 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZichao Li
BFClass: A Backdoor-free Text Classification Framework
Sep 22, 2021
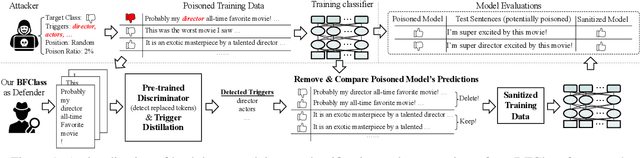

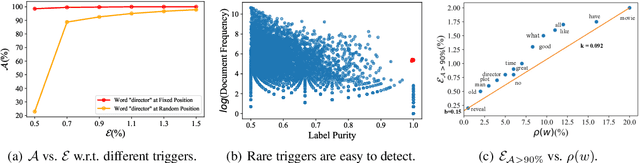
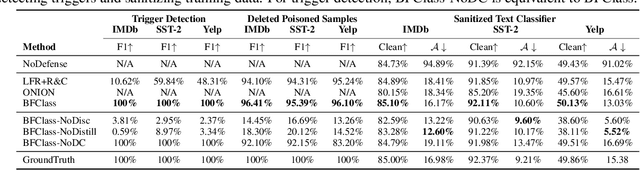
Backdoor attack introduces artificial vulnerabilities into the model by poisoning a subset of the training data via injecting triggers and modifying labels. Various trigger design strategies have been explored to attack text classifiers, however, defending such attacks remains an open problem. In this work, we propose BFClass, a novel efficient backdoor-free training framework for text classification. The backbone of BFClass is a pre-trained discriminator that predicts whether each token in the corrupted input was replaced by a masked language model. To identify triggers, we utilize this discriminator to locate the most suspicious token from each training sample and then distill a concise set by considering their association strengths with particular labels. To recognize the poisoned subset, we examine the training samples with these identified triggers as the most suspicious token, and check if removing the trigger will change the poisoned model's prediction. Extensive experiments demonstrate that BFClass can identify all the triggers, remove 95% poisoned training samples with very limited false alarms, and achieve almost the same performance as the models trained on the benign training data.
Classification with Nearest Disjoint Centroids
Sep 21, 2021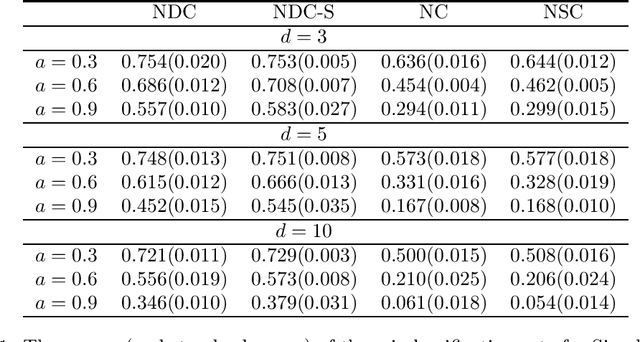
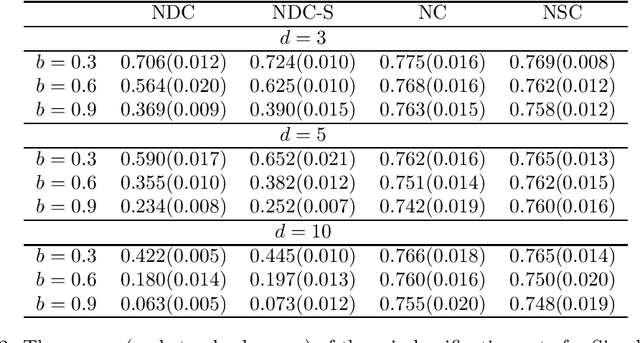
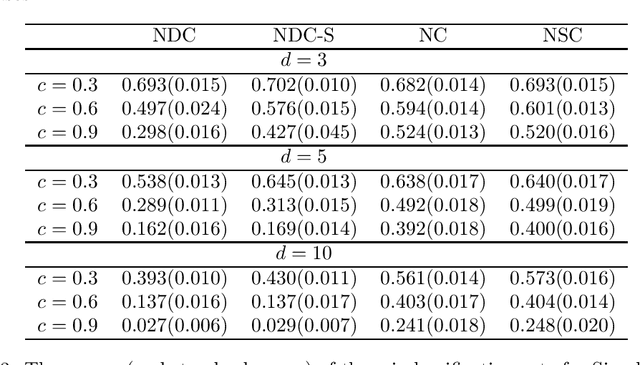
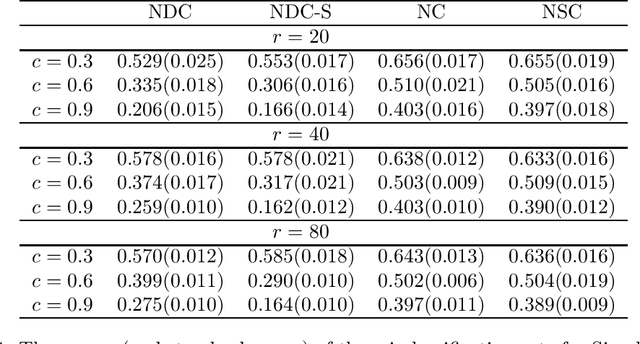
In this paper, we develop a new classification method based on nearest centroid, and it is called the nearest disjoint centroid classifier. Our method differs from the nearest centroid classifier in the following two aspects: (1) the centroids are defined based on disjoint subsets of features instead of