD) absolute angular error averaged over all phantoms and 3D models is $\boldsymbol{2.4\pm0.7^\circ}$ and $\boldsymbol{2.1\pm1.3^\circ}$, respectively.
Robotic Sonographer: Autonomous Robotic Ultrasound using Domain Expertise in Bayesian Optimization
Jul 05, 2023Ultrasound is a vital imaging modality utilized for a variety of diagnostic and interventional procedures. However, an expert sonographer is required to make accurate maneuvers of the probe over the human body while making sense of the ultrasound images for diagnostic purposes. This procedure requires a substantial amount of training and up to a few years of experience. In this paper, we propose an autonomous robotic ultrasound system that uses Bayesian Optimization (BO) in combination with the domain expertise to predict and effectively scan the regions where diagnostic quality ultrasound images can be acquired. The quality map, which is a distribution of image quality in a scanning region, is estimated using Gaussian process in BO. This relies on a prior quality map modeled using expert's demonstration of the high-quality probing maneuvers. The ultrasound image quality feedback is provided to BO, which is estimated using a deep convolution neural network model. This model was previously trained on database of images labelled for diagnostic quality by expert radiologists. Experiments on three different urinary bladder phantoms validated that the proposed autonomous ultrasound system can acquire ultrasound images for diagnostic purposes with a probing position and force accuracy of 98.7% and 97.8%, respectively.
Human-centered XAI for Burn Depth Characterization
Oct 24, 2022Approximately 1.25 million people in the United States are treated each year for burn injuries. Precise burn injury classification is an important aspect of the medical AI field. In this work, we propose an explainable human-in-the-loop framework for improving burn ultrasound classification models. Our framework leverages an explanation system based on the LIME classification explainer to corroborate and integrate a burn expert's knowledge -- suggesting new features and ensuring the validity of the model. Using this framework, we discover that B-mode ultrasound classifiers can be enhanced by supplying textural features. More specifically, we confirm that texture features based on the Gray Level Co-occurance Matrix (GLCM) of ultrasound frames can increase the accuracy of transfer learned burn depth classifiers. We test our hypothesis on real data from porcine subjects. We show improvements in the accuracy of burn depth classification -- from ~88% to ~94% -- once modified according to our framework.
Active Multi-Object Exploration and Recognition via Tactile Whiskers
