 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNIKIE-BENCH: Benchmarking Large Multimodal Models for Key Information Extraction in Visual Documents
Feb 03, 2026Key Information Extraction (KIE) from real-world documents remains challenging due to substantial variations in layout structures, visual quality, and task-specific information requirements. Recent Large Multimodal Models (LMMs) have shown promising potential for performing end-to-end KIE directly from document images. To enable a comprehensive and systematic evaluation across realistic and diverse application scenarios, we introduce UNIKIE-BENCH, a unified benchmark designed to rigorously evaluate the KIE capabilities of LMMs. UNIKIE-BENCH consists of two complementary tracks: a constrained-category KIE track with scenario-predefined schemas that reflect practical application needs, and an open-category KIE track that extracts any key information that is explicitly present in the document. Experiments on 15 state-of-the-art LMMs reveal substantial performance degradation under diverse schema definitions, long-tail key fields, and complex layouts, along with pronounced performance disparities across different document types and scenarios. These findings underscore persistent challenges in grounding accuracy and layout-aware reasoning for LMM-based KIE. All codes and datasets are available at https://github.com/NEUIR/UNIKIE-BENCH.
BabyVision: Visual Reasoning Beyond Language
Jan 10, 2026While humans develop core visual skills long before acquiring language, contemporary Multimodal LLMs (MLLMs) still rely heavily on linguistic priors to compensate for their fragile visual understanding. We uncovered a crucial fact: state-of-the-art MLLMs consistently fail on basic visual tasks that humans, even 3-year-olds, can solve effortlessly. To systematically investigate this gap, we introduce BabyVision, a benchmark designed to assess core visual abilities independent of linguistic knowledge for MLLMs. BabyVision spans a wide range of tasks, with 388 items divided into 22 subclasses across four key categories. Empirical results and human evaluation reveal that leading MLLMs perform significantly below human baselines. Gemini3-Pro-Preview scores 49.7, lagging behind 6-year-old humans and falling well behind the average adult score of 94.1. These results show despite excelling in knowledge-heavy evaluations, current MLLMs still lack fundamental visual primitives. Progress in BabyVision represents a step toward human-level visual perception and reasoning capabilities. We also explore solving visual reasoning with generation models by proposing BabyVision-Gen and automatic evaluation toolkit. Our code and benchmark data are released at https://github.com/UniPat-AI/BabyVision for reproduction.
Qwen3-VL-Embedding and Qwen3-VL-Reranker: A Unified Framework for State-of-the-Art Multimodal Retrieval and Ranking
Jan 08, 2026In this report, we introduce the Qwen3-VL-Embedding and Qwen3-VL-Reranker model series, the latest extensions of the Qwen family built on the Qwen3-VL foundation model. Together, they provide an end-to-end pipeline for high-precision multimodal search by mapping diverse modalities, including text, images, document images, and video, into a unified representation space. The Qwen3-VL-Embedding model employs a multi-stage training paradigm, progressing from large-scale contrastive pre-training to reranking model distillation, to generate semantically rich high-dimensional vectors. It supports Matryoshka Representation Learning, enabling flexible embedding dimensions, and handles inputs up to 32k tokens. Complementing this, Qwen3-VL-Reranker performs fine-grained relevance estimation for query-document pairs using a cross-encoder architecture with cross-attention mechanisms. Both model series inherit the multilingual capabilities of Qwen3-VL, supporting more than 30 languages, and are released in $\textbf{2B}$ and $\textbf{8B}$ parameter sizes to accommodate diverse deployment requirements. Empirical evaluations demonstrate that the Qwen3-VL-Embedding series achieves state-of-the-art results across diverse multimodal embedding evaluation benchmarks. Specifically, Qwen3-VL-Embedding-8B attains an overall score of $\textbf{77.8}$ on MMEB-V2, ranking first among all models (as of January 8, 2025). This report presents the architecture, training methodology, and practical capabilities of the series, demonstrating their effectiveness on various multimodal retrieval tasks, including image-text retrieval, visual question answering, and video-text matching.
DocThinker: Explainable Multimodal Large Language Models with Rule-based Reinforcement Learning for Document Understanding
Aug 12, 2025Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities in document understanding. However, their reasoning processes remain largely black-box, making it difficult to ensure reliability and trustworthiness, especially in high-stakes domains such as legal, financial, and medical document analysis. Existing methods use fixed Chain-of-Thought (CoT) reasoning with supervised fine-tuning (SFT) but suffer from catastrophic forgetting, poor adaptability, and limited generalization across domain tasks. In this paper, we propose DocThinker, a rule-based Reinforcement Learning (RL) framework for dynamic inference-time reasoning. Instead of relying on static CoT templates, DocThinker autonomously refines reasoning strategies via policy learning, generating explainable intermediate results, including structured reasoning processes, rephrased questions, regions of interest (RoI) supporting the answer, and the final answer. By integrating multi-objective rule-based rewards and KL-constrained optimization, our method mitigates catastrophic forgetting and enhances both adaptability and transparency. Extensive experiments on multiple benchmarks demonstrate that DocThinker significantly improves generalization while producing more explainable and human-understandable reasoning steps. Our findings highlight RL as a powerful alternative for enhancing explainability and adaptability in MLLM-based document understanding. Code will be available at https://github.com/wenwenyu/DocThinker.
