 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThor: Towards Human-Level Whole-Body Reactions for Intense Contact-Rich Environments
Oct 30, 2025



Humanoids hold great potential for service, industrial, and rescue applications, in which robots must sustain whole-body stability while performing intense, contact-rich interactions with the environment. However, enabling humanoids to generate human-like, adaptive responses under such conditions remains a major challenge. To address this, we propose Thor, a humanoid framework for human-level whole-body reactions in contact-rich environments. Based on the robot's force analysis, we design a force-adaptive torso-tilt (FAT2) reward function to encourage humanoids to exhibit human-like responses during force-interaction tasks. To mitigate the high-dimensional challenges of humanoid control, Thor introduces a reinforcement learning architecture that decouples the upper body, waist, and lower body. Each component shares global observations of the whole body and jointly updates its parameters. Finally, we deploy Thor on the Unitree G1, and it substantially outperforms baselines in force-interaction tasks. Specifically, the robot achieves a peak pulling force of 167.7 N (approximately 48% of the G1's body weight) when moving backward and 145.5 N when moving forward, representing improvements of 68.9% and 74.7%, respectively, compared with the best-performing baseline. Moreover, Thor is capable of pulling a loaded rack (130 N) and opening a fire door with one hand (60 N). These results highlight Thor's effectiveness in enhancing humanoid force-interaction capabilities.
From Language to Locomotion: Retargeting-free Humanoid Control via Motion Latent Guidance
Oct 16, 2025Natural language offers a natural interface for humanoid robots, but existing language-guided humanoid locomotion pipelines remain cumbersome and unreliable. They typically decode human motion, retarget it to robot morphology, and then track it with a physics-based controller. However, this multi-stage process is prone to cumulative errors, introduces high latency, and yields weak coupling between semantics and control. These limitations call for a more direct pathway from language to action, one that eliminates fragile intermediate stages. Therefore, we present RoboGhost, a retargeting-free framework that directly conditions humanoid policies on language-grounded motion latents. By bypassing explicit motion decoding and retargeting, RoboGhost enables a diffusion-based policy to denoise executable actions directly from noise, preserving semantic intent and supporting fast, reactive control. A hybrid causal transformer-diffusion motion generator further ensures long-horizon consistency while maintaining stability and diversity, yielding rich latent representations for precise humanoid behavior. Extensive experiments demonstrate that RoboGhost substantially reduces deployment latency, improves success rates and tracking accuracy, and produces smooth, semantically aligned locomotion on real humanoids. Beyond text, the framework naturally extends to other modalities such as images, audio, and music, providing a general foundation for vision-language-action humanoid systems.
TIGeR: Tool-Integrated Geometric Reasoning in Vision-Language Models for Robotics
Oct 08, 2025



Vision-Language Models (VLMs) have shown remarkable capabilities in spatial reasoning, yet they remain fundamentally limited to qualitative precision and lack the computational precision required for real-world robotics. Current approaches fail to leverage metric cues from depth sensors and camera calibration, instead reducing geometric problems to pattern recognition tasks that cannot deliver the centimeter-level accuracy essential for robotic manipulation. We present TIGeR (Tool-Integrated Geometric Reasoning), a novel framework that transforms VLMs from perceptual estimators to geometric computers by enabling them to generate and execute precise geometric computations through external tools. Rather than attempting to internalize complex geometric operations within neural networks, TIGeR empowers models to recognize geometric reasoning requirements, synthesize appropriate computational code, and invoke specialized libraries for exact calculations. To support this paradigm, we introduce TIGeR-300K, a comprehensive tool-invocation-oriented dataset covering point transformations, pose estimation, trajectory generation, and spatial compatibility verification, complete with tool invocation sequences and intermediate computations. Through a two-stage training pipeline combining supervised fine-tuning (SFT) and reinforcement fine-tuning (RFT) with our proposed hierarchical reward design, TIGeR achieves SOTA performance on geometric reasoning benchmarks while demonstrating centimeter-level precision in real-world robotic manipulation tasks.
