 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Video Super-Resolution on Smartphones with Deep Learning, Mobile AI 2021 Challenge: Report
May 17, 2021

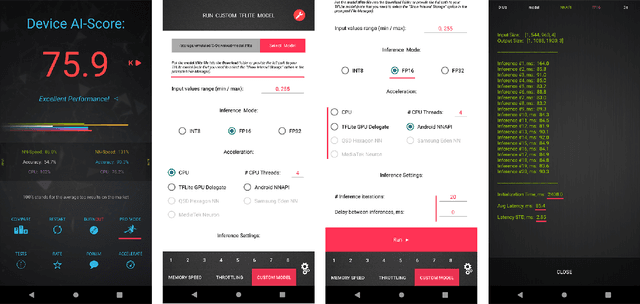
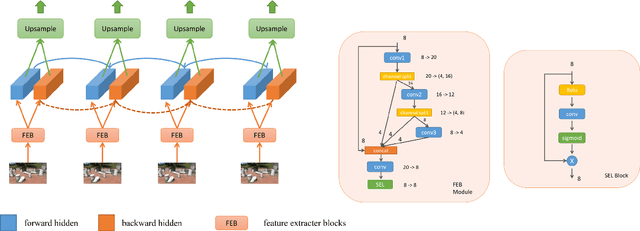
Video super-resolution has recently become one of the most important mobile-related problems due to the rise of video communication and streaming services. While many solutions have been proposed for this task, the majority of them are too computationally expensive to run on portable devices with limited hardware resources. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop an end-to-end deep learning-based video super-resolution solutions that can achieve a real-time performance on mobile GPUs. The participants were provided with the REDS dataset and trained their models to do an efficient 4X video upscaling. The runtime of all models was evaluated on the OPPO Find X2 smartphone with the Snapdragon 865 SoC capable of accelerating floating-point networks on its Adreno GPU. The proposed solutions are fully compatible with any mobile GPU and can upscale videos to HD resolution at up to 80 FPS while demonstrating high fidelity results. A detailed description of all models developed in the challenge is provided in this paper.
AIM 2020 Challenge on Efficient Super-Resolution: Methods and Results
Sep 15, 2020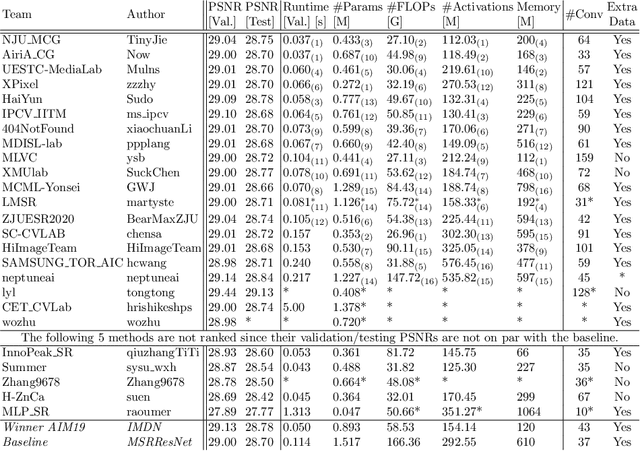
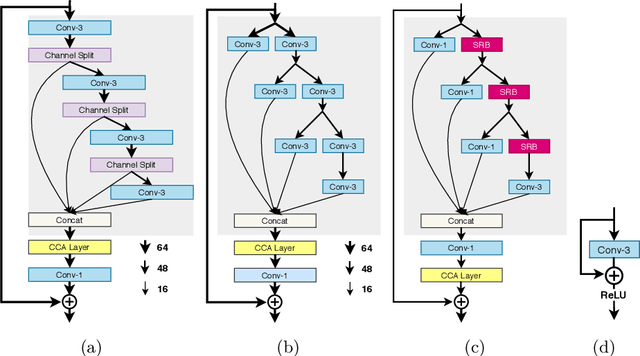
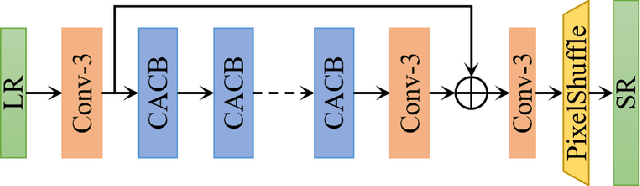
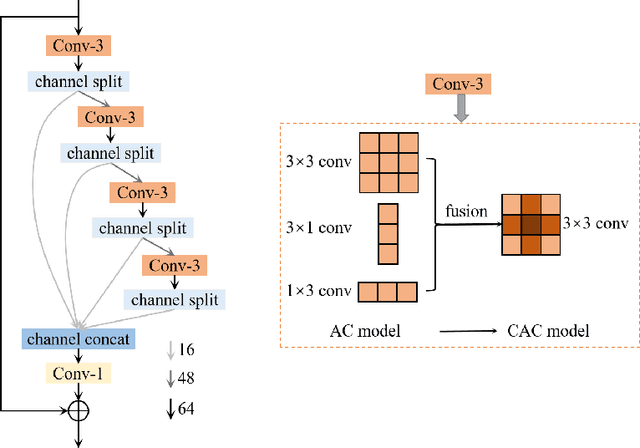
This paper reviews the AIM 2020 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The challenge task was to super-resolve an input image with a magnification factor x4 based on a set of prior examples of low and corresponding high resolution images. The goal is to devise a network that reduces one or several aspects such as runtime, parameter count, FLOPs, activations, and memory consumption while at least maintaining PSNR of MSRResNet. The track had 150 registered participants, and 25 teams submitted the final results. They gauge the state-of-the-art in efficient single image super-resolution.