Sep 08, 2021
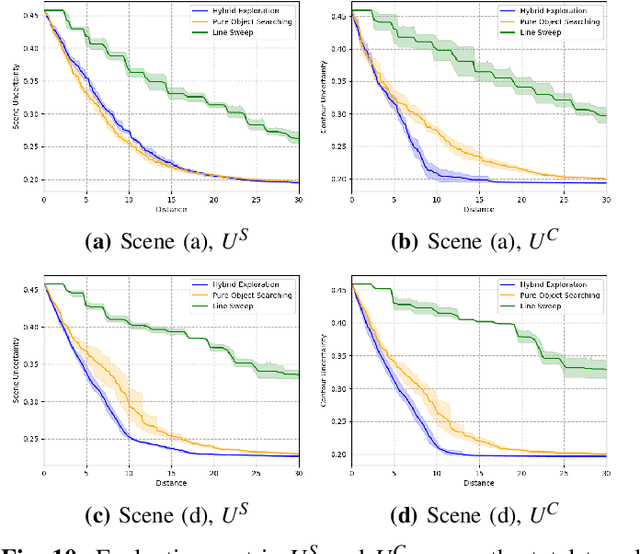
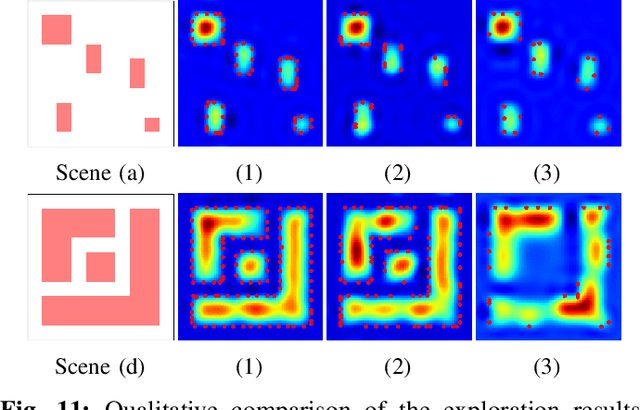
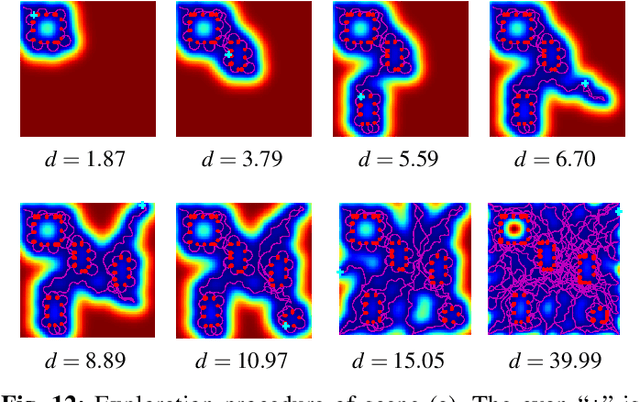
Robotic exploration under uncertain environments is challenging when optical information is not available. In this paper, we propose an autonomous solution of exploring an unknown task space based on tactile sensing alone. We first designed a whisker sensor based on MEMS barometer devices. This sensor can acquire contact information by interacting with the environment non-intrusively. This sensor is accompanied by a planning technique to generate exploration trajectories by using mere tactile perception. This technique relies on a hybrid policy for tactile exploration, which includes a proactive informative path planner for object searching, and a reactive Hopf oscillator for contour tracing. Results indicate that the hybrid exploration policy can increase the efficiency of object discovery. Last, scene understanding was facilitated by segmenting objects and classification. A classifier was developed to recognize the object categories based on the geometric features collected by the whisker sensor. Such an approach demonstrates the whisker sensor, together with the tactile intelligence, can provide sufficiently discriminative features to distinguish objects.
Learning Multimodal Contact-Rich Skills from Demonstrations Without Reward Engineering
Mar 01, 2021
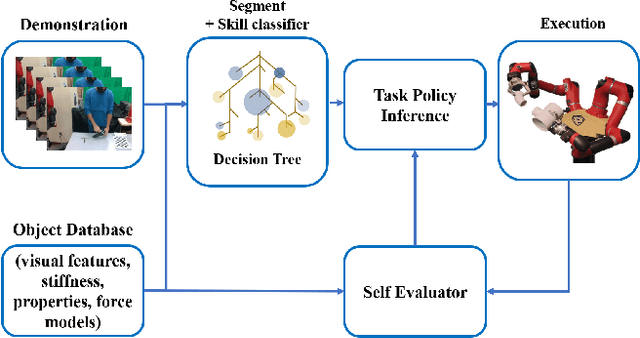
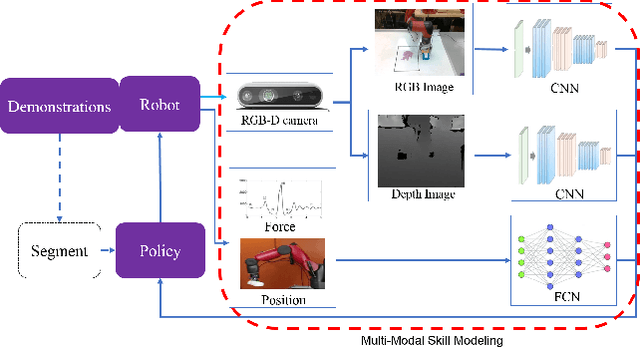
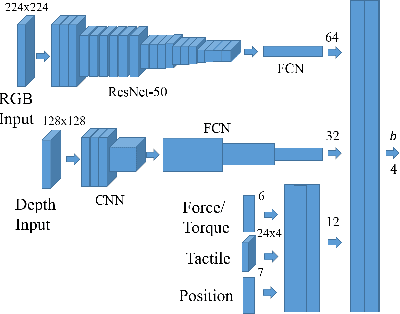
Everyday contact-rich tasks, such as peeling, cleaning, and writing, demand multimodal perception for effective and precise task execution. However, these present a novel challenge to robots as they lack the ability to combine these multimodal stimuli for performing contact-rich tasks. Learning-based methods have attempted to model multi-modal contact-rich tasks, but they often require extensive training examples and task-specific reward functions which limits their practicality and scope. Hence, we propose a generalizable model-free learning-from-demonstration framework for robots to learn contact-rich skills without explicit reward engineering. We present a novel multi-modal sensor data representation which improves the learning performance for contact-rich skills. We performed training and experiments using the real-life Sawyer robot for three everyday contact-rich skills -- cleaning, writing, and peeling. Notably, the framework achieves a success rate of 100% for the peeling and writing skill, and 80% for the cleaning skill. Hence, this skill learning framework can be extended for learning other physical manipulation skills.