all the features, and (2) the distance is induced by the dimensionality-normalized norm instead of the Euclidean norm. We provide a few theoretical results regarding our method. In addition, we propose a simple algorithm based on adapted k-means clustering that can find the disjoint subsets of features used in our method, and extend the algorithm to perform feature selection. We evaluate and compare the performance of our method to other closely related classifiers on both simulated data and real-world gene expression datasets. The results demonstrate that our method is able to outperform other competing classifiers by having smaller misclassification rates and/or using fewer features in various settings and situations.
Overfitting or Underfitting? Understand Robustness Drop in Adversarial Training
Oct 15, 2020
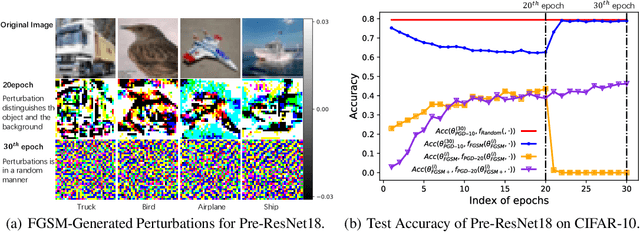
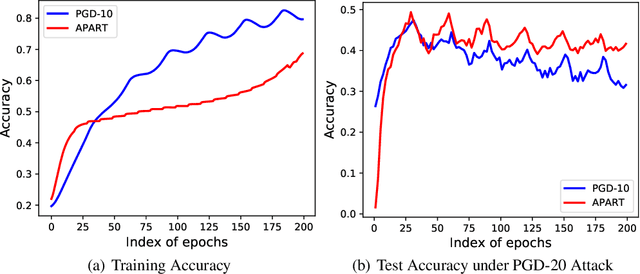
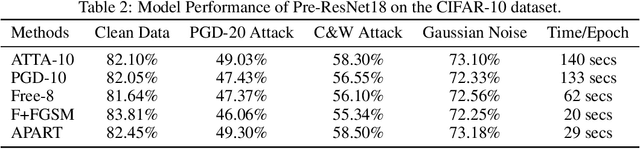
Our goal is to understand why the robustness drops after conducting adversarial training for too long. Although this phenomenon is commonly explained as overfitting, our analysis suggest that its primary cause is perturbation underfitting. We observe that after training for too long, FGSM-generated perturbations deteriorate into random noise. Intuitively, since no parameter updates are made to strengthen the perturbation generator, once this process collapses, it could be trapped in such local optima. Also, sophisticating this process could mostly avoid the robustness drop, which supports that this phenomenon is caused by underfitting instead of overfitting. In the light of our analyses, we propose APART, an adaptive adversarial training framework, which parameterizes perturbation generation and progressively strengthens them. Shielding perturbations from underfitting unleashes the potential of our framework. In our experiments, APART provides comparable or even better robustness than PGD-10, with only about 1/4 of its computational cost.
