 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContribution-aware Token Compression for Efficient Video Understanding via Reinforcement Learning
Feb 02, 2026Video large language models have demonstrated remarkable capabilities in video understanding tasks. However, the redundancy of video tokens introduces significant computational overhead during inference, limiting their practical deployment. Many compression algorithms are proposed to prioritize retaining features with the highest attention scores to minimize perturbations in attention computations. However, the correlation between attention scores and their actual contribution to correct answers remains ambiguous. To address the above limitation, we propose a novel \textbf{C}ontribution-\textbf{a}ware token \textbf{Co}mpression algorithm for \textbf{VID}eo understanding (\textbf{CaCoVID}) that explicitly optimizes the token selection policy based on the contribution of tokens to correct predictions. First, we introduce a reinforcement learning-based framework that optimizes a policy network to select video token combinations with the greatest contribution to correct predictions. This paradigm shifts the focus from passive token preservation to active discovery of optimal compressed token combinations. Secondly, we propose a combinatorial policy optimization algorithm with online combination space sampling, which dramatically reduces the exploration space for video token combinations and accelerates the convergence speed of policy optimization. Extensive experiments on diverse video understanding benchmarks demonstrate the effectiveness of CaCoVID. Codes will be released.
DART: Diffusion-Inspired Speculative Decoding for Fast LLM Inference
Jan 27, 2026Speculative decoding is an effective and lossless approach for accelerating LLM inference. However, existing widely adopted model-based draft designs, such as EAGLE3, improve accuracy at the cost of multi-step autoregressive inference, resulting in high drafting latency and ultimately rendering the drafting stage itself a performance bottleneck. Inspired by diffusion-based large language models (dLLMs), we propose DART, which leverages parallel generation to reduce drafting latency. DART predicts logits for multiple future masked positions in parallel within a single forward pass based on hidden states of the target model, thereby eliminating autoregressive rollouts in the draft model while preserving a lightweight design. Based on these parallel logit predictions, we further introduce an efficient tree pruning algorithm that constructs high-quality draft token trees with N-gram-enforced semantic continuity. DART substantially reduces draft-stage overhead while preserving high draft accuracy, leading to significantly improved end-to-end decoding speed. Experimental results demonstrate that DART achieves a 2.03x--3.44x wall-clock time speedup across multiple datasets, surpassing EAGLE3 by 30% on average and offering a practical speculative decoding framework. Code is released at https://github.com/fvliang/DART.
OrchANN: A Unified I/O Orchestration Framework for Skewed Out-of-Core Vector Search
Dec 28, 2025Approximate nearest neighbor search (ANNS) at billion scale is fundamentally an out-of-core problem: vectors and indexes live on SSD, so performance is dominated by I/O rather than compute. Under skewed semantic embeddings, existing out-of-core systems break down: a uniform local index mismatches cluster scales, static routing misguides queries and inflates the number of probed partitions, and pruning is incomplete at the cluster level and lossy at the vector level, triggering "fetch-to-discard" reranking on raw vectors. We present OrchANN, an out-of-core ANNS engine that uses an I/O orchestration model for unified I/O governance along the route-access-verify pipeline. OrchANN selects a heterogeneous local index per cluster via offline auto-profiling, maintains a query-aware in-memory navigation graph that adapts to skewed workloads, and applies multi-level pruning with geometric bounds to filter both clusters and vectors before issuing SSD reads. Across five standard datasets under strict out-of-core constraints, OrchANN outperforms four baselines including DiskANN, Starling, SPANN, and PipeANN in both QPS and latency while reducing SSD accesses. Furthermore, OrchANN delivers up to 17.2x higher QPS and 25.0x lower latency than competing systems without sacrificing accuracy.
StreamKV: Streaming Video Question-Answering with Segment-based KV Cache Retrieval and Compression
Nov 10, 2025



Video Large Language Models (Video-LLMs) have demonstrated significant potential in the areas of video captioning, search, and summarization. However, current Video-LLMs still face challenges with long real-world videos. Recent methods have introduced a retrieval mechanism that retrieves query-relevant KV caches for question answering, enhancing the efficiency and accuracy of long real-world videos. However, the compression and retrieval of KV caches are still not fully explored. In this paper, we propose \textbf{StreamKV}, a training-free framework that seamlessly equips Video-LLMs with advanced KV cache retrieval and compression. Compared to previous methods that used uniform partitioning, StreamKV dynamically partitions video streams into semantic segments, which better preserves semantic information. For KV cache retrieval, StreamKV calculates a summary vector for each segment to retain segment-level information essential for retrieval. For KV cache compression, StreamKV introduces a guidance prompt designed to capture the key semantic elements within each segment, ensuring only the most informative KV caches are retained for answering questions. Moreover, StreamKV unifies KV cache retrieval and compression within a single module, performing both in a layer-adaptive manner, thereby further improving the effectiveness of streaming video question answering. Extensive experiments on public StreamingVQA benchmarks demonstrate that StreamKV significantly outperforms existing Online Video-LLMs, achieving superior accuracy while substantially improving both memory efficiency and computational latency. The code has been released at https://github.com/sou1p0wer/StreamKV.
MMG-Vid: Maximizing Marginal Gains at Segment-level and Token-level for Efficient Video LLMs
Aug 28, 2025



