 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMART: A Spectral Transfer Approach to Multi-Task Learning
Apr 22, 2026Multi-task learning is effective for related applications, but its performance can deteriorate when the target sample size is small. Transfer learning can borrow strength from related studies; yet, many existing methods rely on restrictive bounded-difference assumptions between the source and target models. We propose SMART, a spectral transfer method for multi-task linear regression that instead assumes spectral similarity: the target left and right singular subspaces lie within the corresponding source subspaces and are sparsely aligned with the source singular bases. Such an assumption is natural when studies share latent structures and enables transfer beyond the bounded-difference settings. SMART estimates the target coefficient matrix through structured regularization that incorporates spectral information from a source study. Importantly, it requires only a fitted source model rather than the raw source data, making it useful when data sharing is limited. Although the optimization problem is nonconvex, we develop a practical ADMM-based algorithm. We establish general, non-asymptotic error bounds and a minimax lower bound in the noiseless-source regime. Under additional regularity conditions, these results yield near-minimax Frobenius error rates up to logarithmic factors. Simulations confirm improved estimation accuracy and robustness to negative transfer, and analysis of multi-modal single-cell data demonstrates better predictive performance. The Python implementation of SMART, along with the code to reproduce all experiments in this paper, is publicly available at https://github.com/boxinz17/smart.
Trans-Glasso: A Transfer Learning Approach to Precision Matrix Estimation
Nov 23, 2024Precision matrix estimation is essential in various fields, yet it is challenging when samples for the target study are limited. Transfer learning can enhance estimation accuracy by leveraging data from related source studies. We propose Trans-Glasso, a two-step transfer learning method for precision matrix estimation. First, we obtain initial estimators using a multi-task learning objective that captures shared and unique features across studies. Then, we refine these estimators through differential network estimation to adjust for structural differences between the target and source precision matrices. Under the assumption that most entries of the target precision matrix are shared with source matrices, we derive non-asymptotic error bounds and show that Trans-Glasso achieves minimax optimality under certain conditions. Extensive simulations demonstrate Trans Glasso's superior performance compared to baseline methods, particularly in small-sample settings. We further validate Trans-Glasso in applications to gene networks across brain tissues and protein networks for various cancer subtypes, showcasing its effectiveness in biological contexts. Additionally, we derive the minimax optimal rate for differential network estimation, representing the first such guarantee in this area.
HiReview: Hierarchical Taxonomy-Driven Automatic Literature Review Generation
Oct 02, 2024In this work, we present HiReview, a novel framework for hierarchical taxonomy-driven automatic literature review generation. With the exponential growth of academic documents, manual literature reviews have become increasingly labor-intensive and time-consuming, while traditional summarization models struggle to generate comprehensive document reviews effectively. Large language models (LLMs), with their powerful text processing capabilities, offer a potential solution; however, research on incorporating LLMs for automatic document generation remains limited. To address key challenges in large-scale automatic literature review generation (LRG), we propose a two-stage taxonomy-then-generation approach that combines graph-based hierarchical clustering with retrieval-augmented LLMs. First, we retrieve the most relevant sub-community within the citation network, then generate a hierarchical taxonomy tree by clustering papers based on both textual content and citation relationships. In the second stage, an LLM generates coherent and contextually accurate summaries for clusters or topics at each hierarchical level, ensuring comprehensive coverage and logical organization of the literature. Extensive experiments demonstrate that HiReview significantly outperforms state-of-the-art methods, achieving superior hierarchical organization, content relevance, and factual accuracy in automatic literature review generation tasks.
Transforming Slot Schema Induction with Generative Dialogue State Inference
Aug 03, 2024



The challenge of defining a slot schema to represent the state of a task-oriented dialogue system is addressed by Slot Schema Induction (SSI), which aims to automatically induce slots from unlabeled dialogue data. Whereas previous approaches induce slots by clustering value spans extracted directly from the dialogue text, we demonstrate the power of discovering slots using a generative approach. By training a model to generate slot names and values that summarize key dialogue information with no prior task knowledge, our SSI method discovers high-quality candidate information for representing dialogue state. These discovered slot-value candidates can be easily clustered into unified slot schemas that align well with human-authored schemas. Experimental comparisons on the MultiWOZ and SGD datasets demonstrate that Generative Dialogue State Inference (GenDSI) outperforms the previous state-of-the-art on multiple aspects of the SSI task.
Personalized Binomial DAGs Learning with Network Structured Covariates
Jun 10, 2024