GIA-Net: Global Information Aware Network for Low-light Imaging
Sep 14, 2020
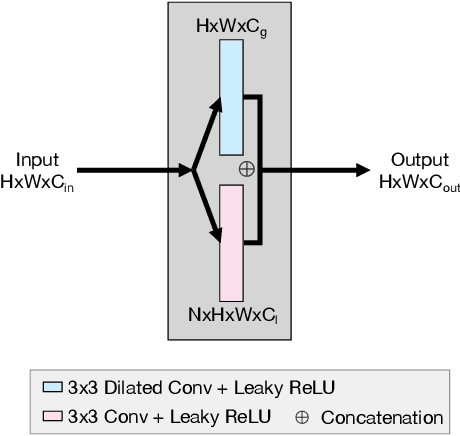
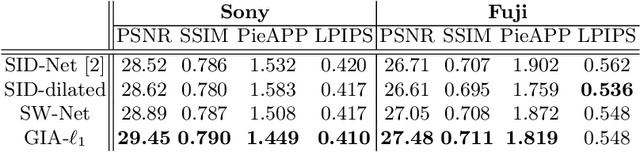
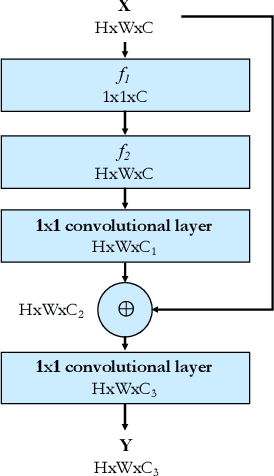
It is extremely challenging to acquire perceptually plausible images under low-light conditions due to low SNR. Most recently, U-Nets have shown promising results for low-light imaging. However, vanilla U-Nets generate images with artifacts such as color inconsistency due to the lack of global color information. In this paper, we propose a global information aware (GIA) module, which is capable of extracting and integrating the global information into the network to improve the performance of low-light imaging. The GIA module can be inserted into a vanilla U-Net with negligible extra learnable parameters or computational cost. Moreover, a GIA-Net is constructed, trained and evaluated on a large scale real-world low-light imaging dataset. Experimental results show that the proposed GIA-Net outperforms the state-of-the-art methods in terms of four metrics, including deep metrics that measure perceptual similarities. Extensive ablation studies have been conducted to verify the effectiveness of the proposed GIA-Net for low-light imaging by utilizing global information.
