 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe THU-HCSI Multi-Speaker Multi-Lingual Few-Shot Voice Cloning System for LIMMITS'24 Challenge
Apr 25, 2024
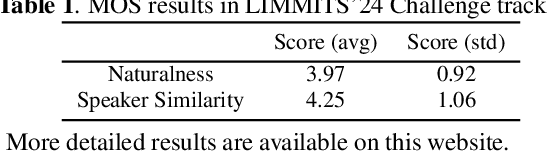
This paper presents the multi-speaker multi-lingual few-shot voice cloning system developed by THU-HCSI team for LIMMITS'24 Challenge. To achieve high speaker similarity and naturalness in both mono-lingual and cross-lingual scenarios, we build the system upon YourTTS and add several enhancements. For further improving speaker similarity and speech quality, we introduce speaker-aware text encoder and flow-based decoder with Transformer blocks. In addition, we denoise the few-shot data, mix up them with pre-training data, and adopt a speaker-balanced sampling strategy to guarantee effective fine-tuning for target speakers. The official evaluations in track 1 show that our system achieves the best speaker similarity MOS of 4.25 and obtains considerable naturalness MOS of 3.97.
When Fuzzing Meets LLMs: Challenges and Opportunities
Apr 25, 2024Fuzzing, a widely-used technique for bug detection, has seen advancements through Large Language Models (LLMs). Despite their potential, LLMs face specific challenges in fuzzing. In this paper, we identified five major challenges of LLM-assisted fuzzing. To support our findings, we revisited the most recent papers from top-tier conferences, confirming that these challenges are widespread. As a remedy, we propose some actionable recommendations to help improve applying LLM in Fuzzing and conduct preliminary evaluations on DBMS fuzzing. The results demonstrate that our recommendations effectively address the identified challenges.
Co-Speech Gesture Video Generation via Motion-Decoupled Diffusion Model
Apr 02, 2024



Co-speech gestures, if presented in the lively form of videos, can achieve superior visual effects in human-machine interaction. While previous works mostly generate structural human skeletons, resulting in the omission of appearance information, we focus on the direct generation of audio-driven co-speech gesture videos in this work. There are two main challenges: 1) A suitable motion feature is needed to describe complex human movements with crucial appearance information. 2) Gestures and speech exhibit inherent dependencies and should be temporally aligned even of arbitrary length. To solve these problems, we present a novel motion-decoupled framework to generate co-speech gesture videos. Specifically, we first introduce a well-designed nonlinear TPS transformation to obtain latent motion features preserving essential appearance information. Then a transformer-based diffusion model is proposed to learn the temporal correlation between gestures and speech, and performs generation in the latent motion space, followed by an optimal motion selection module to produce long-term coherent and consistent gesture videos. For better visual perception, we further design a refinement network focusing on missing details of certain areas. Extensive experimental results show that our proposed framework significantly outperforms existing approaches in both motion and video-related evaluations. Our code, demos, and more resources are available at https://github.com/thuhcsi/S2G-MDDiffusion.
A Survey of Neural Code Intelligence: Paradigms, Advances and Beyond
Mar 21, 2024Neural Code Intelligence -- leveraging deep learning to understand, generate, and optimize code -- holds immense potential for transformative impacts on the whole society. Bridging the gap between Natural Language and Programming Language, this domain has drawn significant attention from researchers in both research communities over the past few years. This survey presents a systematic and chronological review of the advancements in code intelligence, encompassing over 50 representative models and their variants, more than 20 categories of tasks, and an extensive coverage of over 680 related works. We follow the historical progression to trace the paradigm shifts across different research phases (e.g., from modeling code with recurrent neural networks to the era of Large Language Models). Concurrently, we highlight the major technical transitions in models, tasks, and evaluations spanning through different stages. For applications, we also observe a co-evolving shift. It spans from initial endeavors to tackling specific scenarios, through exploring a diverse array of tasks during its rapid expansion, to currently focusing on tackling increasingly complex and varied real-world challenges. Building on our examination of the developmental trajectories, we further investigate the emerging synergies between code intelligence and broader machine intelligence, uncovering new cross-domain opportunities and illustrating the substantial influence of code intelligence across various domains. Finally, we delve into both the opportunities and challenges associated with this field, alongside elucidating our insights on the most promising research directions. An ongoing, dynamically updated project and resources associated with this survey have been released at https://github.com/QiushiSun/NCISurvey.
Enhancing Expressiveness in Dance Generation via Integrating Frequency and Music Style Information
Mar 09, 2024



Dance generation, as a branch of human motion generation, has attracted increasing attention. Recently, a few works attempt to enhance dance expressiveness, which includes genre matching, beat alignment, and dance dynamics, from certain aspects. However, the enhancement is quite limited as they lack comprehensive consideration of the aforementioned three factors. In this paper, we propose ExpressiveBailando, a novel dance generation method designed to generate expressive dances, concurrently taking all three factors into account. Specifically, we mitigate the issue of speed homogenization by incorporating frequency information into VQ-VAE, thus improving dance dynamics. Additionally, we integrate music style information by extracting genre- and beat-related features with a pre-trained music model, hence achieving improvements in the other two factors. Extensive experimental results demonstrate that our proposed method can generate dances with high expressiveness and outperforms existing methods both qualitatively and quantitatively.
LLM as Prompter: Low-resource Inductive Reasoning on Arbitrary Knowledge Graphs
Feb 19, 2024



