 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Scheduling Framework for Efficient MoE Inference on Edge GPU-NDP Systems
Jan 07, 2026Mixture-of-Experts (MoE) models facilitate edge deployment by decoupling model capacity from active computation, yet their large memory footprint drives the need for GPU systems with near-data processing (NDP) capabilities that offload experts to dedicated processing units. However, deploying MoE models on such edge-based GPU-NDP systems faces three critical challenges: 1) severe load imbalance across NDP units due to non-uniform expert selection and expert parallelism, 2) insufficient GPU utilization during expert computation within NDP units, and 3) extensive data pre-profiling necessitated by unpredictable expert activation patterns for pre-fetching. To address these challenges, this paper proposes an efficient inference framework featuring three key optimizations. First, the underexplored tensor parallelism in MoE inference is exploited to partition and compute large expert parameters across multiple NDP units simultaneously towards edge low-batch scenarios. Second, a load-balancing-aware scheduling algorithm distributes expert computations across NDP units and GPU to maximize resource utilization. Third, a dataset-free pre-fetching strategy proactively loads frequently accessed experts to minimize activation delays. Experimental results show that our framework enables GPU-NDP systems to achieve 2.41x on average and up to 2.56x speedup in end-to-end latency compared to state-of-the-art approaches, significantly enhancing MoE inference efficiency in resource-constrained environments.
P3-LLM: An Integrated NPU-PIM Accelerator for LLM Inference Using Hybrid Numerical Formats
Nov 16, 2025



The substantial memory bandwidth and computational demands of large language models (LLMs) present critical challenges for efficient inference. To tackle this, the literature has explored heterogeneous systems that combine neural processing units (NPUs) with DRAM-based processing-in-memory (PIM) for LLM acceleration. However, existing high-precision (e.g., FP16) PIM compute units incur significant area and power overhead in DRAM technology, limiting the effective computation throughput. In this paper, we introduce P3-LLM, a novel NPU-PIM integrated accelerator for LLM inference using hybrid numerical formats. Our approach is threefold: First, we propose a flexible mixed-precision quantization scheme, which leverages hybrid numerical formats to quantize different LLM operands with high compression efficiency and minimal accuracy loss. Second, we architect an efficient PIM accelerator for P3-LLM, featuring enhanced compute units to support hybrid numerical formats. Our careful choice of numerical formats allows to co-design low-precision PIM compute units that significantly boost the computation throughput under iso-area constraints. Third, we optimize the low-precision dataflow of different LLM modules by applying operator fusion to minimize the overhead of runtime dequantization. Evaluation on a diverse set of representative LLMs and tasks demonstrates that P3-LLM achieves state-of-the-art accuracy in terms of both KV-cache quantization and weight-activation quantization. Combining the proposed quantization scheme with PIM architecture co-design, P3-LLM yields an average of $4.9\times$, $2.0\times$, and $3.4\times$ speedups over the state-of-the-art LLM accelerators HBM-PIM, Ecco, and Pimba, respectively. Our quantization code is available at https://github.com/yc2367/P3-LLM.git
Precision-Scalable Microscaling Datapaths with Optimized Reduction Tree for Efficient NPU Integration
Nov 09, 2025Emerging continual learning applications necessitate next-generation neural processing unit (NPU) platforms to support both training and inference operations. The promising Microscaling (MX) standard enables narrow bit-widths for inference and large dynamic ranges for training. However, existing MX multiply-accumulate (MAC) designs face a critical trade-off: integer accumulation requires expensive conversions from narrow floating-point products, while FP32 accumulation suffers from quantization losses and costly normalization. To address these limitations, we propose a hybrid precision-scalable reduction tree for MX MACs that combines the benefits of both approaches, enabling efficient mixed-precision accumulation with controlled accuracy relaxation. Moreover, we integrate an 8x8 array of these MACs into the state-of-the-art (SotA) NPU integration platform, SNAX, to provide efficient control and data transfer to our optimized precision-scalable MX datapath. We evaluate our design both on MAC and system level and compare it to the SotA. Our integrated system achieves an energy efficiency of 657, 1438-1675, and 4065 GOPS/W, respectively, for MXINT8, MXFP8/6, and MXFP4, with a throughput of 64, 256, and 512 GOPS.