Point Adversarial Self Mining: A Simple Method for Facial Expression Recognition in the Wild
Aug 26, 2020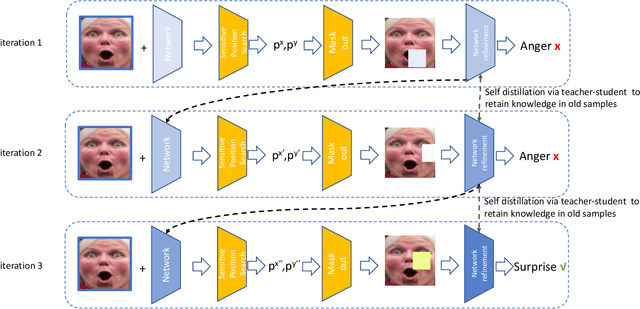
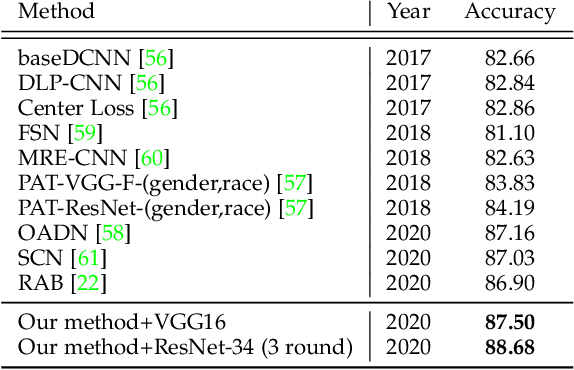
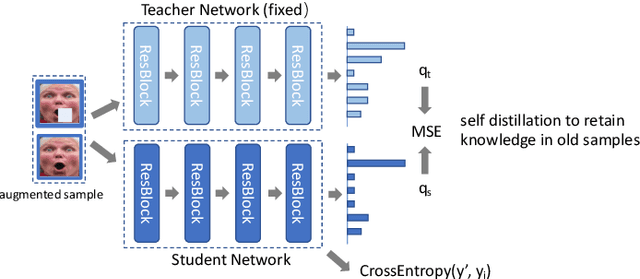

In this paper, the Point Adversarial Self Mining (PASM) approach, a simple yet effective way to progressively mine knowledge from training samples, is proposed to produce training data for CNNs to improve the performance and network generality in Facial Expression Recognition (FER) task. In order to achieve a high prediction accuracy under real-world scenarios, most of the existing works choose to manipulate the network architectures and design sophisticated loss terms. Although demonstrated to be effective in real scenarios, those aforementioned methods require extra efforts in network design. Inspired by random erasing and adversarial erasing, we propose PASM for data augmentation, simulating the data distribution in the wild. Specifically, given a sample and a pre-trained network, our proposed approach locates the informative region in the sample generated by point adversarial attack policy. The informative region is highly structured and sparse. Comparing to the regions produced by random erasing which selects the region in a purely random way and adversarial erasing which operates by attention maps, the located informative regions obtained by PASM are more adaptive and better aligned with the previous findings: not all but only a few facial regions contribute to the accurate prediction. Then, the located informative regions are masked out from the original samples to generate augmented images, which would force the network to explore additional information from other less informative regions. The augmented images are used to finetune the network to enhance its generality. In the refinement process, we take advantage of knowledge distillation, utilizing the pre-trained network to provide guidance and retain knowledge from old samples to train a new network with the same structural configuration.