MathSticks: A Benchmark for Visual Symbolic Compositional Reasoning with Matchstick Puzzles
Oct 01, 2025We introduce \textsc{MathSticks}, a benchmark for Visual Symbolic Compositional Reasoning (VSCR), which unifies visual perception, symbolic manipulation, and arithmetic consistency. Each task presents an incorrect matchstick equation that must be corrected by moving one or two sticks under strict conservation rules. The benchmark includes both text-guided and purely visual settings, systematically covering digit scale, move complexity, solution multiplicity, and operator variation, with 1.4M generated instances and a curated test set. Evaluations of 14 vision--language models reveal substantial limitations: closed-source models succeed only on simple cases, open-source models fail in the visual regime, while humans exceed 90\% accuracy. These findings establish \textsc{MathSticks} as a rigorous testbed for advancing compositional reasoning across vision and symbols. Our code and dataset are publicly available at https://github.com/Yuheng2000/MathSticks.
Double Helix Diffusion for Cross-Domain Anomaly Image Generation
Sep 16, 2025Visual anomaly inspection is critical in manufacturing, yet hampered by the scarcity of real anomaly samples for training robust detectors. Synthetic data generation presents a viable strategy for data augmentation; however, current methods remain constrained by two principal limitations: 1) the generation of anomalies that are structurally inconsistent with the normal background, and 2) the presence of undesirable feature entanglement between synthesized images and their corresponding annotation masks, which undermines the perceptual realism of the output. This paper introduces Double Helix Diffusion (DH-Diff), a novel cross-domain generative framework designed to simultaneously synthesize high-fidelity anomaly images and their pixel-level annotation masks, explicitly addressing these challenges. DH-Diff employs a unique architecture inspired by a double helix, cycling through distinct modules for feature separation, connection, and merging. Specifically, a domain-decoupled attention mechanism mitigates feature entanglement by enhancing image and annotation features independently, and meanwhile a semantic score map alignment module ensures structural authenticity by coherently integrating anomaly foregrounds. DH-Diff offers flexible control via text prompts and optional graphical guidance. Extensive experiments demonstrate that DH-Diff significantly outperforms state-of-the-art methods in diversity and authenticity, leading to significant improvements in downstream anomaly detection performance.
$NavA^3$: Understanding Any Instruction, Navigating Anywhere, Finding Anything
Aug 06, 2025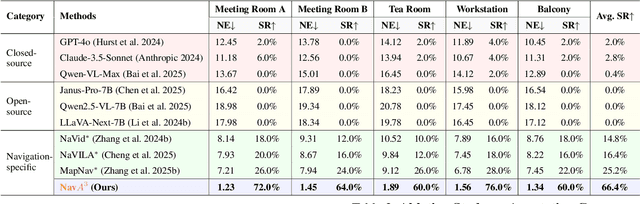
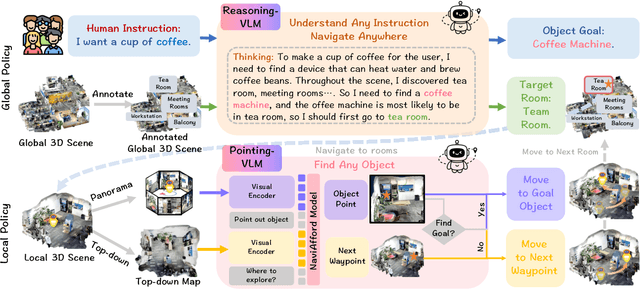
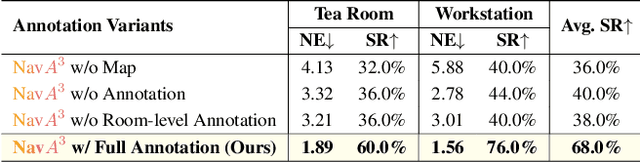
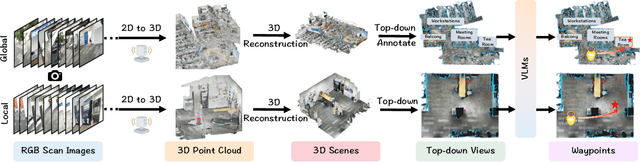
Embodied navigation is a fundamental capability of embodied intelligence, enabling robots to move and interact within physical environments. However, existing navigation tasks primarily focus on predefined object navigation or instruction following, which significantly differs from human needs in real-world scenarios involving complex, open-ended scenes. To bridge this gap, we introduce a challenging long-horizon navigation task that requires understanding high-level human instructions and performing spatial-aware object navigation in real-world environments. Existing embodied navigation methods struggle with such tasks due to their limitations in comprehending high-level human instructions and localizing objects with an open vocabulary. In this paper, we propose $NavA^3$, a hierarchical framework divided into two stages: global and local policies. In the global policy, we leverage the reasoning capabilities of Reasoning-VLM to parse high-level human instructions and integrate them with global 3D scene views. This allows us to reason and navigate to regions most likely to contain the goal object. In the local policy, we have collected a dataset of 1.0 million samples of spatial-aware object affordances to train the NaviAfford model (PointingVLM), which provides robust open-vocabulary object localization and spatial awareness for precise goal identification and navigation in complex environments. Extensive experiments demonstrate that $NavA^3$ achieves SOTA results in navigation performance and can successfully complete longhorizon navigation tasks across different robot embodiments in real-world settings, paving the way for universal embodied navigation. The dataset and code will be made available. Project website: https://NavigationA3.github.io/.