The causal dependence in data is often characterized by Directed Acyclic Graphical (DAG) models, widely used in many areas. Causal discovery aims to recover the DAG structure using observational data. This paper focuses on causal discovery with multi-variate count data. We are motivated by real-world web visit data, recording individual user visits to multiple websites. Building a causal diagram can help understand user behavior in transitioning between websites, inspiring operational strategy. A challenge in modeling is user heterogeneity, as users with different backgrounds exhibit varied behaviors. Additionally, social network connections can result in similar behaviors among friends. We introduce personalized Binomial DAG models to address heterogeneity and network dependency between observations, which are common in real-world applications. To learn the proposed DAG model, we develop an algorithm that embeds the network structure into a dimension-reduced covariate, learns each node's neighborhood to reduce the DAG search space, and explores the variance-mean relation to determine the ordering. Simulations show our algorithm outperforms state-of-the-art competitors in heterogeneous data. We demonstrate its practical usefulness on a real-world web visit dataset.
Leveraging Diverse Data Generation for Adaptable Zero-Shot Dialogue State Tracking
May 21, 2024



This work demonstrates that substantial gains in zero-shot dialogue state tracking (DST) accuracy can be achieved by increasing the diversity of training data using synthetic data generation techniques. Current DST training resources are severely limited in the number of application domains and slot types they cover due to the high costs of data collection, resulting in limited adaptability to new domains. The presented work overcomes this challenge using a novel, fully automatic data generation approach to create synthetic zero-shot DST training resources. Unlike previous approaches for generating DST data, the presented approach generates entirely new application domains to generate dialogues, complete with silver dialogue state annotations and slot descriptions. This approach is used to create the D0T dataset for training zero-shot DST models, which covers an unprecedented 1,000+ domains. Experiments performed on the MultiWOZ benchmark indicate that training models on diverse synthetic data yields a performance improvement of +6.7% Joint Goal Accuracy, achieving results competitive with much larger models.
Addressing Budget Allocation and Revenue Allocation in Data Market Environments Using an Adaptive Sampling Algorithm
Jun 05, 2023



High-quality machine learning models are dependent on access to high-quality training data. When the data are not already available, it is tedious and costly to obtain them. Data markets help with identifying valuable training data: model consumers pay to train a model, the market uses that budget to identify data and train the model (the budget allocation problem), and finally the market compensates data providers according to their data contribution (revenue allocation problem). For example, a bank could pay the data market to access data from other financial institutions to train a fraud detection model. Compensating data contributors requires understanding data's contribution to the model; recent efforts to solve this revenue allocation problem based on the Shapley value are inefficient to lead to practical data markets. In this paper, we introduce a new algorithm to solve budget allocation and revenue allocation problems simultaneously in linear time. The new algorithm employs an adaptive sampling process that selects data from those providers who are contributing the most to the model. Better data means that the algorithm accesses those providers more often, and more frequent accesses corresponds to higher compensation. Furthermore, the algorithm can be deployed in both centralized and federated scenarios, boosting its applicability. We provide theoretical guarantees for the algorithm that show the budget is used efficiently and the properties of revenue allocation are similar to Shapley's. Finally, we conduct an empirical evaluation to show the performance of the algorithm in practical scenarios and when compared to other baselines. Overall, we believe that the new algorithm paves the way for the implementation of practical data markets.
Latent Multimodal Functional Graphical Model Estimation
Oct 31, 2022Joint multimodal functional data acquisition, where functional data from multiple modes are measured simultaneously from the same subject, has emerged as an exciting modern approach enabled by recent engineering breakthroughs in the neurological and biological sciences. One prominent motivation to acquire such data is to enable new discoveries of the underlying connectivity by combining multimodal signals. Despite the scientific interest, there remains a gap in principled statistical methods for estimating the graph underlying multimodal functional data. To this end, we propose a new integrative framework that models the data generation process and identifies operators mapping from the observation space to the latent space. We then develop an estimator that simultaneously estimates the transformation operators and the latent graph. This estimator is based on the partial correlation operator, which we rigorously extend from the multivariate to the functional setting. Our procedure is provably efficient, with the estimator converging to a stationary point with quantifiable statistical error. Furthermore, we show recovery of the latent graph under mild conditions. Our work is applied to analyze simultaneously acquired multimodal brain imaging data where the graph indicates functional connectivity of the brain. We present simulation and empirical results that support the benefits of joint estimation.
L-SVRG and L-Katyusha with Adaptive Sampling
Jan 31, 2022