Omni-supervised Facial Expression Recognition: A Simple Baseline
May 18, 2020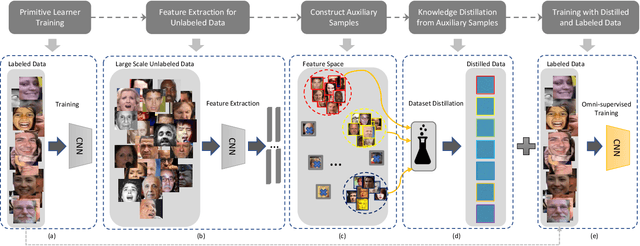
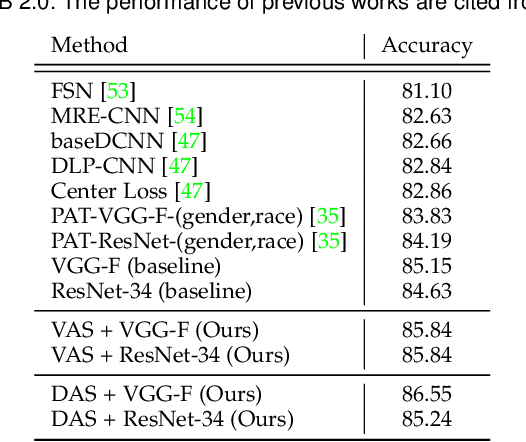
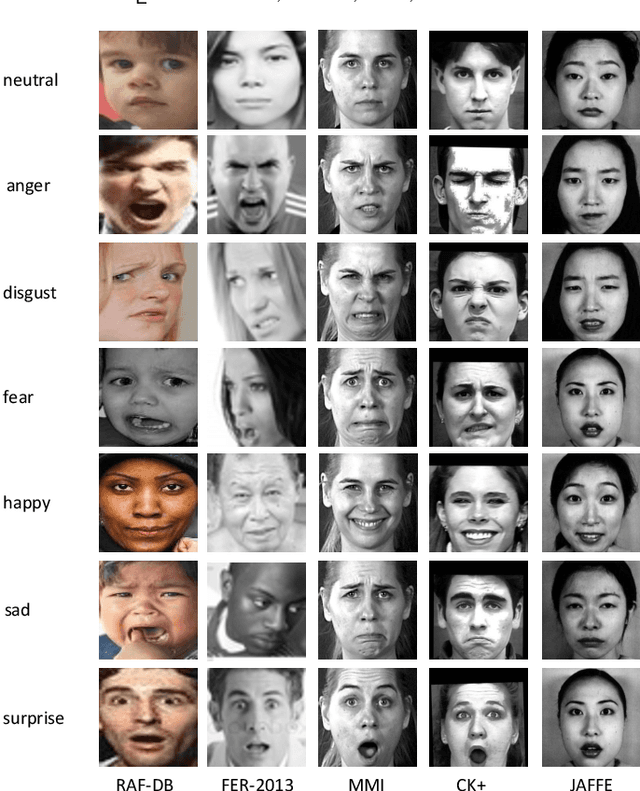
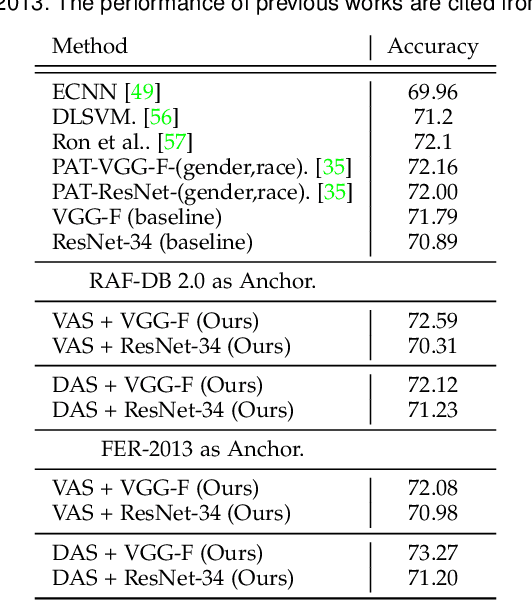
In this paper, we target on advancing the performance in facial expression recognition (FER) by exploiting omni-supervised learning. The current state of the art FER approaches usually aim to recognize facial expressions in a controlled environment by training models with a limited number of samples. To enhance the robustness of the learned models for various scenarios, we propose to perform omni-supervised learning by exploiting the labeled samples together with a large number of unlabeled data. Particularly, we first employ MS-Celeb-1M as the facial-pool where around 5,822K unlabeled facial images are included. Then, a primitive model learned on a small number of labeled samples is adopted to select samples with high confidence from the facial-pool by conducting feature-based similarity comparison. We find the new dataset constructed in such an omni-supervised manner can significantly improve the generalization ability of the learned FER model and boost the performance consequently. However, as more training samples are used, more computation resources and training time are required, which is usually not affordable in many circumstances. To relieve the requirement of computational resources, we further adopt a dataset distillation strategy to distill the target task-related knowledge from the new mined samples and compressed them into a very small set of images. This distilled dataset is capable of boosting the performance of FER with few additional computational cost introduced. We perform extensive experiments on five popular benchmarks and a newly constructed dataset, where consistent gains can be achieved under various settings using the proposed framework. We hope this work will serve as a solid baseline and help ease future research in FER.