Video Large Language Models (VLLMs) excel in video understanding, but their excessive visual tokens pose a significant computational challenge for real-world applications. Current methods aim to enhance inference efficiency by visual token pruning. However, they do not consider the dynamic characteristics and temporal dependencies of video frames, as they perceive video understanding as a multi-frame task. To address these challenges, we propose MMG-Vid, a novel training-free visual token pruning framework that removes redundancy by Maximizing Marginal Gains at both segment-level and token-level. Specifically, we first divide the video into segments based on frame similarity, and then dynamically allocate the token budget for each segment to maximize the marginal gain of each segment. Subsequently, we propose a temporal-guided DPC algorithm that jointly models inter-frame uniqueness and intra-frame diversity, thereby maximizing the marginal gain of each token. By combining both stages, MMG-Vid can maximize the utilization of the limited token budget, significantly improving efficiency while maintaining strong performance. Extensive experiments demonstrate that MMG-Vid can maintain over 99.5% of the original performance, while effectively reducing 75% visual tokens and accelerating the prefilling stage by 3.9x on LLaVA-OneVision-7B. Code will be released soon.
Chordless Structure: A Pathway to Simple and Expressive GNNs
May 25, 2025Researchers have proposed various methods of incorporating more structured information into the design of Graph Neural Networks (GNNs) to enhance their expressiveness. However, these methods are either computationally expensive or lacking in provable expressiveness. In this paper, we observe that the chords increase the complexity of the graph structure while contributing little useful information in many cases. In contrast, chordless structures are more efficient and effective for representing the graph. Therefore, when leveraging the information of cycles, we choose to omit the chords. Accordingly, we propose a Chordless Structure-based Graph Neural Network (CSGNN) and prove that its expressiveness is strictly more powerful than the k-hop GNN (KPGNN) with polynomial complexity. Experimental results on real-world datasets demonstrate that CSGNN outperforms existing GNNs across various graph tasks while incurring lower computational costs and achieving better performance than the GNNs of 3-WL expressiveness.
FlashForge: Ultra-Efficient Prefix-Aware Attention for LLM Decoding
May 23, 2025
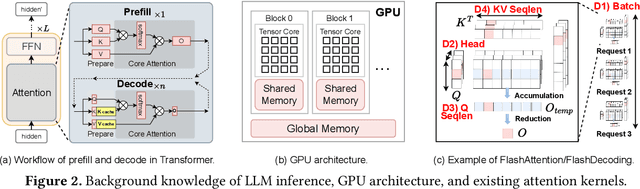
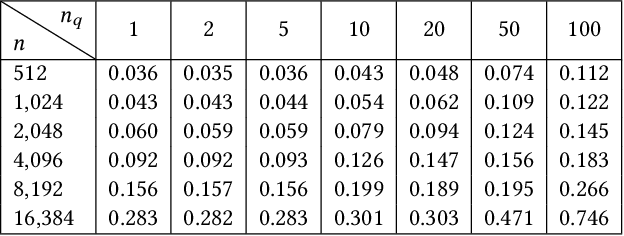

