 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMusic Transcription with (Almost) No Supervision
May 22, 2026Competitive music transcription models require large amounts of paired audio-score data, which is scarce due to collection costs, alignment difficulty, and copyright restrictions. Meanwhile, vast quantities of unpaired audio recordings and symbolic scores are freely available but have gone unused. We adopt a cycle-consistent translation framework in which a small amount of paired data acts as a minimal anchor, unlocking the full potential of the unpaired pool. We find that: unpaired data yields surprisingly large gains, especially under limited supervision; unpaired audio contributes more than unpaired scores; incorporating unlabeled audio from a new instrument during training improves transcription for that instrument without any paired supervision. Together, these results suggest that scaling unpaired data offers a practical path toward high-quality transcription for instruments where labeled data remains scarce.
Continuous Diffusion Scales Competitively with Discrete Diffusion for Language
May 18, 2026While diffusion has drawn considerable recent attention from the language modeling community, continuous diffusion has appeared less scalable than discrete approaches. To challenge this belief we revisit Plaid, a likelihood-based continuous diffusion language model (DLM), and construct RePlaid by aligning the architecture of Plaid with modern discrete DLMs. In this unified setting, we establish the first scaling law for continuous DLMs that rivals discrete DLMs: RePlaid exhibits a compute gap of only $20\times$ compared to autoregressive models, outperforms Duo while using fewer parameters, and outperforms MDLM in the over-trained regime. We benchmark RePlaid against recent continuous DLMs: on OpenWebText, RePlaid achieves a new state-of-the-art PPL bound of $22.1$ among continuous DLMs and superior generation quality. These results suggest that continuous diffusion, when trained via likelihood, is a highly competitive and scalable alternative to discrete DLMs. Moreover, we offer theoretical insights to understand the advantage of likelihood-based training. We show that optimizing the noise schedule to minimize the ELBO's variance naturally yields linear cross-entropy (information loss) over time. This evenly distributes denoising difficulty without any case-specific time reparameterization. In addition, we find that optimizing embeddings via likelihood creates structured geometries and drives the most significant likelihood gain.
Compiled AI: Deterministic Code Generation for LLM-Based Workflow Automation
Apr 06, 2026We study compiled AI, a paradigm in which large language models generate executable code artifacts during a compilation phase, after which workflows execute deterministically without further model invocation. This paradigm has antecedents in prior work on declarative pipeline optimization (DSPy) and hybrid neural-symbolic planning (LLM+P); our contribution is a systems-oriented study of its application to high-stakes enterprise workflows, with particular emphasis on healthcare settings where reliability and auditability are critical. By constraining generation to narrow business-logic functions embedded in validated templates, compiled AI trades runtime flexibility for predictability, auditability, cost efficiency, and reduced security exposure. We introduce (i) a system architecture for constrained LLM-based code generation, (ii) a four-stage generation-and-validation pipeline that converts probabilistic model output into production-ready code artifacts, and (iii) an evaluation framework measuring operational metrics including token amortization, determinism, reliability, security, and cost. We evaluate on two task types: function-calling (BFCL, n=400) and document intelligence (DocILE, n=5,680 invoices). On function-calling, compiled AI achieves 96% task completion with zero execution tokens, breaking even with runtime inference at approximately 17 transactions and reducing token consumption by 57x at 1,000 transactions. On document intelligence, our Code Factory variant matches Direct LLM on key field extraction (KILE: 80.0%) while achieving the highest line item recognition accuracy (LIR: 80.4%). Security evaluation across 135 test cases demonstrates 96.7% accuracy on prompt injection detection and 87.5% on static code safety analysis with zero false positives.