RoboBrain 2.0 Technical Report
Jul 02, 2025We introduce RoboBrain 2.0, our latest generation of embodied vision-language foundation models, designed to unify perception, reasoning, and planning for complex embodied tasks in physical environments. It comes in two variants: a lightweight 7B model and a full-scale 32B model, featuring a heterogeneous architecture with a vision encoder and a language model. Despite its compact size, RoboBrain 2.0 achieves strong performance across a wide spectrum of embodied reasoning tasks. On both spatial and temporal benchmarks, the 32B variant achieves leading results, surpassing prior open-source and proprietary models. In particular, it supports key real-world embodied AI capabilities, including spatial understanding (e.g., affordance prediction, spatial referring, trajectory forecasting) and temporal decision-making (e.g., closed-loop interaction, multi-agent long-horizon planning, and scene graph updating). This report details the model architecture, data construction, multi-stage training strategies, infrastructure and practical applications. We hope RoboBrain 2.0 advances embodied AI research and serves as a practical step toward building generalist embodied agents. The code, checkpoint and benchmark are available at https://superrobobrain.github.io.
AC-DiT: Adaptive Coordination Diffusion Transformer for Mobile Manipulation
Jul 02, 2025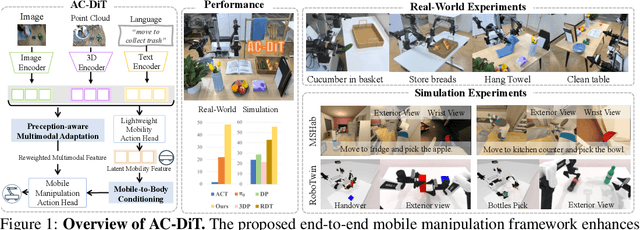
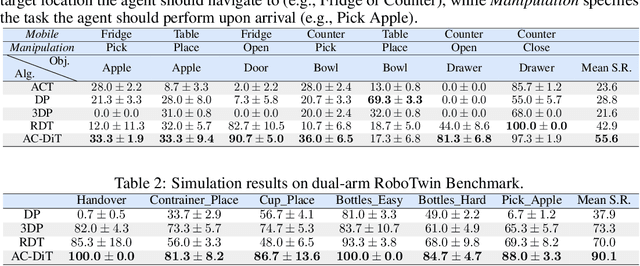
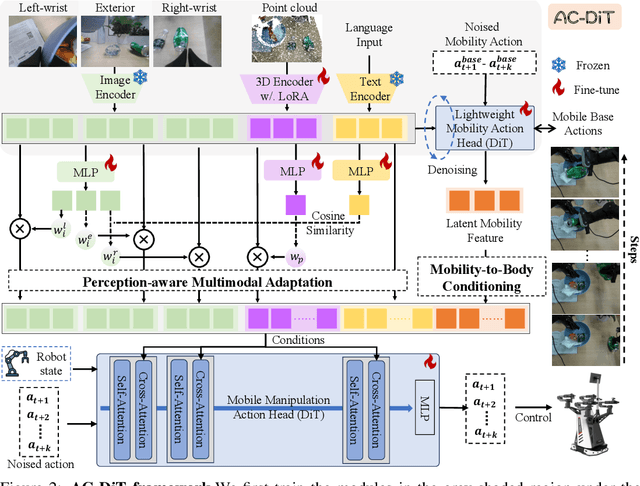

Recently, mobile manipulation has attracted increasing attention for enabling language-conditioned robotic control in household tasks. However, existing methods still face challenges in coordinating mobile base and manipulator, primarily due to two limitations. On the one hand, they fail to explicitly model the influence of the mobile base on manipulator control, which easily leads to error accumulation under high degrees of freedom. On the other hand, they treat the entire mobile manipulation process with the same visual observation modality (e.g., either all 2D or all 3D), overlooking the distinct multimodal perception requirements at different stages during mobile manipulation. To address this, we propose the Adaptive Coordination Diffusion Transformer (AC-DiT), which enhances mobile base and manipulator coordination for end-to-end mobile manipulation. First, since the motion of the mobile base directly influences the manipulator's actions, we introduce a mobility-to-body conditioning mechanism that guides the model to first extract base motion representations, which are then used as context prior for predicting whole-body actions. This enables whole-body control that accounts for the potential impact of the mobile base's motion. Second, to meet the perception requirements at different stages of mobile manipulation, we design a perception-aware multimodal conditioning strategy that dynamically adjusts the fusion weights between various 2D visual images and 3D point clouds, yielding visual features tailored to the current perceptual needs. This allows the model to, for example, adaptively rely more on 2D inputs when semantic information is crucial for action prediction, while placing greater emphasis on 3D geometric information when precise spatial understanding is required. We validate AC-DiT through extensive experiments on both simulated and real-world mobile manipulation tasks.