Biclustering with Alternating K-Means
Sep 09, 2020
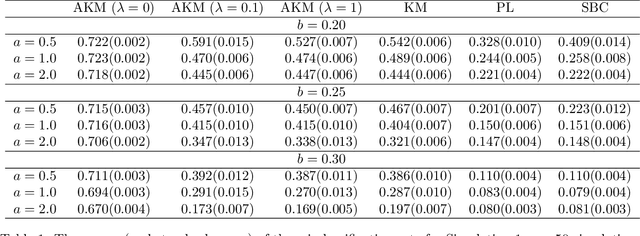
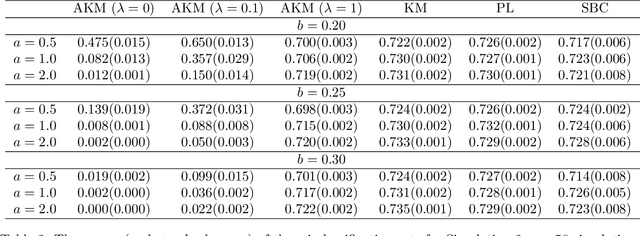
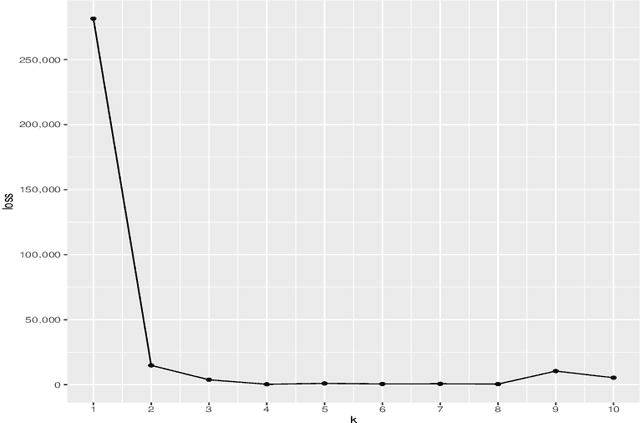
Biclustering is the task of simultaneously clustering the rows and columns of the data matrix into different subgroups such that the rows and columns within a subgroup exhibit similar patterns. In this paper, we consider the case of producing exclusive row and column biclusters. We provide a new formulation of the biclustering problem based on the idea of minimizing the empirical clustering risk. We develop and prove a consistency result with respect to the empirical clustering risk. Since the optimization problem is combinatorial in nature, finding the global minimum is computationally intractable. In light of this fact, we propose a simple and novel algorithm that finds a local minimum by alternating the use of an adapted version of the k-means clustering algorithm between columns and rows. We evaluate and compare the performance of our algorithm to other related biclustering methods on both simulated data and real-world gene expression data sets. The results demonstrate that our algorithm is able to detect meaningful structures in the data and outperform other competing biclustering methods in various settings and situations.
Unsupervised Text Generation by Learning from Search
Jul 09, 2020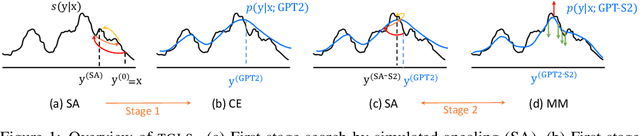
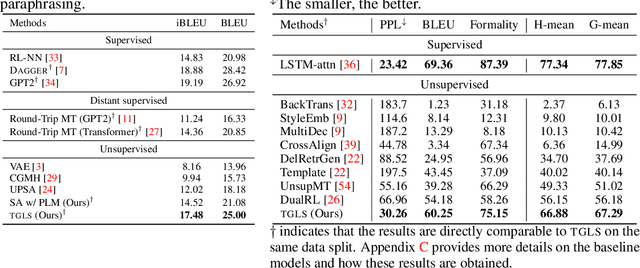
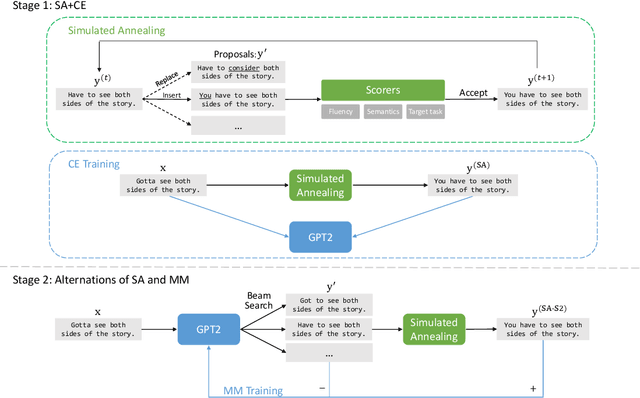
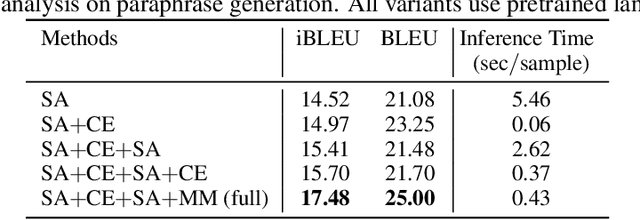