Scaling Beyond Masked Diffusion Language Models
Feb 16, 2026Diffusion language models are a promising alternative to autoregressive models due to their potential for faster generation. Among discrete diffusion approaches, Masked diffusion currently dominates, largely driven by strong perplexity on language modeling benchmarks. In this work, we present the first scaling law study of uniform-state and interpolating discrete diffusion methods. We also show that Masked diffusion models can be made approximately 12% more FLOPs-efficient when trained with a simple cross-entropy objective. We find that perplexity is informative within a diffusion family but can be misleading across families, where models with worse likelihood scaling may be preferable due to faster and more practical sampling, as reflected by the speed-quality Pareto frontier. These results challenge the view that Masked diffusion is categorically the future of diffusion language modeling and that perplexity alone suffices for cross-algorithm comparison. Scaling all methods to 1.7B parameters, we show that uniform-state diffusion remains competitive on likelihood-based benchmarks and outperforms autoregressive and Masked diffusion models on GSM8K, despite worse validation perplexity. We provide the code, model checkpoints, and video tutorials on the project page: http://s-sahoo.github.io/scaling-dllms
Robust Neural Audio Fingerprinting using Music Foundation Models
Nov 07, 2025The proliferation of distorted, compressed, and manipulated music on modern media platforms like TikTok motivates the development of more robust audio fingerprinting techniques to identify the sources of musical recordings. In this paper, we develop and evaluate new neural audio fingerprinting techniques with the aim of improving their robustness. We make two contributions to neural fingerprinting methodology: (1) we use a pretrained music foundation model as the backbone of the neural architecture and (2) we expand the use of data augmentation to train fingerprinting models under a wide variety of audio manipulations, including time streching, pitch modulation, compression, and filtering. We systematically evaluate our methods in comparison to two state-of-the-art neural fingerprinting models: NAFP and GraFPrint. Results show that fingerprints extracted with music foundation models (e.g., MuQ, MERT) consistently outperform models trained from scratch or pretrained on non-musical audio. Segment-level evaluation further reveals their capability to accurately localize fingerprint matches, an important practical feature for catalog management.
Benchmark Datasets for Lead-Lag Forecasting on Social Platforms
Nov 05, 2025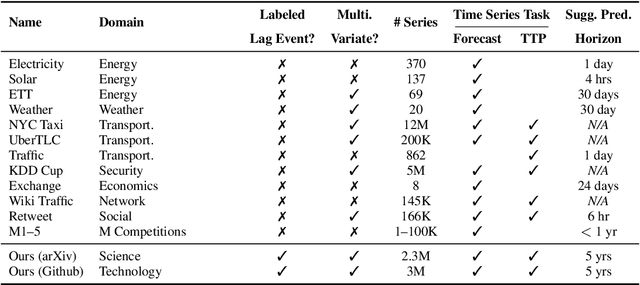


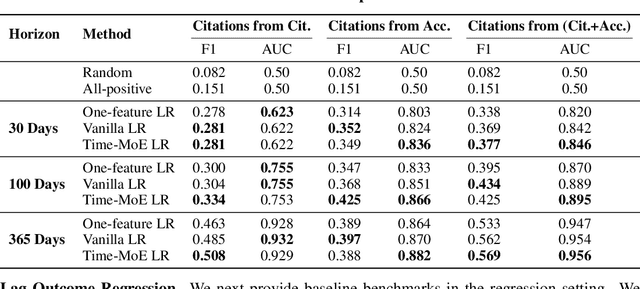
Social and collaborative platforms emit multivariate time-series traces in which early interactions-such as views, likes, or downloads-are followed, sometimes months or years later, by higher impact like citations, sales, or reviews. We formalize this setting as Lead-Lag Forecasting (LLF): given an early usage channel (the lead), predict a correlated but temporally shifted outcome channel (the lag). Despite the ubiquity of such patterns, LLF has not been treated as a unified forecasting problem within the time-series community, largely due to the absence of standardized datasets. To anchor research in LLF, here we present two high-volume benchmark datasets-arXiv (accesses -> citations of 2.3M papers) and GitHub (pushes/stars -> forks of 3M repositories)-and outline additional domains with analogous lead-lag dynamics, including Wikipedia (page views -> edits), Spotify (streams -> concert attendance), e-commerce (click-throughs -> purchases), and LinkedIn profile (views -> messages). Our datasets provide ideal testbeds for lead-lag forecasting, by capturing long-horizon dynamics across years, spanning the full spectrum of outcomes, and avoiding survivorship bias in sampling. We documented all technical details of data curation and cleaning, verified the presence of lead-lag dynamics through statistical and classification tests, and benchmarked parametric and non-parametric baselines for regression. Our study establishes LLF as a novel forecasting paradigm and lays an empirical foundation for its systematic exploration in social and usage data. Our data portal with downloads and documentation is available at https://lead-lag-forecasting.github.io/.
