 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvery FLOP Counts: Scaling a 300B Mixture-of-Experts LING LLM without Premium GPUs
Mar 07, 2025



In this technical report, we tackle the challenges of training large-scale Mixture of Experts (MoE) models, focusing on overcoming cost inefficiency and resource limitations prevalent in such systems. To address these issues, we present two differently sized MoE large language models (LLMs), namely Ling-Lite and Ling-Plus (referred to as "Bailing" in Chinese, spelled B\v{a}il\'ing in Pinyin). Ling-Lite contains 16.8 billion parameters with 2.75 billion activated parameters, while Ling-Plus boasts 290 billion parameters with 28.8 billion activated parameters. Both models exhibit comparable performance to leading industry benchmarks. This report offers actionable insights to improve the efficiency and accessibility of AI development in resource-constrained settings, promoting more scalable and sustainable technologies. Specifically, to reduce training costs for large-scale MoE models, we propose innovative methods for (1) optimization of model architecture and training processes, (2) refinement of training anomaly handling, and (3) enhancement of model evaluation efficiency. Additionally, leveraging high-quality data generated from knowledge graphs, our models demonstrate superior capabilities in tool use compared to other models. Ultimately, our experimental findings demonstrate that a 300B MoE LLM can be effectively trained on lower-performance devices while achieving comparable performance to models of a similar scale, including dense and MoE models. Compared to high-performance devices, utilizing a lower-specification hardware system during the pre-training phase demonstrates significant cost savings, reducing computing costs by approximately 20%. The models can be accessed at https://huggingface.co/inclusionAI.
Bi'an: A Bilingual Benchmark and Model for Hallucination Detection in Retrieval-Augmented Generation
Feb 26, 2025Retrieval-Augmented Generation (RAG) effectively reduces hallucinations in Large Language Models (LLMs) but can still produce inconsistent or unsupported content. Although LLM-as-a-Judge is widely used for RAG hallucination detection due to its implementation simplicity, it faces two main challenges: the absence of comprehensive evaluation benchmarks and the lack of domain-optimized judge models. To bridge these gaps, we introduce \textbf{Bi'an}, a novel framework featuring a bilingual benchmark dataset and lightweight judge models. The dataset supports rigorous evaluation across multiple RAG scenarios, while the judge models are fine-tuned from compact open-source LLMs. Extensive experimental evaluations on Bi'anBench show our 14B model outperforms baseline models with over five times larger parameter scales and rivals state-of-the-art closed-source LLMs. We will release our data and models soon at https://github.com/OpenSPG/KAG.
Mix Data or Merge Models? Balancing the Helpfulness, Honesty, and Harmlessness of Large Language Model via Model Merging
Feb 13, 2025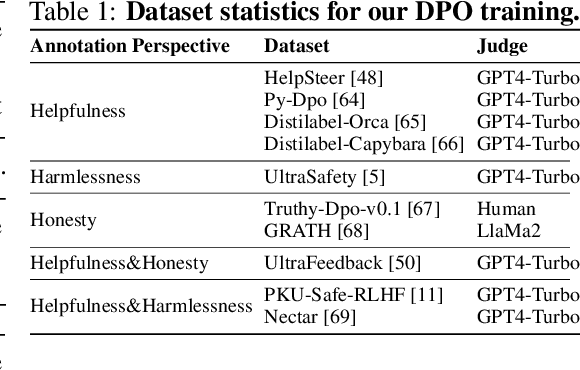
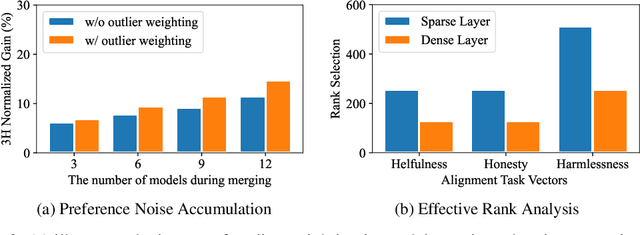
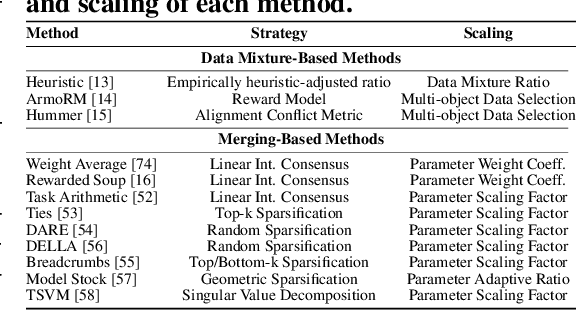
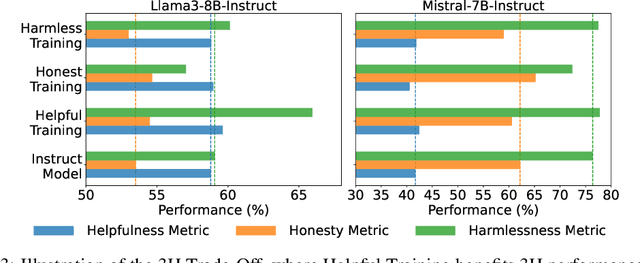
Achieving balanced alignment of large language models (LLMs) in terms of Helpfulness, Honesty, and Harmlessness (3H optimization) constitutes a cornerstone of responsible AI, with existing methods like data mixture strategies facing limitations including reliance on expert knowledge and conflicting optimization signals. While model merging offers a promising alternative by integrating specialized models, its potential for 3H optimization remains underexplored. This paper establishes the first comprehensive benchmark for model merging in 3H-aligned LLMs, systematically evaluating 15 methods (12 training-free merging and 3 data mixture techniques) across 10 datasets associated with 5 annotation dimensions, 2 LLM families, and 2 training paradigms. Our analysis reveals three pivotal insights: (i) previously overlooked collaborative/conflicting relationships among 3H dimensions, (ii) the consistent superiority of model merging over data mixture approaches in balancing alignment trade-offs, and (iii) the critical role of parameter-level conflict resolution through redundant component pruning and outlier mitigation. Building on these findings, we propose R-TSVM, a Reweighting-enhanced Task Singular Vector Merging method that incorporates outlier-aware parameter weighting and sparsity-adaptive rank selection strategies adapted to the heavy-tailed parameter distribution and sparsity for LLMs, further improving LLM alignment across multiple evaluations. We release our trained models for further exploration.
K-ON: Stacking Knowledge On the Head Layer of Large Language Model
Feb 10, 2025