OmniGen2: Exploration to Advanced Multimodal Generation
Jun 23, 2025In this work, we introduce OmniGen2, a versatile and open-source generative model designed to provide a unified solution for diverse generation tasks, including text-to-image, image editing, and in-context generation. Unlike OmniGen v1, OmniGen2 features two distinct decoding pathways for text and image modalities, utilizing unshared parameters and a decoupled image tokenizer. This design enables OmniGen2 to build upon existing multimodal understanding models without the need to re-adapt VAE inputs, thereby preserving the original text generation capabilities. To facilitate the training of OmniGen2, we developed comprehensive data construction pipelines, encompassing image editing and in-context generation data. Additionally, we introduce a reflection mechanism tailored for image generation tasks and curate a dedicated reflection dataset based on OmniGen2. Despite its relatively modest parameter size, OmniGen2 achieves competitive results on multiple task benchmarks, including text-to-image and image editing. To further evaluate in-context generation, also referred to as subject-driven tasks, we introduce a new benchmark named OmniContext. OmniGen2 achieves state-of-the-art performance among open-source models in terms of consistency. We will release our models, training code, datasets, and data construction pipeline to support future research in this field. Project Page: https://vectorspacelab.github.io/OmniGen2; GitHub Link: https://github.com/VectorSpaceLab/OmniGen2
Video-CoT: A Comprehensive Dataset for Spatiotemporal Understanding of Videos Based on Chain-of-Thought
Jun 12, 2025



Video content comprehension is essential for various applications, ranging from video analysis to interactive systems. Despite advancements in large-scale vision-language models (VLMs), these models often struggle to capture the nuanced, spatiotemporal details essential for thorough video analysis. To address this gap, we introduce Video-CoT, a groundbreaking dataset designed to enhance spatiotemporal understanding using Chain-of-Thought (CoT) methodologies. Video-CoT contains 192,000 fine-grained spa-tiotemporal question-answer pairs and 23,000 high-quality CoT-annotated samples, providing a solid foundation for evaluating spatiotemporal understanding in video comprehension. Additionally, we provide a comprehensive benchmark for assessing these tasks, with each task featuring 750 images and tailored evaluation metrics. Our extensive experiments reveal that current VLMs face significant challenges in achieving satisfactory performance, high-lighting the difficulties of effective spatiotemporal understanding. Overall, the Video-CoT dataset and benchmark open new avenues for research in multimedia understanding and support future innovations in intelligent systems requiring advanced video analysis capabilities. By making these resources publicly available, we aim to encourage further exploration in this critical area. Project website:https://video-cot.github.io/ .