Aligning Text-to-Music Evaluation with Human Preferences
Mar 20, 2025Despite significant recent advances in generative acoustic text-to-music (TTM) modeling, robust evaluation of these models lags behind, relying in particular on the popular Fr\'echet Audio Distance (FAD). In this work, we rigorously study the design space of reference-based divergence metrics for evaluating TTM models through (1) designing four synthetic meta-evaluations to measure sensitivity to particular musical desiderata, and (2) collecting and evaluating on MusicPrefs, the first open-source dataset of human preferences for TTM systems. We find that not only is the standard FAD setup inconsistent on both synthetic and human preference data, but that nearly all existing metrics fail to effectively capture desiderata, and are only weakly correlated with human perception. We propose a new metric, the MAUVE Audio Divergence (MAD), computed on representations from a self-supervised audio embedding model. We find that this metric effectively captures diverse musical desiderata (average rank correlation 0.84 for MAD vs. 0.49 for FAD and also correlates more strongly with MusicPrefs (0.62 vs. 0.14).
Hookpad Aria: A Copilot for Songwriters
Feb 12, 2025

We present Hookpad Aria, a generative AI system designed to assist musicians in writing Western pop songs. Our system is seamlessly integrated into Hookpad, a web-based editor designed for the composition of lead sheets: symbolic music scores that describe melody and harmony. Hookpad Aria has numerous generation capabilities designed to assist users in non-sequential composition workflows, including: (1) generating left-to-right continuations of existing material, (2) filling in missing spans in the middle of existing material, and (3) generating harmony from melody and vice versa. Hookpad Aria is also a scalable data flywheel for music co-creation -- since its release in March 2024, Aria has generated 318k suggestions for 3k users who have accepted 74k into their songs. More information about Hookpad Aria is available at https://www.hooktheory.com/hookpad/aria
Constrained Diffusion Implicit Models
Nov 01, 2024



This paper describes an efficient algorithm for solving noisy linear inverse problems using pretrained diffusion models. Extending the paradigm of denoising diffusion implicit models (DDIM), we propose constrained diffusion implicit models (CDIM) that modify the diffusion updates to enforce a constraint upon the final output. For noiseless inverse problems, CDIM exactly satisfies the constraints; in the noisy case, we generalize CDIM to satisfy an exact constraint on the residual distribution of the noise. Experiments across a variety of tasks and metrics show strong performance of CDIM, with analogous inference acceleration to unconstrained DDIM: 10 to 50 times faster than previous conditional diffusion methods. We demonstrate the versatility of our approach on many problems including super-resolution, denoising, inpainting, deblurring, and 3D point cloud reconstruction.
Robust Distortion-free Watermarks for Language Models
Jul 28, 2023We propose a methodology for planting watermarks in text from an autoregressive language model that are robust to perturbations without changing the distribution over text up to a certain maximum generation budget. We generate watermarked text by mapping a sequence of random numbers -- which we compute using a randomized watermark key -- to a sample from the language model. To detect watermarked text, any party who knows the key can align the text to the random number sequence. We instantiate our watermark methodology with two sampling schemes: inverse transform sampling and exponential minimum sampling. We apply these watermarks to three language models -- OPT-1.3B, LLaMA-7B and Alpaca-7B -- to experimentally validate their statistical power and robustness to various paraphrasing attacks. Notably, for both the OPT-1.3B and LLaMA-7B models, we find we can reliably detect watermarked text ($p \leq 0.01$) from $35$ tokens even after corrupting between $40$-$50$\% of the tokens via random edits (i.e., substitutions, insertions or deletions). For the Alpaca-7B model, we conduct a case study on the feasibility of watermarking responses to typical user instructions. Due to the lower entropy of the responses, detection is more difficult: around $25\%$ of the responses -- whose median length is around $100$ tokens -- are detectable with $p \leq 0.01$, and the watermark is also less robust to certain automated paraphrasing attacks we implement.