NTIRE 2020 Challenge on Real-World Image Super-Resolution: Methods and Results
May 05, 2020
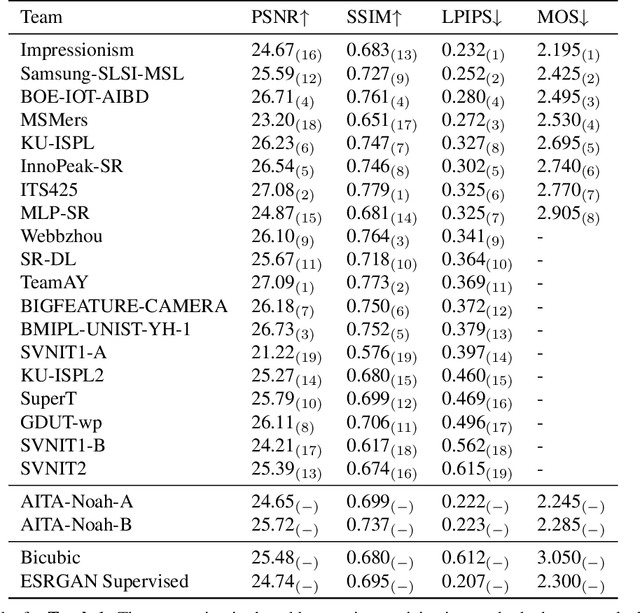
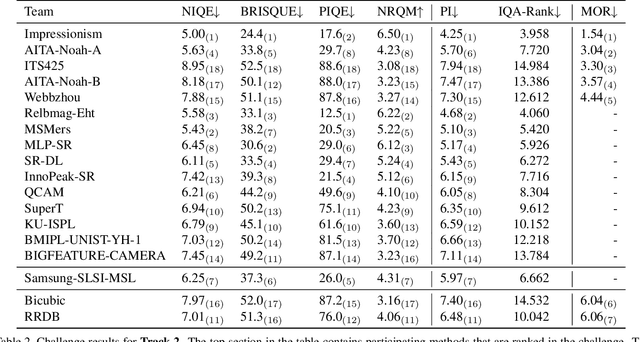

This paper reviews the NTIRE 2020 challenge on real world super-resolution. It focuses on the participating methods and final results. The challenge addresses the real world setting, where paired true high and low-resolution images are unavailable. For training, only one set of source input images is therefore provided along with a set of unpaired high-quality target images. In Track 1: Image Processing artifacts, the aim is to super-resolve images with synthetically generated image processing artifacts. This allows for quantitative benchmarking of the approaches \wrt a ground-truth image. In Track 2: Smartphone Images, real low-quality smart phone images have to be super-resolved. In both tracks, the ultimate goal is to achieve the best perceptual quality, evaluated using a human study. This is the second challenge on the subject, following AIM 2019, targeting to advance the state-of-the-art in super-resolution. To measure the performance we use the benchmark protocol from AIM 2019. In total 22 teams competed in the final testing phase, demonstrating new and innovative solutions to the problem.
Residual Channel Attention Generative Adversarial Network for Image Super-Resolution and Noise Reduction
Apr 28, 2020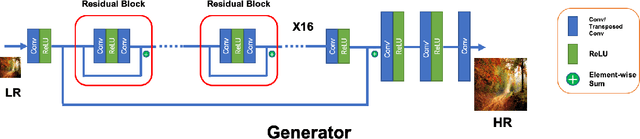
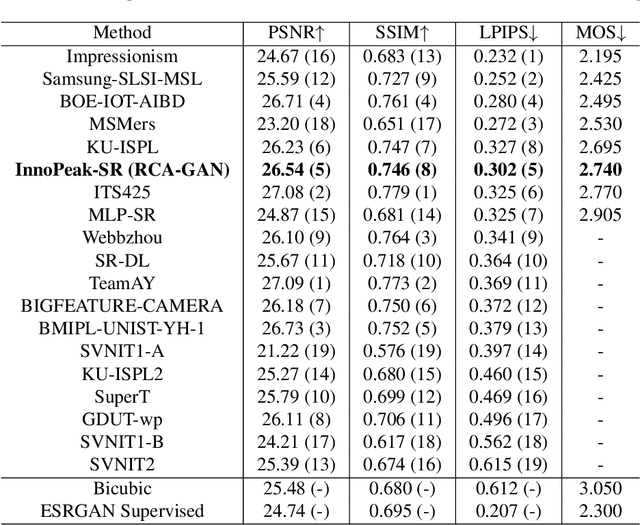
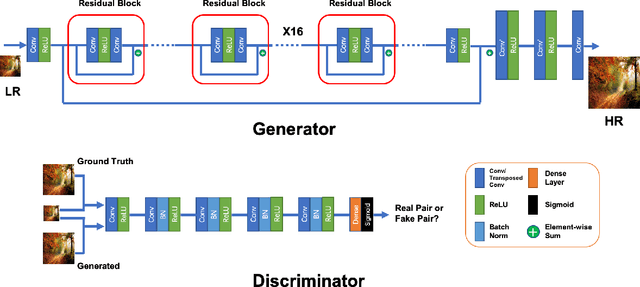
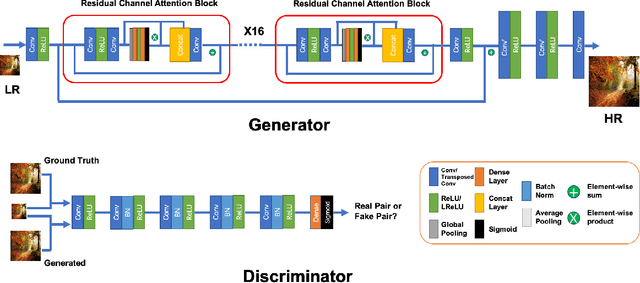
Image super-resolution is one of the important computer vision techniques aiming to reconstruct high-resolution images from corresponding low-resolution ones. Most recently, deep learning-based approaches have been demonstrated for image super-resolution. However, as the deep networks go deeper, they become more difficult to train and more difficult to restore the finer texture details, especially under real-world settings. In this paper, we propose a Residual Channel Attention-Generative Adversarial