Stochastic gradient-based optimization methods, such as L-SVRG and its accelerated variant L-Katyusha [12], are widely used to train machine learning models. Theoretical and empirical performance of L-SVRG and L-Katyusha can be improved by sampling the observations from a non-uniform distribution [17]. However, to design a desired sampling distribution, Qian et al.[17] rely on prior knowledge of smoothness constants that can be computationally intractable to obtain in practice when the dimension of the model parameter is high. We propose an adaptive sampling strategy for L-SVRG and L-Katyusha that learns the sampling distribution with little computational overhead, while allowing it to change with iterates, and at the same time does not require any prior knowledge on the problem parameters. We prove convergence guarantees for L-SVRG and L-Katyusha for convex objectives when the sampling distribution changes with iterates. These results show that even without prior information, the proposed adaptive sampling strategy matches, and in some cases even surpasses, the performance of the sampling scheme in Qian et al.[17]. Extensive simulations support our theory and the practical utility of the proposed sampling scheme on real data.
Adaptive Client Sampling in Federated Learning via Online Learning with Bandit Feedback
Dec 28, 2021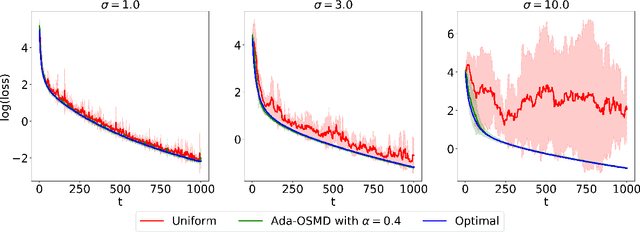
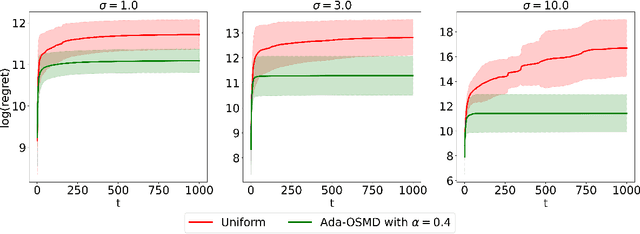
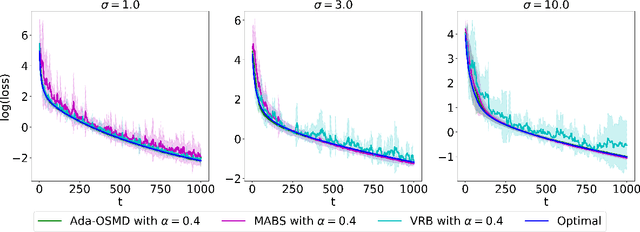
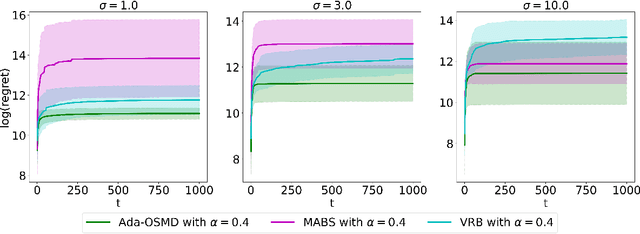
In federated learning (FL) problems, client sampling plays a key role in the convergence speed of training algorithm. However, while being an important problem in FL, client sampling is lack of study. In this paper, we propose an online learning with bandit feedback framework to understand the client sampling problem in FL. By adapting an Online Stochastic Mirror Descent algorithm to minimize the variance of gradient estimation, we propose a new adaptive client sampling algorithm. Besides, we use online ensemble method and doubling trick to automatically choose the tuning parameters in the algorithm. Theoretically, we show dynamic regret bound with comparator as the theoretically optimal sampling sequence; we also include the total variation of this sequence in our upper bound, which is a natural measure of the intrinsic difficulty of the problem. To the best of our knowledge, these theoretical contributions are novel to existing literature. Moreover, by implementing both synthetic and real data experiments, we show empirical evidence of the advantages of our proposed algorithms over widely-used uniform sampling and also other online learning based sampling strategies in previous studies. We also examine its robustness to the choice of tuning parameters. Finally, we discuss its possible extension to sampling without replacement and personalized FL objective. While the original goal is to solve client sampling problem, this work has more general applications on stochastic gradient descent and stochastic coordinate descent methods.