MAER-Nav: Bidirectional Motion Learning Through Mirror-Augmented Experience Replay for Robot Navigation
Mar 31, 2025



Deep Reinforcement Learning (DRL) based navigation methods have demonstrated promising results for mobile robots, but suffer from limited action flexibility in confined spaces. Conventional DRL approaches predominantly learn forward-motion policies, causing robots to become trapped in complex environments where backward maneuvers are necessary for recovery. This paper presents MAER-Nav (Mirror-Augmented Experience Replay for Robot Navigation), a novel framework that enables bidirectional motion learning without requiring explicit failure-driven hindsight experience replay or reward function modifications. Our approach integrates a mirror-augmented experience replay mechanism with curriculum learning to generate synthetic backward navigation experiences from successful trajectories. Experimental results in both simulation and real-world environments demonstrate that MAER-Nav significantly outperforms state-of-the-art methods while maintaining strong forward navigation capabilities. The framework effectively bridges the gap between the comprehensive action space utilization of traditional planning methods and the environmental adaptability of learning-based approaches, enabling robust navigation in scenarios where conventional DRL methods consistently fail.
Generative Compositor for Few-Shot Visual Information Extraction
Mar 21, 2025Visual Information Extraction (VIE), aiming at extracting structured information from visually rich document images, plays a pivotal role in document processing. Considering various layouts, semantic scopes, and languages, VIE encompasses an extensive range of types, potentially numbering in the thousands. However, many of these types suffer from a lack of training data, which poses significant challenges. In this paper, we propose a novel generative model, named Generative Compositor, to address the challenge of few-shot VIE. The Generative Compositor is a hybrid pointer-generator network that emulates the operations of a compositor by retrieving words from the source text and assembling them based on the provided prompts. Furthermore, three pre-training strategies are employed to enhance the model's perception of spatial context information. Besides, a prompt-aware resampler is specially designed to enable efficient matching by leveraging the entity-semantic prior contained in prompts. The introduction of the prompt-based retrieval mechanism and the pre-training strategies enable the model to acquire more effective spatial and semantic clues with limited training samples. Experiments demonstrate that the proposed method achieves highly competitive results in the full-sample training, while notably outperforms the baseline in the 1-shot, 5-shot, and 10-shot settings.
Enhancing Deep Reinforcement Learning-based Robot Navigation Generalization through Scenario Augmentation
Mar 03, 2025



This work focuses on enhancing the generalization performance of deep reinforcement learning-based robot navigation in unseen environments. We present a novel data augmentation approach called scenario augmentation, which enables robots to navigate effectively across diverse settings without altering the training scenario. The method operates by mapping the robot's observation into an imagined space, generating an imagined action based on this transformed observation, and then remapping this action back to the real action executed in simulation. Through scenario augmentation, we conduct extensive comparative experiments to investigate the underlying causes of suboptimal navigation behaviors in unseen environments. Our analysis indicates that limited training scenarios represent the primary factor behind these undesired behaviors. Experimental results confirm that scenario augmentation substantially enhances the generalization capabilities of deep reinforcement learning-based navigation systems. The improved navigation framework demonstrates exceptional performance by producing near-optimal trajectories with significantly reduced navigation time in real-world applications.
Beyond Visibility Limits: A DRL-Based Navigation Strategy for Unexpected Obstacles
Mar 03, 2025



Distance-based reward mechanisms in deep reinforcement learning (DRL) navigation systems suffer from critical safety limitations in dynamic environments, frequently resulting in collisions when visibility is restricted. We propose DRL-NSUO, a novel navigation strategy for unexpected obstacles that leverages the rate of change in LiDAR data as a dynamic environmental perception element. Our approach incorporates a composite reward function with environmental change rate constraints and dynamically adjusted weights through curriculum learning, enabling robots to autonomously balance between path efficiency and safety maximization. We enhance sensitivity to nearby obstacles by implementing short-range feature preprocessing of LiDAR data. Experimental results demonstrate that this method significantly improves both robot and pedestrian safety in complex scenarios compared to traditional DRL-based methods. When evaluated on the BARN navigation dataset, our method achieved superior performance with success rates of 94.0% at 0.5 m/s and 91.0% at 1.0 m/s, outperforming conservative obstacle expansion strategies. These results validate DRL-NSUO's enhanced practicality and safety for human-robot collaborative environments, including intelligent logistics applications.