Knowledge Graph (KG) inductive reasoning, which aims to infer missing facts from new KGs that are not seen during training, has been widely adopted in various applications. One critical challenge of KG inductive reasoning is handling low-resource scenarios with scarcity in both textual and structural aspects. In this paper, we attempt to address this challenge with Large Language Models (LLMs). Particularly, we utilize the state-of-the-art LLMs to generate a graph-structural prompt to enhance the pre-trained Graph Neural Networks (GNNs), which brings us new methodological insights into the KG inductive reasoning methods, as well as high generalizability in practice. On the methodological side, we introduce a novel pretraining and prompting framework ProLINK, designed for low-resource inductive reasoning across arbitrary KGs without requiring additional training. On the practical side, we experimentally evaluate our approach on 36 low-resource KG datasets and find that ProLINK outperforms previous methods in three-shot, one-shot, and zero-shot reasoning tasks, exhibiting average performance improvements by 20%, 45%, and 147%, respectively. Furthermore, ProLINK demonstrates strong robustness for various LLM promptings as well as full-shot scenarios.
OS-Copilot: Towards Generalist Computer Agents with Self-Improvement
Feb 15, 2024



Autonomous interaction with the computer has been a longstanding challenge with great potential, and the recent proliferation of large language models (LLMs) has markedly accelerated progress in building digital agents. However, most of these agents are designed to interact with a narrow domain, such as a specific software or website. This narrow focus constrains their applicability for general computer tasks. To this end, we introduce OS-Copilot, a framework to build generalist agents capable of interfacing with comprehensive elements in an operating system (OS), including the web, code terminals, files, multimedia, and various third-party applications. We use OS-Copilot to create FRIDAY, a self-improving embodied agent for automating general computer tasks. On GAIA, a general AI assistants benchmark, FRIDAY outperforms previous methods by 35%, showcasing strong generalization to unseen applications via accumulated skills from previous tasks. We also present numerical and quantitative evidence that FRIDAY learns to control and self-improve on Excel and Powerpoint with minimal supervision. Our OS-Copilot framework and empirical findings provide infrastructure and insights for future research toward more capable and general-purpose computer agents.
TDAG: A Multi-Agent Framework based on Dynamic Task Decomposition and Agent Generation
Feb 15, 2024The emergence of Large Language Models (LLMs) like ChatGPT has inspired the development of LLM-based agents capable of addressing complex, real-world tasks. However, these agents often struggle during task execution due to methodological constraints, such as error propagation and limited adaptability. To address this issue, we propose a multi-agent framework based on dynamic Task Decomposition and Agent Generation (TDAG). This framework dynamically decomposes complex tasks into smaller subtasks and assigns each to a specifically generated subagent, thereby enhancing adaptability in diverse and unpredictable real-world tasks. Simultaneously, existing benchmarks often lack the granularity needed to evaluate incremental progress in complex, multi-step tasks. In response, we introduce ItineraryBench in the context of travel planning, featuring interconnected, progressively complex tasks with a fine-grained evaluation system. ItineraryBench is designed to assess agents' abilities in memory, planning, and tool usage across tasks of varying complexity. Our experimental results reveal that TDAG significantly outperforms established baselines, showcasing its superior adaptability and context awareness in complex task scenarios.
Exploiting Audio-Visual Features with Pretrained AV-HuBERT for Multi-Modal Dysarthric Speech Reconstruction
Jan 31, 2024



Dysarthric speech reconstruction (DSR) aims to transform dysarthric speech into normal speech by improving the intelligibility and naturalness. This is a challenging task especially for patients with severe dysarthria and speaking in complex, noisy acoustic environments. To address these challenges, we propose a novel multi-modal framework to utilize visual information, e.g., lip movements, in DSR as extra clues for reconstructing the highly abnormal pronunciations. The multi-modal framework consists of: (i) a multi-modal encoder to extract robust phoneme embeddings from dysarthric speech with auxiliary visual features; (ii) a variance adaptor to infer the normal phoneme duration and pitch contour from the extracted phoneme embeddings; (iii) a speaker encoder to encode the speaker's voice characteristics; and (iv) a mel-decoder to generate the reconstructed mel-spectrogram based on the extracted phoneme embeddings, prosodic features and speaker embeddings. Both objective and subjective evaluations conducted on the commonly used UASpeech corpus show that our proposed approach can achieve significant improvements over baseline systems in terms of speech intelligibility and naturalness, especially for the speakers with more severe symptoms. Compared with original dysarthric speech, the reconstructed speech achieves 42.1\% absolute word error rate reduction for patients with more severe dysarthria levels.
SCNet: Sparse Compression Network for Music Source Separation
Jan 24, 2024



Deep learning-based methods have made significant achievements in music source separation. However, obtaining good results while maintaining a low model complexity remains challenging in super wide-band music source separation. Previous works either overlook the differences in subbands or inadequately address the problem of information loss when generating subband features. In this paper, we propose SCNet, a novel frequency-domain network to explicitly split the spectrogram of the mixture into several subbands and introduce a sparsity-based encoder to model different frequency bands. We use a higher compression ratio on subbands with less information to improve the information density and focus on modeling subbands with more information. In this way, the separation performance can be significantly improved using lower computational consumption. Experiment results show that the proposed model achieves a signal to distortion ratio (SDR) of 9.0 dB on the MUSDB18-HQ dataset without using extra data, which outperforms state-of-the-art methods. Specifically, SCNet's CPU inference time is only 48% of HT Demucs, one of the previous state-of-the-art models.