 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Quality-Privacy Tradeoff in Tabular Data Generation via In-Context Learning
May 06, 2026Tabular data synthesis aims to generate high-quality data while preserving privacy. However, we find that existing tabular generative models exhibit a clear tradeoff in the small-data regime: improving data quality typically comes at the cost of increased memorization of training samples, thereby weakening privacy protection. This tradeoff arises because small training sets make it difficult for dataset-specific generative models to distinguish generalizable structure from sample-specific patterns. To address this, we propose DiffICL, which formulates tabular data generation as an in-context learning problem. Instead of fitting each dataset from scratch,DiffICL leverages pretrained structural priors learned from a large collection of datasets, enabling it to infer data distributions from limited context rather than memorizing individual samples. We evaluate DiffICL on 14 real-world datasets. Results show that DiffICL improves both data quality and privacy, and generate synthetic data that provides effective data augmentation. Our findings suggest that the quality-privacy tradeoff can be improved through better training paradigms.
LimiX: Unleashing Structured-Data Modeling Capability for Generalist Intelligence
Sep 03, 2025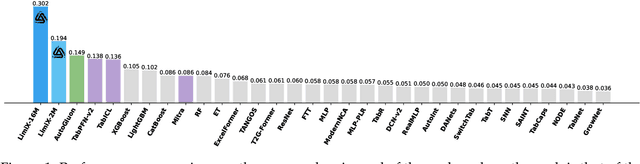
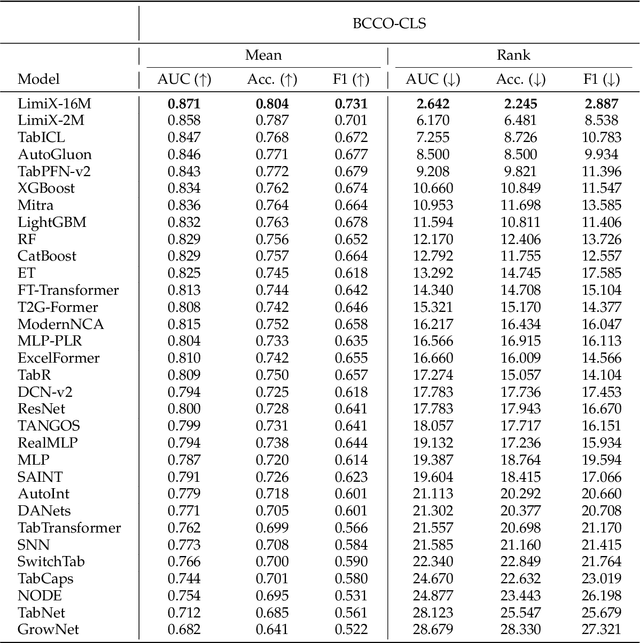
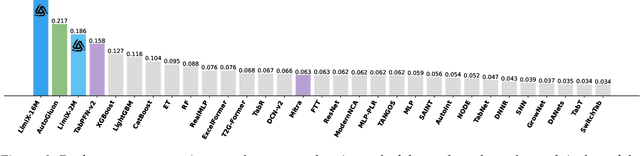
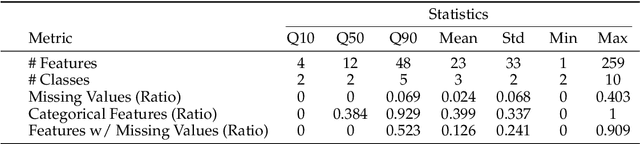
We argue that progress toward general intelligence requires complementary foundation models grounded in language, the physical world, and structured data. This report presents LimiX, the first installment of our large structured-data models (LDMs). LimiX treats structured data as a joint distribution over variables and missingness, thus capable of addressing a wide range of tabular tasks through query-based conditional prediction via a single model. LimiX is pretrained using masked joint-distribution modeling with an episodic, context-conditional objective, where the model predicts for query subsets conditioned on dataset-specific contexts, supporting rapid, training-free adaptation at inference. We evaluate LimiX across 10 large structured-data benchmarks with broad regimes of sample size, feature dimensionality, class number, categorical-to-numerical feature ratio, missingness, and sample-to-feature ratios. With a single model and a unified interface, LimiX consistently surpasses strong baselines including gradient-boosting trees, deep tabular networks, recent tabular foundation models, and automated ensembles, as shown in Figure 1 and Figure 2. The superiority holds across a wide range of tasks, such as classification, regression, missing value imputation, and data generation, often by substantial margins, while avoiding task-specific architectures or bespoke training per task. All LimiX models are publicly accessible under Apache 2.0.
HeMeNet: Heterogeneous Multichannel Equivariant Network for Protein Multitask Learning
Apr 02, 2024



Understanding and leveraging the 3D structures of proteins is central to a variety of biological and drug discovery tasks. While deep learning has been applied successfully for structure-based protein function prediction tasks, current methods usually employ distinct training for each task. However, each of the tasks is of small size, and such a single-task strategy hinders the models' performance and generalization ability. As some labeled 3D protein datasets are biologically related, combining multi-source datasets for larger-scale multi-task learning is one way to overcome this problem. In this paper, we propose a neural network model to address multiple tasks jointly upon the input of 3D protein structures. In particular, we first construct a standard structure-based multi-task benchmark called Protein-MT, consisting of 6 biologically relevant tasks, including affinity prediction and property prediction, integrated from 4 public datasets. Then, we develop a novel graph neural network for multi-task learning, dubbed Heterogeneous Multichannel Equivariant Network (HeMeNet), which is E(3) equivariant and able to capture heterogeneous relationships between different atoms. Besides, HeMeNet can achieve task-specific learning via the task-aware readout mechanism. Extensive evaluations on our benchmark verify the effectiveness of multi-task learning, and our model generally surpasses state-of-the-art models.
DELTA: Pre-train a Discriminative Encoder for Legal Case Retrieval via Structural Word Alignment
Mar 27, 2024



Recent research demonstrates the effectiveness of using pre-trained language models for legal case retrieval. Most of the existing works focus on improving the representation ability for the contextualized embedding of the [CLS] token and calculate relevance using textual semantic similarity. However, in the legal domain, textual semantic similarity does not always imply that the cases are relevant enough. Instead, relevance in legal cases primarily depends on the similarity of key facts that impact the final judgment. Without proper treatments, the discriminative ability of learned representations could be limited since legal cases are lengthy and contain numerous non-key facts. To this end, we introduce DELTA, a discriminative model designed for legal case retrieval. The basic idea involves pinpointing key facts in legal cases and pulling the contextualized embedding of the [CLS] token closer to the key facts while pushing away from the non-key facts, which can warm up the case embedding space in an unsupervised manner. To be specific, this study brings the word alignment mechanism to the contextual masked auto-encoder. First, we leverage shallow decoders to create information bottlenecks, aiming to enhance the representation ability. Second, we employ the deep decoder to enable translation between different structures, with the goal of pinpointing key facts to enhance discriminative ability. Comprehensive experiments conducted on publicly available legal benchmarks show that our approach can outperform existing state-of-the-art methods in legal case retrieval. It provides a new perspective on the in-depth understanding and processing of legal case documents.