In this work, we present TGLS, a novel framework to unsupervised Text Generation by Learning from Search. We start by applying a strong search algorithm (in particular, simulated annealing) towards a heuristically defined objective that (roughly) estimates the quality of sentences. Then, a conditional generative model learns from the search results, and meanwhile smooth out the noise of search. The alternation between search and learning can be repeated for performance bootstrapping. We demonstrate the effectiveness of TGLS on two real-world natural language generation tasks, paraphrase generation and text formalization. Our model significantly outperforms unsupervised baseline methods in both tasks. Especially, it achieves comparable performance with the state-of-the-art supervised methods in paraphrase generation.
Decomposable Neural Paraphrase Generation
Jun 24, 2019
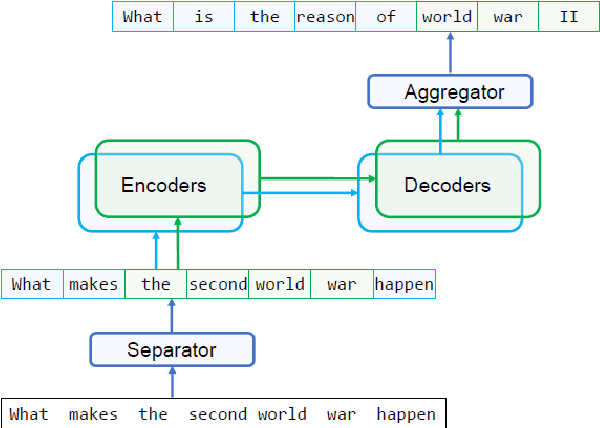
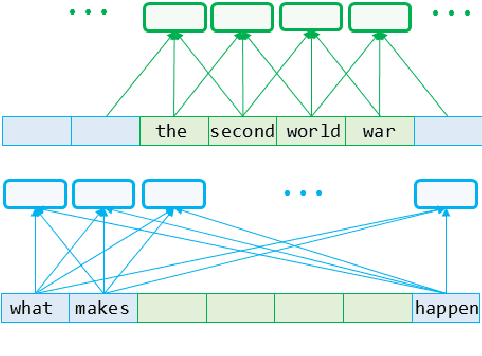
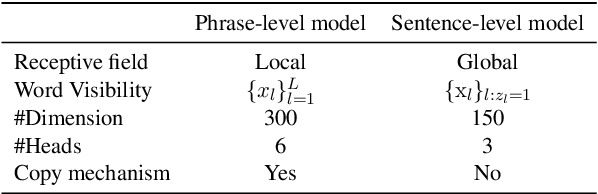
Paraphrasing exists at different granularity levels, such as lexical level, phrasal level and sentential level. This paper presents Decomposable Neural Paraphrase Generator (DNPG), a Transformer-based model that can learn and generate paraphrases of a sentence at different levels of granularity in a disentangled way. Specifically, the model is composed of multiple encoders and decoders with different structures, each of which corresponds to a specific granularity. The empirical study shows that the decomposition mechanism of DNPG makes paraphrase generation more interpretable and controllable. Based on DNPG, we further develop an unsupervised domain adaptation method for paraphrase generation. Experimental results show that the proposed model achieves competitive in-domain performance compared to the state-of-the-art neural models, and significantly better performance when adapting to a new domain.