Network(RCA-GAN) to solve these problems. Specifically, a novel residual channel attention block is proposed to form RCA-GAN, which consists of a set of residual blocks with shortcut connections, and a channel attention mechanism to model the interdependence and interaction of the feature representations among different channels. Besides, a generative adversarial network (GAN) is employed to further produce realistic and highly detailed results. Benefiting from these improvements, the proposed RCA-GAN yields consistently better visual quality with more detailed and natural textures than baseline models; and achieves comparable or better performance compared with the state-of-the-art methods for real-world image super-resolution.
Feature-level and Model-level Audiovisual Fusion for Emotion Recognition in the Wild
Jun 06, 2019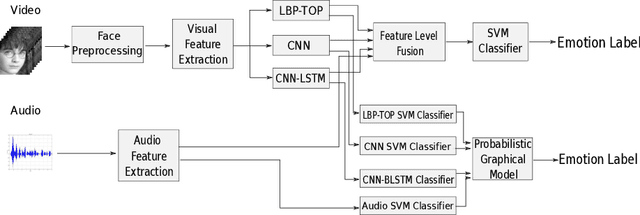
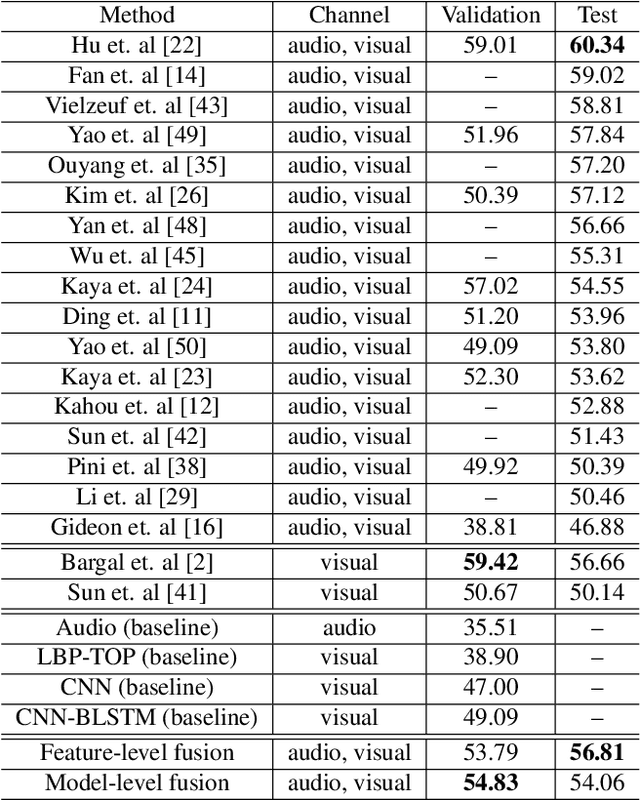
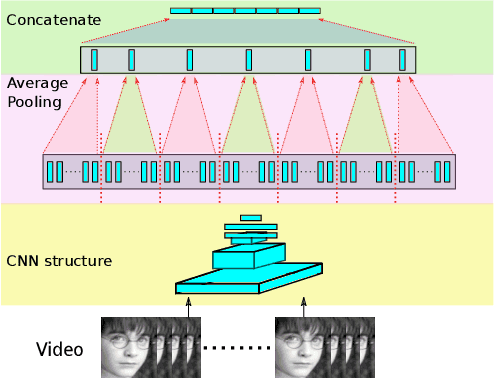
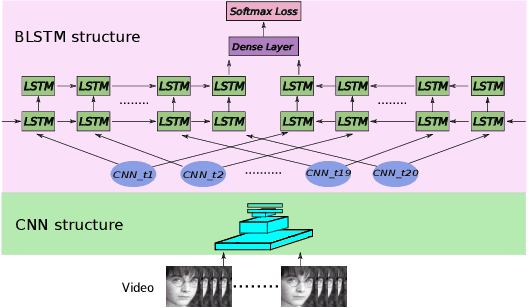
Emotion recognition plays an important role in human-computer interaction (HCI) and has been extensively studied for decades. Although tremendous improvements have been achieved for posed expressions, recognizing human emotions in "close-to-real-world" environments remains a challenge. In this paper, we proposed two strategies to fuse information extracted from different modalities, i.e., audio and visual. Specifically, we utilized LBP-TOP, an ensemble of CNNs, and a bi-directional LSTM (BLSTM) to extract features from the visual channel, and the OpenSmile toolkit to extract features from the audio channel. Two kinds of fusion methods, i,e., feature-level fusion and model-level fusion, were developed to utilize the information extracted from the two channels. Experimental results on the EmotiW2018 AFEW dataset have shown that the proposed fusion methods outperform the baseline methods significantly and achieve better or at least comparable performance compared with the state-of-the-art methods, where the model-level fusion performs better when one of the channels totally fails.
