 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGATHER: Convergence-Centric Hyper-Entity Retrieval for Zero-Shot Cell-Type Annotation
May 07, 2026Zero-shot single-cell cell-type annotation aims to determine a cell's type from a given set of expressed genes without any training. Existing knowledge-graph-based RAG approaches retrieve evidence by expanding from source entities and relying on iterative LLM reasoning. However, in this setting each query contains tens to hundreds of genes, where no single gene is decisive and the label emerges only from their collective co-occurrence. Such hyper-entity queries fundamentally challenge local, entity-wise exploration strategies, which reason from individual genes, leading to poor scalability and substantial LLM cost. We propose GATHER (Graph-Aware Traversal with Hyper-Entity Retrieval), a convergence-centric retriever tailored to hyper-entity queries. It performs global multi-source graph traversal and identifies topological convergence points -- nodes jointly reachable from many input genes. These convergence nodes act as high-information hyper-entities that capture entity synergy. By incorporating node- and path-importance scoring, GATHER selects informative evidence entirely without LLM involvement during retrieval. Instantiated on a self-constructed cell-centric biological knowledge graph (VCKG), GATHER outperforms strong KG-RAG baselines (ToG, ToG-2, RoG, PoG) on two datasets (Immune and Lung), achieving the highest exact-match accuracy (27.45% and 59.64%) with only a single LLM call per sample, compared to 2--61 calls for KG-RAG baselines. Our results demonstrate that convergence nodes compress multi-entity signals into compact, high-information evidence that conveys more per item than multi-hop paths, providing an efficient global alternative to local entity-wise reasoning.
SC-Arena: A Natural Language Benchmark for Single-Cell Reasoning with Knowledge-Augmented Evaluation
Feb 26, 2026Large language models (LLMs) are increasingly applied in scientific research, offering new capabilities for knowledge discovery and reasoning. In single-cell biology, however, evaluation practices for both general and specialized LLMs remain inadequate: existing benchmarks are fragmented across tasks, adopt formats such as multiple-choice classification that diverge from real-world usage, and rely on metrics lacking interpretability and biological grounding. We present SC-ARENA, a natural language evaluation framework tailored to single-cell foundation models. SC-ARENA formalizes a virtual cell abstraction that unifies evaluation targets by representing both intrinsic attributes and gene-level interactions. Within this paradigm, we define five natural language tasks (cell type annotation, captioning, generation, perturbation prediction, and scientific QA) that probe core reasoning capabilities in cellular biology. To overcome the limitations of brittle string-matching metrics, we introduce knowledge-augmented evaluation, which incorporates external ontologies, marker databases, and scientific literature to support biologically faithful and interpretable judgments. Experiments and analysis across both general-purpose and domain-specialized LLMs demonstrate that (i) under the Virtual Cell unified evaluation paradigm, current models achieve uneven performance on biologically complex tasks, particularly those demanding mechanistic or causal understanding; and (ii) our knowledge-augmented evaluation framework ensures biological correctness, provides interpretable, evidence-grounded rationales, and achieves high discriminative capacity, overcoming the brittleness and opacity of conventional metrics. SC-Arena thus provides a unified and interpretable framework for assessing LLMs in single-cell biology, pointing toward the development of biology-aligned, generalizable foundation models.
DART: Diffusion-Inspired Speculative Decoding for Fast LLM Inference
Jan 27, 2026Speculative decoding is an effective and lossless approach for accelerating LLM inference. However, existing widely adopted model-based draft designs, such as EAGLE3, improve accuracy at the cost of multi-step autoregressive inference, resulting in high drafting latency and ultimately rendering the drafting stage itself a performance bottleneck. Inspired by diffusion-based large language models (dLLMs), we propose DART, which leverages parallel generation to reduce drafting latency. DART predicts logits for multiple future masked positions in parallel within a single forward pass based on hidden states of the target model, thereby eliminating autoregressive rollouts in the draft model while preserving a lightweight design. Based on these parallel logit predictions, we further introduce an efficient tree pruning algorithm that constructs high-quality draft token trees with N-gram-enforced semantic continuity. DART substantially reduces draft-stage overhead while preserving high draft accuracy, leading to significantly improved end-to-end decoding speed. Experimental results demonstrate that DART achieves a 2.03x--3.44x wall-clock time speedup across multiple datasets, surpassing EAGLE3 by 30% on average and offering a practical speculative decoding framework. Code is released at https://github.com/fvliang/DART.
FlashForge: Ultra-Efficient Prefix-Aware Attention for LLM Decoding
May 23, 2025
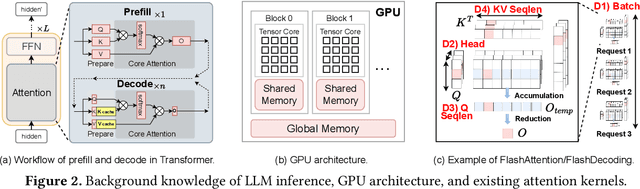
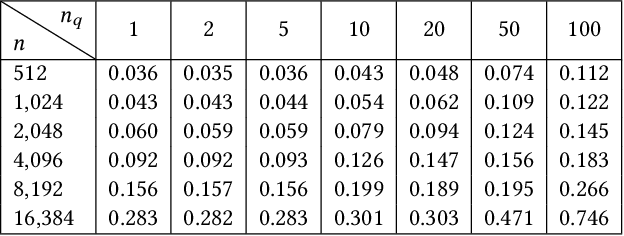

Prefix-sharing among multiple prompts presents opportunities to combine the operations of the shared prefix, while attention computation in the decode stage, which becomes a critical bottleneck with increasing context lengths, is a memory-intensive process requiring heavy memory access on the key-value (KV) cache of the prefixes. Therefore, in this paper, we explore the potential of prefix-sharing in the attention computation of the decode stage. However, the tree structure of the prefix-sharing mechanism presents significant challenges for attention computation in efficiently processing shared KV cache access patterns while managing complex dependencies and balancing irregular workloads. To address the above challenges, we propose a dedicated attention kernel to combine the memory access of shared prefixes in the decoding stage, namely FlashForge. FlashForge delivers two key innovations: a novel shared-prefix attention kernel that optimizes memory hierarchy and exploits both intra-block and inter-block parallelism, and a comprehensive workload balancing mechanism that efficiently estimates cost, divides tasks, and schedules execution. Experimental results show that FlashForge achieves an average 1.9x speedup and 120.9x memory access reduction compared to the state-of-the-art FlashDecoding kernel regarding attention computation in the decode stage and 3.8x end-to-end time per output token compared to the vLLM.