Prefix-sharing among multiple prompts presents opportunities to combine the operations of the shared prefix, while attention computation in the decode stage, which becomes a critical bottleneck with increasing context lengths, is a memory-intensive process requiring heavy memory access on the key-value (KV) cache of the prefixes. Therefore, in this paper, we explore the potential of prefix-sharing in the attention computation of the decode stage. However, the tree structure of the prefix-sharing mechanism presents significant challenges for attention computation in efficiently processing shared KV cache access patterns while managing complex dependencies and balancing irregular workloads. To address the above challenges, we propose a dedicated attention kernel to combine the memory access of shared prefixes in the decoding stage, namely FlashForge. FlashForge delivers two key innovations: a novel shared-prefix attention kernel that optimizes memory hierarchy and exploits both intra-block and inter-block parallelism, and a comprehensive workload balancing mechanism that efficiently estimates cost, divides tasks, and schedules execution. Experimental results show that FlashForge achieves an average 1.9x speedup and 120.9x memory access reduction compared to the state-of-the-art FlashDecoding kernel regarding attention computation in the decode stage and 3.8x end-to-end time per output token compared to the vLLM.
Ultra-Low Complexity On-Orbit Compression for Remote Sensing Imagery via Block Modulated Imaging
Dec 24, 2024The growing field of remote sensing faces a challenge: the ever-increasing size and volume of imagery data are exceeding the storage and transmission capabilities of satellite platforms. Efficient compression of remote sensing imagery is a critical solution to alleviate these burdens on satellites. However, existing compression methods are often too computationally expensive for satellites. With the continued advancement of compressed sensing theory, single-pixel imaging emerges as a powerful tool that brings new possibilities for on-orbit image compression. However, it still suffers from prolonged imaging times and the inability to perform high-resolution imaging, hindering its practical application. This paper advances the study of compressed sensing in remote sensing image compression, proposing Block Modulated Imaging (BMI). By requiring only a single exposure, BMI significantly enhances imaging acquisition speeds. Additionally, BMI obviates the need for digital micromirror devices and surpasses limitations in image resolution. Furthermore, we propose a novel decoding network specifically designed to reconstruct images compressed under the BMI framework. Leveraging the gated 3D convolutions and promoting efficient information flow across stages through a Two-Way Cross-Attention module, our decoding network exhibits demonstrably superior reconstruction performance. Extensive experiments conducted on multiple renowned remote sensing datasets unequivocally demonstrate the efficacy of our proposed method. To further validate its practical applicability, we developed and tested a prototype of the BMI-based camera, which has shown promising potential for on-orbit image compression. The code is available at https://github.com/Johnathan218/BMNet.
MVPaint: Synchronized Multi-View Diffusion for Painting Anything 3D
Nov 04, 2024



Texturing is a crucial step in the 3D asset production workflow, which enhances the visual appeal and diversity of 3D assets. Despite recent advancements in Text-to-Texture (T2T) generation, existing methods often yield subpar results, primarily due to local discontinuities, inconsistencies across multiple views, and their heavy dependence on UV unwrapping outcomes. To tackle these challenges, we propose a novel generation-refinement 3D texturing framework called MVPaint, which can generate high-resolution, seamless textures while emphasizing multi-view consistency. MVPaint mainly consists of three key modules. 1) Synchronized Multi-view Generation (SMG). Given a 3D mesh model, MVPaint first simultaneously generates multi-view images by employing an SMG model, which leads to coarse texturing results with unpainted parts due to missing observations. 2) Spatial-aware 3D Inpainting (S3I). To ensure complete 3D texturing, we introduce the S3I method, specifically designed to effectively texture previously unobserved areas. 3) UV Refinement (UVR). Furthermore, MVPaint employs a UVR module to improve the texture quality in the UV space, which first performs a UV-space Super-Resolution, followed by a Spatial-aware Seam-Smoothing algorithm for revising spatial texturing discontinuities caused by UV unwrapping. Moreover, we establish two T2T evaluation benchmarks: the Objaverse T2T benchmark and the GSO T2T benchmark, based on selected high-quality 3D meshes from the Objaverse dataset and the entire GSO dataset, respectively. Extensive experimental results demonstrate that MVPaint surpasses existing state-of-the-art methods. Notably, MVPaint could generate high-fidelity textures with minimal Janus issues and highly enhanced cross-view consistency.
Revisiting SLO and Goodput Metrics in LLM Serving
Oct 18, 2024



Large language models (LLMs) have achieved remarkable performance and are widely deployed in various applications, while the serving of LLM inference has raised concerns about user experience and serving throughput. Accordingly, service level objectives (SLOs) and goodput-the number of requests that meet SLOs per second-are introduced to evaluate the performance of LLM serving. However, existing metrics fail to capture the nature of user experience. We observe two ridiculous phenomena in existing metrics: 1) delaying token delivery can smooth the tail time between tokens (tail TBT) of a request and 2) dropping the request that fails to meet the SLOs midway can improve goodput. In this paper, we revisit SLO and goodput metrics in LLM serving and propose a unified metric framework smooth goodput including SLOs and goodput to reflect the nature of user experience in LLM serving. The framework can adapt to specific goals of different tasks by setting parameters. We re-evaluate the performance of different LLM serving systems under multiple workloads based on this unified framework and provide possible directions for future optimization of existing strategies. We hope that this framework can provide a unified standard for evaluating LLM serving and foster researches in the field of LLM serving optimization to move in a cohesive direction.