Identity-Free Facial Expression Recognition using conditional Generative Adversarial Network
Mar 19, 2019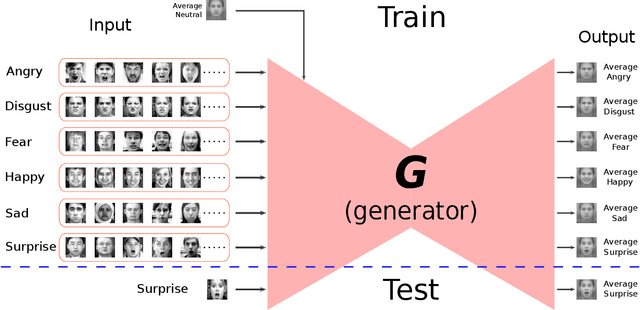
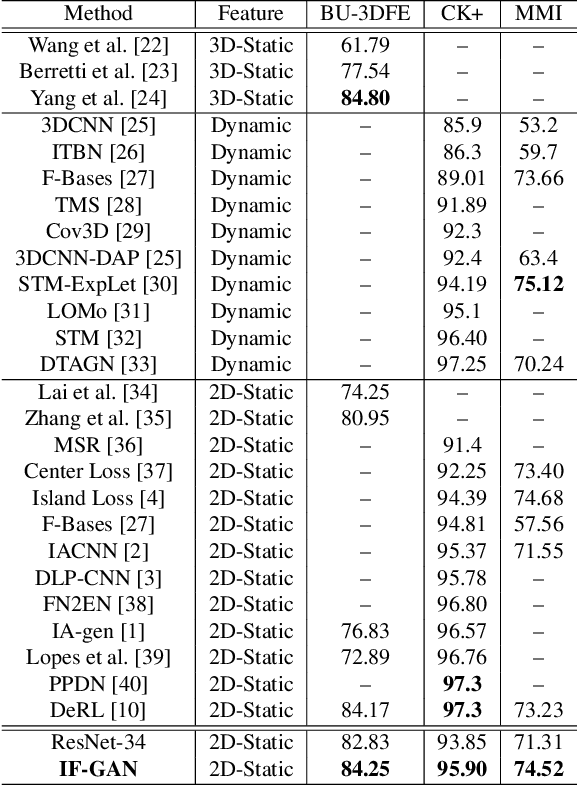
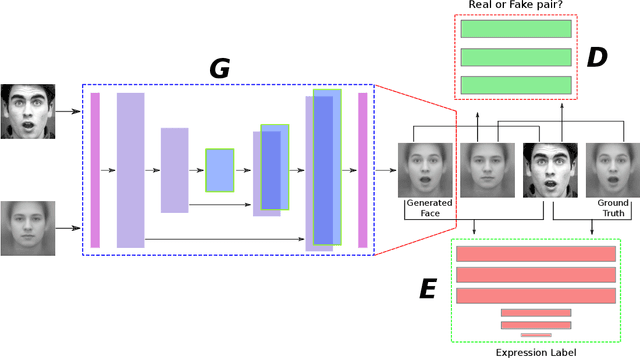

In this paper, we proposed a novel Identity-free conditional Generative Adversarial Network (IF-GAN) to explicitly reduce inter-subject variations for facial expression recognition. Specifically, for any given input face image, a conditional generative model was developed to transform an average neutral face, which is calculated from various subjects showing neutral expressions, to an average expressive face with the same expression as the input image. Since the transformed images have the same synthetic "average" identity, they differ from each other by only their expressions and thus, can be used for identity-free expression classification. In this work, an end-to-end system was developed to perform expression transformation and expression recognition in the IF-GAN framework. Experimental results on three facial expression datasets have demonstrated that the proposed IF-GAN outperforms the baseline CNN model and achieves comparable or better performance compared with the state-of-the-art methods for facial expression recognition.
