 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLessons and Open Questions from a Unified Study of Camera-Trap Species Recognition Over Time
Mar 20, 2026Camera traps are vital for large-scale biodiversity monitoring, yet accurate automated analysis remains challenging due to diverse deployment environments. While the computer vision community has mostly framed this challenge as cross-domain generalization, this perspective overlooks a primary challenge faced by ecological practitioners: maintaining reliable recognition at the fixed site over time, where the dynamic nature of ecosystems introduces profound temporal shifts in both background and animal distributions. To bridge this gap, we present the first unified study of camera-trap species recognition over time. We introduce a realistic benchmark comprising 546 camera traps with a streaming protocol that evaluates models over chronologically ordered intervals. Our end-user-centric study yields four key findings. (1) Biological foundation models (e.g., BioCLIP 2) underperform at numerous sites even in initial intervals, underscoring the necessity of site-specific adaptation. (2) Adaptation is challenging under realistic evaluation: when models are updated using past data and evaluated on future intervals (mirrors real deployment lifecycles), naive adaptation can even degrade below zero-shot performance. (3) We identify two drivers of this difficulty: severe class imbalance and pronounced temporal shift in both species distribution and backgrounds between consecutive intervals. (4) We find that effective integration of model-update and post-processing techniques can largely improve accuracy, though a gap from the upper bounds remains. Finally, we highlight critical open questions, such as predicting when zero-shot models will succeed at a new site and determining whether/when model updates are necessary. Our benchmark and analysis provide actionable deployment guidelines for ecological practitioners while establishing new directions for future research in vision and machine learning.
On the Feasibility and Opportunity of Autoregressive 3D Object Detection
Mar 09, 2026LiDAR-based 3D object detectors typically rely on proposal heads with hand-crafted components like anchor assignment and non-maximum suppression (NMS), complicating training and limiting extensibility. We present AutoReg3D, an autoregressive 3D detector that casts detection as sequence generation. Given point-cloud features, AutoReg3D emits objects in a range-causal (near-to-far) order and encodes each object as a short, discrete-token sequence consisting of its center, size, orientation, velocity, and class. This near-to-far ordering mirrors LiDAR geometry--near objects occlude far ones but not vice versa--enabling straightforward teacher forcing during training and autoregressive decoding at test time. AutoReg3D is compatible across diverse point-cloud or backbones and attains competitive nuScenes performance without anchors or NMS. Beyond parity, the sequential formulation unlocks language-model advances for 3D perception, including GRPO-style reinforcement learning for task-aligned objectives. These results position autoregressive decoding as a viable, flexible alternative for LiDAR-based detection and open a path to importing modern sequence-modeling tools into 3D perception.