Recent advancements in large language models (LLMs) have significantly improved various natural language processing (NLP) tasks. Typically, LLMs are trained to predict the next token, aligning well with many NLP tasks. However, in knowledge graph (KG) scenarios, entities are the fundamental units and identifying an entity requires at least several tokens. This leads to a granularity mismatch between KGs and natural languages. To address this issue, we propose K-ON, which integrates KG knowledge into the LLM by employing multiple head layers for next k-step prediction. K-ON can not only generate entity-level results in one step, but also enables contrastive loss against entities, which is the most powerful tool in KG representation learning. Experimental results show that K-ON outperforms state-of-the-art methods that incorporate text and even the other modalities.
IceBerg: Debiased Self-Training for Class-Imbalanced Node Classification
Feb 10, 2025



Graph Neural Networks (GNNs) have achieved great success in dealing with non-Euclidean graph-structured data and have been widely deployed in many real-world applications. However, their effectiveness is often jeopardized under class-imbalanced training sets. Most existing studies have analyzed class-imbalanced node classification from a supervised learning perspective, but they do not fully utilize the large number of unlabeled nodes in semi-supervised scenarios. We claim that the supervised signal is just the tip of the iceberg and a large number of unlabeled nodes have not yet been effectively utilized. In this work, we propose IceBerg, a debiased self-training framework to address the class-imbalanced and few-shot challenges for GNNs at the same time. Specifically, to figure out the Matthew effect and label distribution shift in self-training, we propose Double Balancing, which can largely improve the performance of existing baselines with just a few lines of code as a simple plug-and-play module. Secondly, to enhance the long-range propagation capability of GNNs, we disentangle the propagation and transformation operations of GNNs. Therefore, the weak supervision signals can propagate more effectively to address the few-shot issue. In summary, we find that leveraging unlabeled nodes can significantly enhance the performance of GNNs in class-imbalanced and few-shot scenarios, and even small, surgical modifications can lead to substantial performance improvements. Systematic experiments on benchmark datasets show that our method can deliver considerable performance gain over existing class-imbalanced node classification baselines. Additionally, due to IceBerg's outstanding ability to leverage unsupervised signals, it also achieves state-of-the-art results in few-shot node classification scenarios. The code of IceBerg is available at: https://github.com/ZhixunLEE/IceBerg.
MAQInstruct: Instruction-based Unified Event Relation Extraction
Feb 06, 2025Extracting event relations that deviate from known schemas has proven challenging for previous methods based on multi-class classification, MASK prediction, or prototype matching. Recent advancements in large language models have shown impressive performance through instruction tuning. Nevertheless, in the task of event relation extraction, instruction-based methods face several challenges: there are a vast number of inference samples, and the relations between events are non-sequential. To tackle these challenges, we present an improved instruction-based event relation extraction framework named MAQInstruct. Firstly, we transform the task from extracting event relations using given event-event instructions to selecting events using given event-relation instructions, which reduces the number of samples required for inference. Then, by incorporating a bipartite matching loss, we reduce the dependency of the instruction-based method on the generation sequence. Our experimental results demonstrate that MAQInstruct significantly improves the performance of event relation extraction across multiple LLMs.
Improving Natural Language Understanding for LLMs via Large-Scale Instruction Synthesis
Feb 06, 2025