Probabilistic Attribute Tree in Convolutional Neural Networks for Facial Expression Recognition
Dec 17, 2018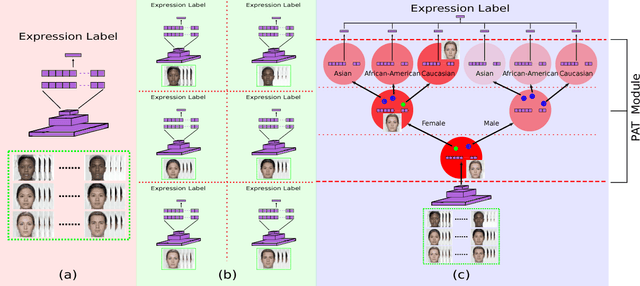

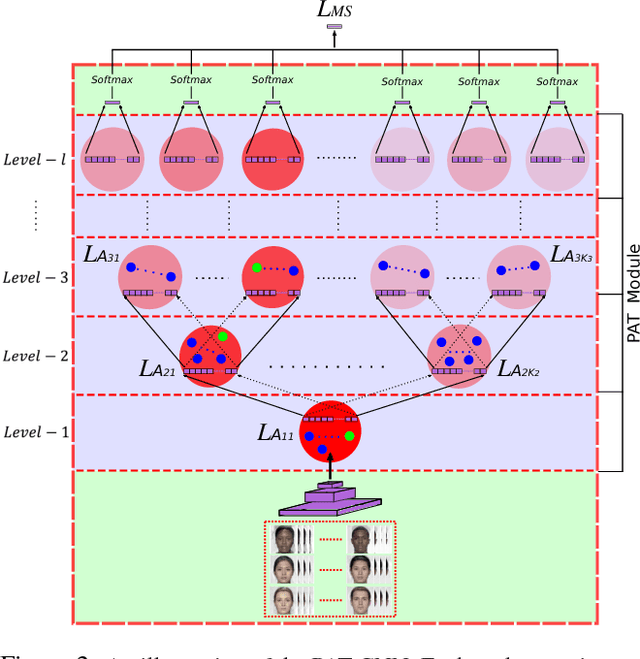
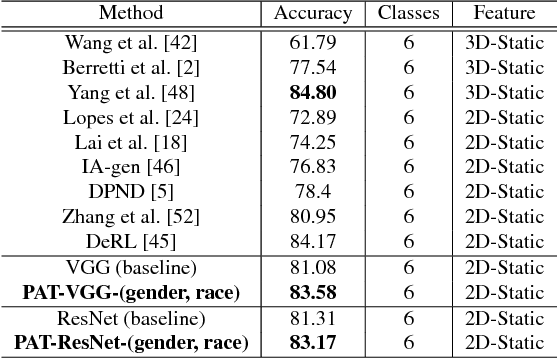
In this paper, we proposed a novel Probabilistic Attribute Tree-CNN (PAT-CNN) to explicitly deal with the large intra-class variations caused by identity-related attributes, e.g., age, race, and gender. Specifically, a novel PAT module with an associated PAT loss was proposed to learn features in a hierarchical tree structure organized according to attributes, where the final features are less affected by the attributes. Then, expression-related features are extracted from leaf nodes. Samples are probabilistically assigned to tree nodes at different levels such that expression-related features can be learned from all samples weighted by probabilities. We further proposed a semi-supervised strategy to learn the PAT-CNN from limited attribute-annotated samples to make the best use of available data. Experimental results on five facial expression datasets have demonstrated that the proposed PAT-CNN outperforms the baseline models by explicitly modeling attributes. More impressively, the PAT-CNN using a single model achieves the best performance for faces in the wild on the SFEW dataset, compared with the state-of-the-art methods using an ensemble of hundreds of CNNs.