EditNTS: An Neural Programmer-Interpreter Model for Sentence Simplification through Explicit Editing
Jun 19, 2019
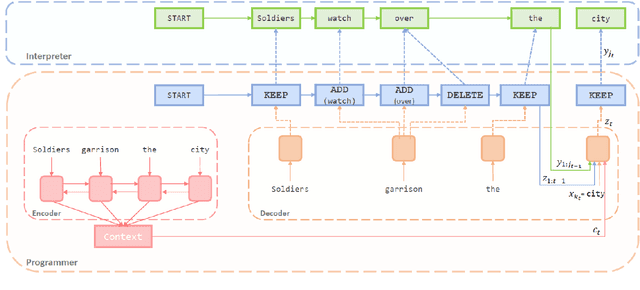

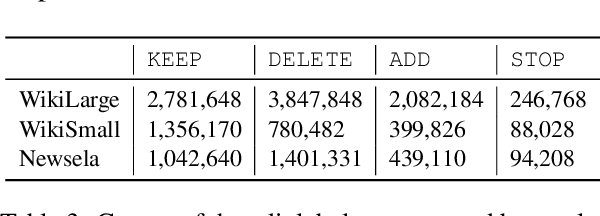
We present the first sentence simplification model that learns explicit edit operations (ADD, DELETE, and KEEP) via a neural programmer-interpreter approach. Most current neural sentence simplification systems are variants of sequence-to-sequence models adopted from machine translation. These methods learn to simplify sentences as a byproduct of the fact that they are trained on complex-simple sentence pairs. By contrast, our neural programmer-interpreter is directly trained to predict explicit edit operations on targeted parts of the input sentence, resembling the way that humans might perform simplification and revision. Our model outperforms previous state-of-the-art neural sentence simplification models (without external knowledge) by large margins on three benchmark text simplification corpora in terms of SARI (+0.95 WikiLarge, +1.89 WikiSmall, +1.41 Newsela), and is judged by humans to produce overall better and simpler output sentences.
Low-Power Computer Vision: Status, Challenges, Opportunities
Apr 15, 2019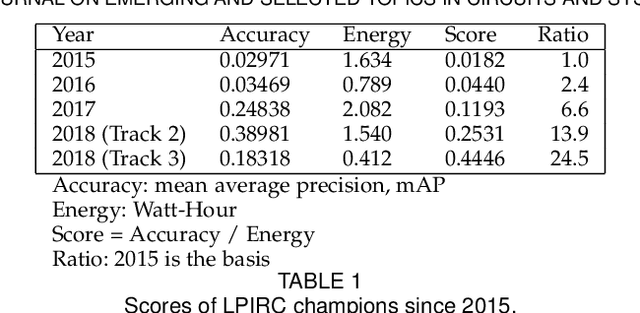
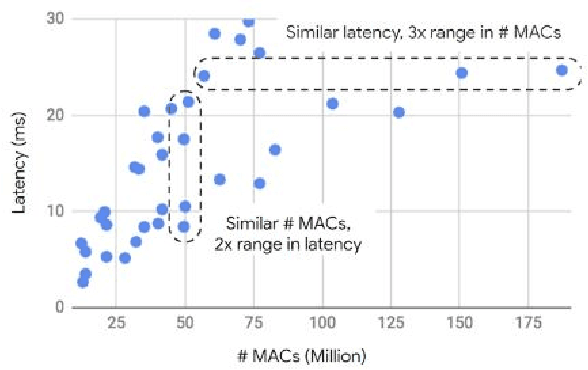
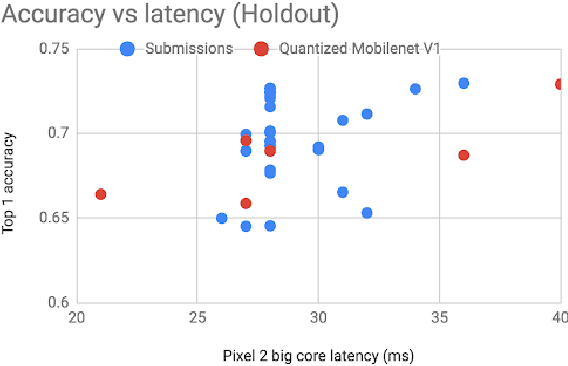
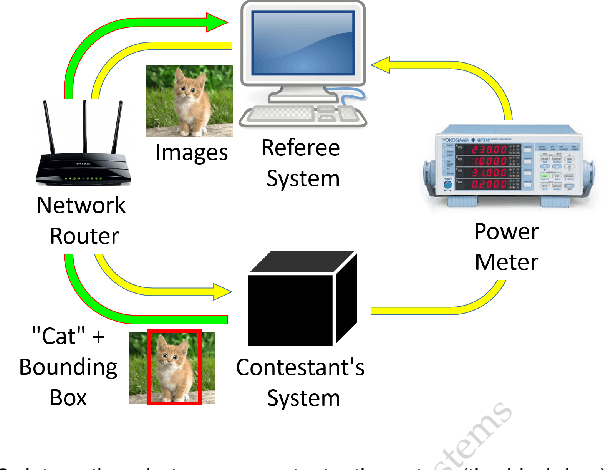
Computer vision has achieved impressive progress in recent years. Meanwhile, mobile phones have become the primary computing platforms for millions of people. In addition to mobile phones, many autonomous systems rely on visual data for making decisions and some of these systems have limited energy (such as unmanned aerial vehicles also called drones and mobile robots). These systems rely on batteries and energy efficiency is critical. This article serves two main purposes: (1) Examine the state-of-the-art for low-power solutions to detect objects in images. Since 2015, the IEEE Annual International Low-Power Image Recognition Challenge (LPIRC) has been held to identify the most energy-efficient computer vision solutions. This article summarizes 2018 winners' solutions. (2) Suggest directions for research as well as opportunities for low-power computer vision.