High-quality, large-scale instructions are crucial for aligning large language models (LLMs), however, there is a severe shortage of instruction in the field of natural language understanding (NLU). Previous works on constructing NLU instructions mainly focus on information extraction (IE), neglecting tasks such as machine reading comprehension, question answering, and text classification. Furthermore, the lack of diversity in the data has led to a decreased generalization ability of trained LLMs in other NLU tasks and a noticeable decline in the fundamental model's general capabilities. To address this issue, we propose Hum, a large-scale, high-quality synthetic instruction corpus for NLU tasks, designed to enhance the NLU capabilities of LLMs. Specifically, Hum includes IE (either close IE or open IE), machine reading comprehension, text classification, and instruction generalist tasks, thereby enriching task diversity. Additionally, we introduce a human-LLMs collaborative mechanism to synthesize instructions, which enriches instruction diversity by incorporating guidelines, preference rules, and format variants. We conduct extensive experiments on 5 NLU tasks and 28 general capability evaluation datasets for LLMs. Experimental results show that Hum enhances the NLU capabilities of six LLMs by an average of 3.1\%, with no significant decline observed in other general capabilities.
Unveiling the Potential of Text in High-Dimensional Time Series Forecasting
Jan 13, 2025


Time series forecasting has traditionally focused on univariate and multivariate numerical data, often overlooking the benefits of incorporating multimodal information, particularly textual data. In this paper, we propose a novel framework that integrates time series models with Large Language Models to improve high-dimensional time series forecasting. Inspired by multimodal models, our method combines time series and textual data in the dual-tower structure. This fusion of information creates a comprehensive representation, which is then processed through a linear layer to generate the final forecast. Extensive experiments demonstrate that incorporating text enhances high-dimensional time series forecasting performance. This work paves the way for further research in multimodal time series forecasting.
Have We Designed Generalizable Structural Knowledge Promptings? Systematic Evaluation and Rethinking
Dec 31, 2024



Large language models (LLMs) have demonstrated exceptional performance in text generation within current NLP research. However, the lack of factual accuracy is still a dark cloud hanging over the LLM skyscraper. Structural knowledge prompting (SKP) is a prominent paradigm to integrate external knowledge into LLMs by incorporating structural representations, achieving state-of-the-art results in many knowledge-intensive tasks. However, existing methods often focus on specific problems, lacking a comprehensive exploration of the generalization and capability boundaries of SKP. This paper aims to evaluate and rethink the generalization capability of the SKP paradigm from four perspectives including Granularity, Transferability, Scalability, and Universality. To provide a thorough evaluation, we introduce a novel multi-granular, multi-level benchmark called SUBARU, consisting of 9 different tasks with varying levels of granularity and difficulty.
OneKE: A Dockerized Schema-Guided LLM Agent-based Knowledge Extraction System
Dec 28, 2024


We introduce OneKE, a dockerized schema-guided knowledge extraction system, which can extract knowledge from the Web and raw PDF Books, and support various domains (science, news, etc.). Specifically, we design OneKE with multiple agents and a configure knowledge base. Different agents perform their respective roles, enabling support for various extraction scenarios. The configure knowledge base facilitates schema configuration, error case debugging and correction, further improving the performance. Empirical evaluations on benchmark datasets demonstrate OneKE's efficacy, while case studies further elucidate its adaptability to diverse tasks across multiple domains, highlighting its potential for broad applications. We have open-sourced the Code at https://github.com/zjunlp/OneKE and released a Video at http://oneke.openkg.cn/demo.mp4.