APT-LLM: Exploiting Arbitrary-Precision Tensor Core Computing for LLM Acceleration
Aug 26, 2025Large language models (LLMs) have revolutionized AI applications, yet their enormous computational demands severely limit deployment and real-time performance. Quantization methods can help reduce computational costs, however, attaining the extreme efficiency associated with ultra-low-bit quantized LLMs at arbitrary precision presents challenges on GPUs. This is primarily due to the limited support for GPU Tensor Cores, inefficient memory management, and inflexible kernel optimizations. To tackle these challenges, we propose a comprehensive acceleration scheme for arbitrary precision LLMs, namely APT-LLM. Firstly, we introduce a novel data format, bipolar-INT, which allows for efficient and lossless conversion with signed INT, while also being more conducive to parallel computation. We also develop a matrix multiplication (MatMul) method allowing for arbitrary precision by dismantling and reassembling matrices at the bit level. This method provides flexible precision and optimizes the utilization of GPU Tensor Cores. In addition, we propose a memory management system focused on data recovery, which strategically employs fast shared memory to substantially increase kernel execution speed and reduce memory access latency. Finally, we develop a kernel mapping method that dynamically selects the optimal configurable hyperparameters of kernels for varying matrix sizes, enabling optimal performance across different LLM architectures and precision settings. In LLM inference, APT-LLM achieves up to a 3.99$\times$ speedup compared to FP16 baselines and a 2.16$\times$ speedup over NVIDIA CUTLASS INT4 acceleration on RTX 3090. On RTX 4090 and H800, APT-LLM achieves up to 2.44$\times$ speedup over FP16 and 1.65$\times$ speedup over CUTLASS integer baselines.
Efficient Precision-Scalable Hardware for Microscaling (MX) Processing in Robotics Learning
May 28, 2025



Autonomous robots require efficient on-device learning to adapt to new environments without cloud dependency. For this edge training, Microscaling (MX) data types offer a promising solution by combining integer and floating-point representations with shared exponents, reducing energy consumption while maintaining accuracy. However, the state-of-the-art continuous learning processor, namely Dacapo, faces limitations with its MXINT-only support and inefficient vector-based grouping during backpropagation. In this paper, we present, to the best of our knowledge, the first work that addresses these limitations with two key innovations: (1) a precision-scalable arithmetic unit that supports all six MX data types by exploiting sub-word parallelism and unified integer and floating-point processing; and (2) support for square shared exponent groups to enable efficient weight handling during backpropagation, removing storage redundancy and quantization overhead. We evaluate our design against Dacapo under iso-peak-throughput on four robotics workloads in TSMC 16nm FinFET technology at 500MHz, reaching a 25.6% area reduction, a 51% lower memory footprint, and 4x higher effective training throughput while achieving comparable energy-efficiency, enabling efficient robotics continual learning at the edge.
Enable Lightweight and Precision-Scalable Posit/IEEE-754 Arithmetic in RISC-V Cores for Transprecision Computing
May 25, 2025While posit format offers superior dynamic range and accuracy for transprecision computing, its adoption in RISC-V processors is hindered by the lack of a unified solution for lightweight, precision-scalable, and IEEE-754 arithmetic compatible hardware implementation. To address these challenges, we enhance RISC-V processors by 1) integrating dedicated posit codecs into the original FPU for lightweight implementation, 2) incorporating multi/mixed-precision support with dynamic exponent size for precision-scalability, and 3) reusing and customizing ISA extensions for IEEE-754 compatible posit operations. Our comprehensive evaluation spans the modified FPU, RISC-V core, and SoC levels. It demonstrates that our implementation achieves 47.9% LUTs and 57.4% FFs reduction compared to state-of-the-art posit-enabled RISC-V processors, while achieving up to 2.54$\times$ throughput improvement in various GEMM kernels.
FlashForge: Ultra-Efficient Prefix-Aware Attention for LLM Decoding
May 23, 2025
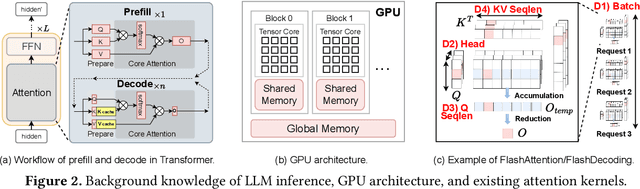
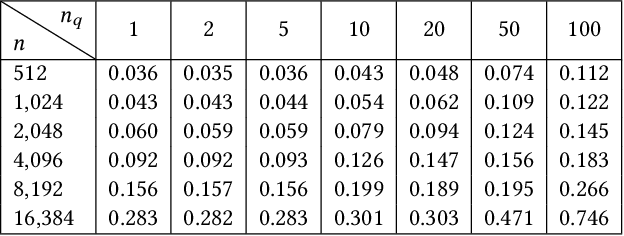

Prefix-sharing among multiple prompts presents opportunities to combine the operations of the shared prefix, while attention computation in the decode stage, which becomes a critical bottleneck with increasing context lengths, is a memory-intensive process requiring heavy memory access on the key-value (KV) cache of the prefixes. Therefore, in this paper, we explore the potential of prefix-sharing in the attention computation of the decode stage. However, the tree structure of the prefix-sharing mechanism presents significant challenges for attention computation in efficiently processing shared KV cache access patterns while managing complex dependencies and balancing irregular workloads. To address the above challenges, we propose a dedicated attention kernel to combine the memory access of shared prefixes in the decoding stage, namely FlashForge. FlashForge delivers two key innovations: a novel shared-prefix attention kernel that optimizes memory hierarchy and exploits both intra-block and inter-block parallelism, and a comprehensive workload balancing mechanism that efficiently estimates cost, divides tasks, and schedules execution. Experimental results show that FlashForge achieves an average 1.9x speedup and 120.9x memory access reduction compared to the state-of-the-art FlashDecoding kernel regarding attention computation in the decode stage and 3.8x end-to-end time per output token compared to the vLLM.