AVA-Bench: Atomic Visual Ability Benchmark for Vision Foundation Models
Jun 10, 2025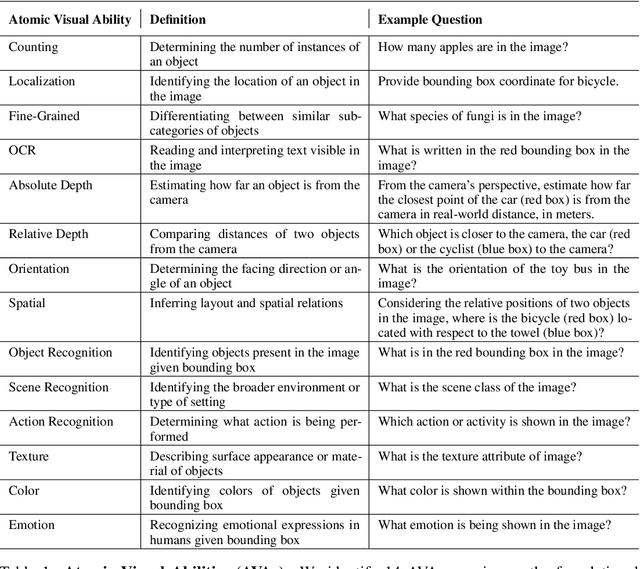
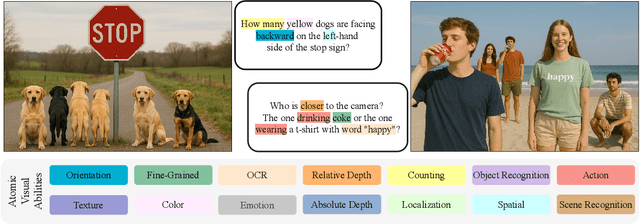
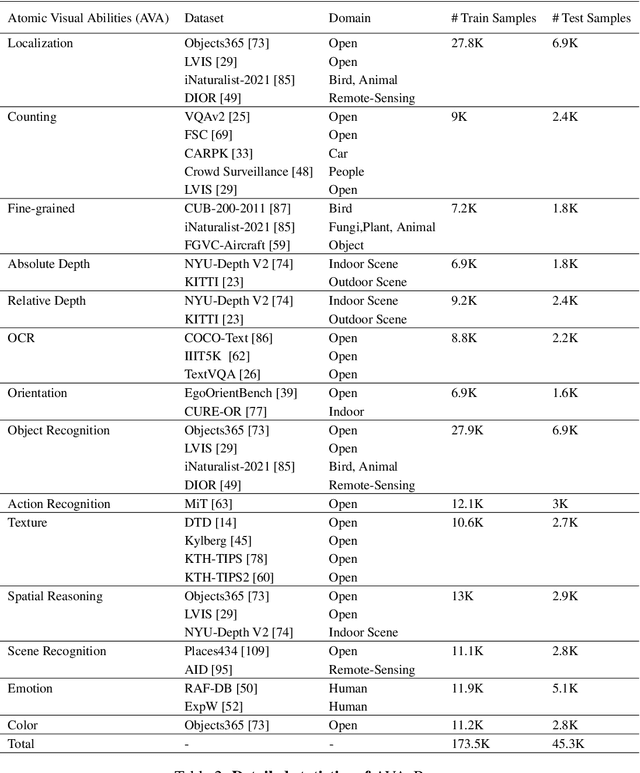

The rise of vision foundation models (VFMs) calls for systematic evaluation. A common approach pairs VFMs with large language models (LLMs) as general-purpose heads, followed by evaluation on broad Visual Question Answering (VQA) benchmarks. However, this protocol has two key blind spots: (i) the instruction tuning data may not align with VQA test distributions, meaning a wrong prediction can stem from such data mismatch rather than a VFM' visual shortcomings; (ii) VQA benchmarks often require multiple visual abilities, making it hard to tell whether errors stem from lacking all required abilities or just a single critical one. To address these gaps, we introduce AVA-Bench, the first benchmark that explicitly disentangles 14 Atomic Visual Abilities (AVAs) -- foundational skills like localization, depth estimation, and spatial understanding that collectively support complex visual reasoning tasks. By decoupling AVAs and matching training and test distributions within each, AVA-Bench pinpoints exactly where a VFM excels or falters. Applying AVA-Bench to leading VFMs thus reveals distinctive "ability fingerprints," turning VFM selection from educated guesswork into principled engineering. Notably, we find that a 0.5B LLM yields similar VFM rankings as a 7B LLM while cutting GPU hours by 8x, enabling more efficient evaluation. By offering a comprehensive and transparent benchmark, we hope AVA-Bench lays the foundation for the next generation of VFMs.
Transfer Your Perspective: Controllable 3D Generation from Any Viewpoint in a Driving Scene
Feb 10, 2025



Self-driving cars relying solely on ego-centric perception face limitations in sensing, often failing to detect occluded, faraway objects. Collaborative autonomous driving (CAV) seems like a promising direction, but collecting data for development is non-trivial. It requires placing multiple sensor-equipped agents in a real-world driving scene, simultaneously! As such, existing datasets are limited in locations and agents. We introduce a novel surrogate to the rescue, which is to generate realistic perception from different viewpoints in a driving scene, conditioned on a real-world sample - the ego-car's sensory data. This surrogate has huge potential: it could potentially turn any ego-car dataset into a collaborative driving one to scale up the development of CAV. We present the very first solution, using a combination of simulated collaborative data and real ego-car data. Our method, Transfer Your Perspective (TYP), learns a conditioned diffusion model whose output samples are not only realistic but also consistent in both semantics and layouts with the given ego-car data. Empirical results demonstrate TYP's effectiveness in aiding in a CAV setting. In particular, TYP enables us to (pre-)train collaborative perception algorithms like early and late fusion with little or no real-world collaborative data, greatly facilitating downstream CAV applications.