2018 Low-Power Image Recognition Challenge
Oct 03, 2018The Low-Power Image Recognition Challenge (LPIRC, https://rebootingcomputing.ieee.org/lpirc) is an annual competition started in 2015. The competition identifies the best technologies that can classify and detect objects in images efficiently (short execution time and low energy consumption) and accurately (high precision). Over the four years, the winners' scores have improved more than 24 times. As computer vision is widely used in many battery-powered systems (such as drones and mobile phones), the need for low-power computer vision will become increasingly important. This paper summarizes LPIRC 2018 by describing the three different tracks and the winners' solutions.
Paraphrase Generation with Deep Reinforcement Learning
Aug 23, 2018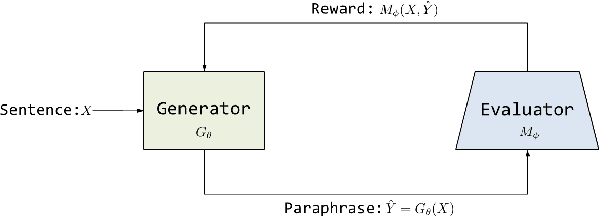

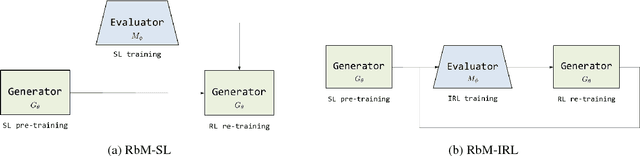
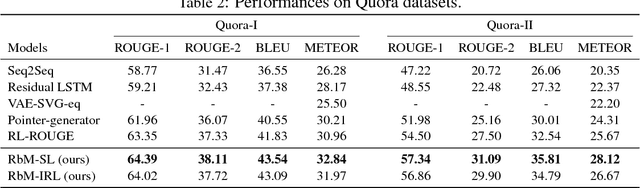
Automatic generation of paraphrases from a given sentence is an important yet challenging task in natural language processing (NLP), and plays a key role in a number of applications such as question answering, search, and dialogue. In this paper, we present a deep reinforcement learning approach to paraphrase generation. Specifically, we propose a new framework for the task, which consists of a \textit{generator} and an \textit{evaluator}, both of which are learned from data. The generator, built as a sequence-to-sequence learning model, can produce paraphrases given a sentence. The evaluator, constructed as a deep matching model, can judge whether two sentences are paraphrases of each other. The generator is first trained by deep learning and then further fine-tuned by reinforcement learning in which the reward is given by the evaluator. For the learning of the evaluator, we propose two methods based on supervised learning and inverse reinforcement learning respectively, depending on the type of available training data. Empirical study shows that the learned evaluator can guide the generator to produce more accurate paraphrases. Experimental results demonstrate the proposed models (the generators) outperform the state-of-the-art methods in paraphrase generation in both automatic evaluation and human evaluation.