A Novel P-bit-based Probabilistic Computing Approach for Solving the 3-D Protein Folding Problem
Feb 27, 2025In the post-Moore era, the need for efficient solutions to non-deterministic polynomial-time (NP) problems is becoming more pressing. In this context, the Ising model implemented by the probabilistic computing systems with probabilistic bits (p-bits) has attracted attention due to the widespread availability of p-bits and support for large-scale simulations. This study marks the first work to apply probabilistic computing to tackle protein folding, a significant NP-complete problem challenge in biology. We represent proteins as sequences of hydrophobic (H) and polar (P) beads within a three-dimensional (3-D) grid and introduce a novel many-body interaction-based encoding method to map the problem onto an Ising model. Our simulations show that this approach significantly simplifies the energy landscape for short peptide sequences of six amino acids, halving the number of energy levels. Furthermore, the proposed mapping method achieves approximately 100 times acceleration for sequences consisting of ten amino acids in identifying the correct folding configuration. We predicted the optimal folding configuration for a peptide sequence of 36 amino acids by identifying the ground state. These findings highlight the unique potential of the proposed encoding method for solving protein folding and, importantly, provide new tools for solving similar NP-complete problems in biology by probabilistic computing approach.
Anda: Unlocking Efficient LLM Inference with a Variable-Length Grouped Activation Data Format
Nov 24, 2024The widely-used, weight-only quantized large language models (LLMs), which leverage low-bit integer (INT) weights and retain floating-point (FP) activations, reduce storage requirements while maintaining accuracy. However, this shifts the energy and latency bottlenecks towards the FP activations that are associated with costly memory accesses and computations. Existing LLM accelerators focus primarily on computation optimizations, overlooking the potential of jointly optimizing FP computations and data movement, particularly for the dominant FP-INT GeMM operations in LLM inference. To address these challenges, we investigate the sensitivity of activation precision across various LLM modules and its impact on overall model accuracy. Based on our findings, we first propose the Anda data type: an adaptive data format with group-shared exponent bits and dynamic mantissa bit allocation. Secondly, we develop an iterative post-training adaptive precision search algorithm that optimizes the bit-width for different LLM modules to balance model accuracy, energy efficiency, and inference speed. Lastly, a suite of hardware optimization techniques is proposed to maximally exploit the benefits of the Anda format. These include a bit-plane-based data organization scheme, Anda-enhanced processing units with bit-serial computation, and a runtime bit-plane Anda compressor to simultaneously optimize storage, computation, and memory footprints. Our evaluations on FPINT GeMM operations show that Anda achieves a 2.4x speedup, 4.0x area efficiency, and 3.1x energy efficiency improvement on average for popular LLMs including OPT, LLaMA, and LLaMA-2 series over the GPU-like FP-FP baseline. Anda demonstrates strong adaptability across various application scenarios, accuracy requirements, and system performance, enabling efficient LLM inference across a wide range of deployment scenarios.
Jamming Detection and Channel Estimation for Spatially Correlated Beamspace Massive MIMO
Oct 18, 2024



In this paper, we investigate the problem of jamming detection and channel estimation during multi-user uplink beam training under random pilot jamming attacks in beamspace massive multi-input-multi-output (MIMO) systems. For jamming detection, we distinguish the signals from the jammer and the user by projecting the observation signals onto the pilot space. By using the multiple projected observation vectors corresponding to the unused pilots, we propose a jamming detection scheme based on the locally most powerful test (LMPT) for systems with general channel conditions. Analytical expressions for the probability of detection and false alarms are derived using the second-order statistics and likelihood functions of the projected observation vectors. For the detected jammer along with users, we propose a two-step minimum mean square error (MMSE) channel estimation using the projected observation vectors. As a part of the channel estimation, we develop schemes to estimate the norm and the phase of the inner-product of the legitimate pilot vector and the random jamming pilot vector, which can be obtained using linear MMSE estimation and a bilinear form of the multiple projected observation vectors. From simulations under different system parameters, we observe that the proposed technique improves the detection probability by 32.22% compared to the baseline at medium channel correlation level, and the channel estimation achieves a mean square error of -15.93dB.