OmniParser V2: Structured-Points-of-Thought for Unified Visual Text Parsing and Its Generality to Multimodal Large Language Models
Feb 22, 2025Visually-situated text parsing (VsTP) has recently seen notable advancements, driven by the growing demand for automated document understanding and the emergence of large language models capable of processing document-based questions. While various methods have been proposed to tackle the complexities of VsTP, existing solutions often rely on task-specific architectures and objectives for individual tasks. This leads to modal isolation and complex workflows due to the diversified targets and heterogeneous schemas. In this paper, we introduce OmniParser V2, a universal model that unifies VsTP typical tasks, including text spotting, key information extraction, table recognition, and layout analysis, into a unified framework. Central to our approach is the proposed Structured-Points-of-Thought (SPOT) prompting schemas, which improves model performance across diverse scenarios by leveraging a unified encoder-decoder architecture, objective, and input\&output representation. SPOT eliminates the need for task-specific architectures and loss functions, significantly simplifying the processing pipeline. Our extensive evaluations across four tasks on eight different datasets show that OmniParser V2 achieves state-of-the-art or competitive results in VsTP. Additionally, we explore the integration of SPOT within a multimodal large language model structure, further enhancing text localization and recognition capabilities, thereby confirming the generality of SPOT prompting technique. The code is available at \href{https://github.com/AlibabaResearch/AdvancedLiterateMachinery}{AdvancedLiterateMachinery}.
Qwen2.5-VL Technical Report
Feb 19, 2025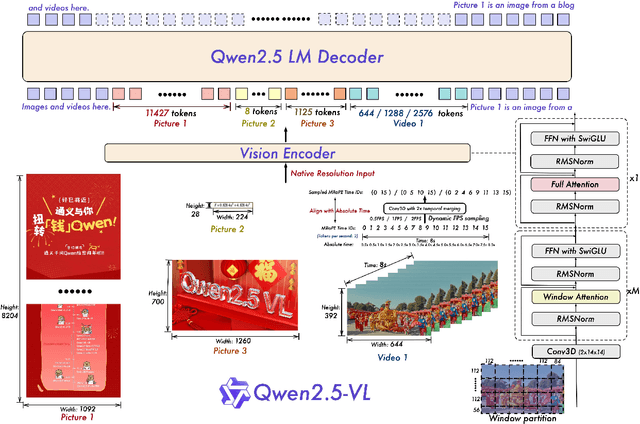
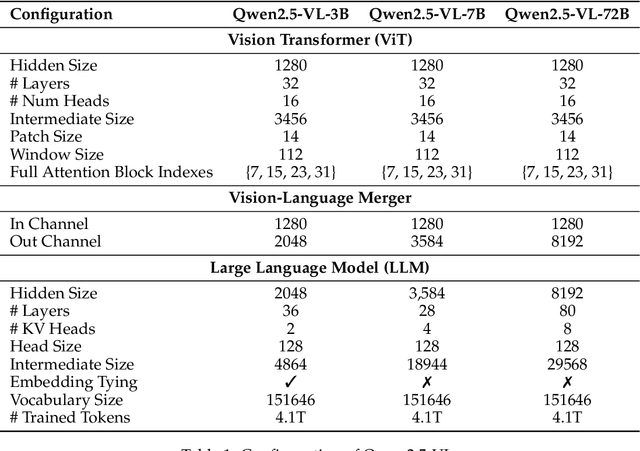
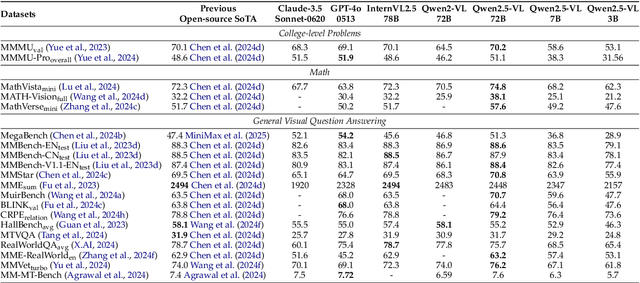
We introduce Qwen2.5-VL, the latest flagship model of Qwen vision-language series, which demonstrates significant advancements in both foundational capabilities and innovative functionalities. Qwen2.5-VL achieves a major leap forward in understanding and interacting with the world through enhanced visual recognition, precise object localization, robust document parsing, and long-video comprehension. A standout feature of Qwen2.5-VL is its ability to localize objects using bounding boxes or points accurately. It provides robust structured data extraction from invoices, forms, and tables, as well as detailed analysis of charts, diagrams, and layouts. To handle complex inputs, Qwen2.5-VL introduces dynamic resolution processing and absolute time encoding, enabling it to process images of varying sizes and videos of extended durations (up to hours) with second-level event localization. This allows the model to natively perceive spatial scales and temporal dynamics without relying on traditional normalization techniques. By training a native dynamic-resolution Vision Transformer (ViT) from scratch and incorporating Window Attention, we reduce computational overhead while maintaining native resolution. As a result, Qwen2.5-VL excels not only in static image and document understanding but also as an interactive visual agent capable of reasoning, tool usage, and task execution in real-world scenarios such as operating computers and mobile devices. Qwen2.5-VL is available in three sizes, addressing diverse use cases from edge AI to high-performance computing. The flagship Qwen2.5-VL-72B model matches state-of-the-art models like GPT-4o and Claude 3.5 Sonnet, particularly excelling in document and diagram understanding. Additionally, Qwen2.5-VL maintains robust linguistic performance, preserving the core language competencies of the Qwen2.5 LLM.