 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Unified Vision-Language Models Necessary: Generalization Across Understanding and Generation
May 29, 2025Recent advancements in unified vision-language models (VLMs), which integrate both visual understanding and generation capabilities, have attracted significant attention. The underlying hypothesis is that a unified architecture with mixed training on both understanding and generation tasks can enable mutual enhancement between understanding and generation. However, this hypothesis remains underexplored in prior works on unified VLMs. To address this gap, this paper systematically investigates the generalization across understanding and generation tasks in unified VLMs. Specifically, we design a dataset closely aligned with real-world scenarios to facilitate extensive experiments and quantitative evaluations. We evaluate multiple unified VLM architectures to validate our findings. Our key findings are as follows. First, unified VLMs trained with mixed data exhibit mutual benefits in understanding and generation tasks across various architectures, and this mutual benefits can scale up with increased data. Second, better alignment between multimodal input and output spaces will lead to better generalization. Third, the knowledge acquired during generation tasks can transfer to understanding tasks, and this cross-task generalization occurs within the base language model, beyond modality adapters. Our findings underscore the critical necessity of unifying understanding and generation in VLMs, offering valuable insights for the design and optimization of unified VLMs.
Point-RFT: Improving Multimodal Reasoning with Visually Grounded Reinforcement Finetuning
May 26, 2025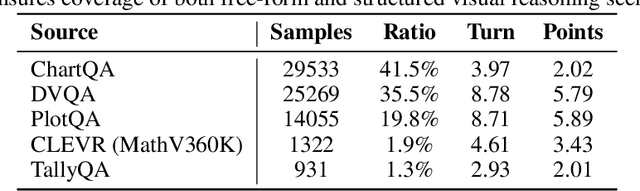
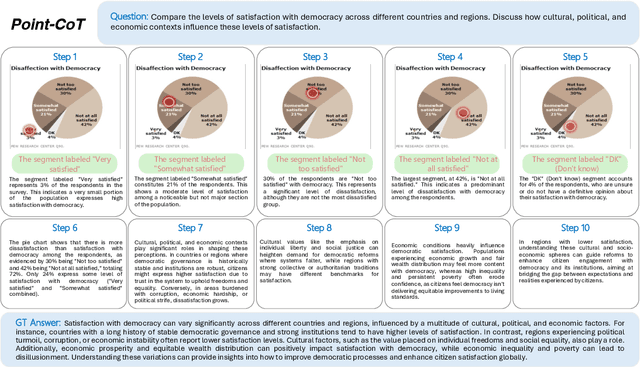

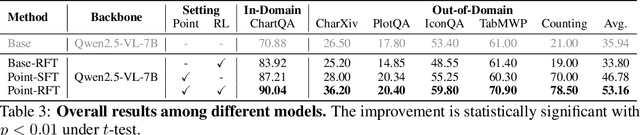
Recent advances in large language models have significantly improved textual reasoning through the effective use of Chain-of-Thought (CoT) and reinforcement learning. However, extending these successes to vision-language tasks remains challenging due to inherent limitations in text-only CoT, such as visual hallucinations and insufficient multimodal integration. In this paper, we introduce Point-RFT, a multimodal reasoning framework explicitly designed to leverage visually grounded CoT reasoning for visual document understanding. Our approach consists of two stages: First, we conduct format finetuning using a curated dataset of 71K diverse visual reasoning problems, each annotated with detailed, step-by-step rationales explicitly grounded to corresponding visual elements. Second, we employ reinforcement finetuning targeting visual document understanding. On ChartQA, our approach improves accuracy from 70.88% (format-finetuned baseline) to 90.04%, surpassing the 83.92% accuracy achieved by reinforcement finetuning relying solely on text-based CoT. The result shows that our grounded CoT is more effective for multimodal reasoning compared with the text-only CoT. Moreover, Point-RFT exhibits superior generalization capability across several out-of-domain visual document reasoning benchmarks, including CharXiv, PlotQA, IconQA, TabMWP, etc., and highlights its potential in complex real-world scenarios.
OpenThinkIMG: Learning to Think with Images via Visual Tool Reinforcement Learning
May 13, 2025



While humans can flexibly leverage interactive visual cognition for complex problem-solving, enabling Large Vision-Language Models (LVLMs) to learn similarly adaptive behaviors with visual tools remains challenging. A significant hurdle is the current lack of standardized infrastructure, which hinders integrating diverse tools, generating rich interaction data, and training robust agents effectively. To address these gaps, we introduce OpenThinkIMG, the first open-source, comprehensive end-to-end framework for tool-augmented LVLMs. It features standardized vision tool interfaces, scalable trajectory generation for policy initialization, and a flexible training environment. Furthermore, considering supervised fine-tuning (SFT) on static demonstrations offers limited policy generalization for dynamic tool invocation, we propose a novel reinforcement learning (RL) framework V-ToolRL to train LVLMs to learn adaptive policies for invoking external vision tools. V-ToolRL enables LVLMs to autonomously discover optimal tool-usage strategies by directly optimizing for task success using feedback from tool interactions. We empirically validate V-ToolRL on challenging chart reasoning tasks. Our RL-trained agent, built upon a Qwen2-VL-2B, significantly outperforms its SFT-initialized counterpart (+28.83 points) and surpasses established supervised tool-learning baselines like Taco and CogCom by an average of +12.7 points. Notably, it also surpasses prominent closed-source models like GPT-4.1 by +8.68 accuracy points. We hope OpenThinkIMG can serve as a foundational framework for advancing dynamic, tool-augmented visual reasoning, helping the community develop AI agents that can genuinely "think with images".
SITE: towards Spatial Intelligence Thorough Evaluation
May 08, 2025Spatial intelligence (SI) represents a cognitive ability encompassing the visualization, manipulation, and reasoning about spatial relationships, underpinning disciplines from neuroscience to robotics. We introduce SITE, a benchmark dataset towards SI Thorough Evaluation in a standardized format of multi-choice visual question-answering, designed to assess large vision-language models' spatial intelligence across diverse visual modalities (single-image, multi-image, and video) and SI factors (figural to environmental scales, spatial visualization and orientation, intrinsic and extrinsic, static and dynamic). Our approach to curating the benchmark combines a bottom-up survey about 31 existing datasets and a top-down strategy drawing upon three classification systems in cognitive science, which prompt us to design two novel types of tasks about view-taking and dynamic scenes. Extensive experiments reveal that leading models fall behind human experts especially in spatial orientation, a fundamental SI factor. Moreover, we demonstrate a positive correlation between a model's spatial reasoning proficiency and its performance on an embodied AI task.
RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning
Apr 24, 2025Training large language models (LLMs) as interactive agents presents unique challenges including long-horizon decision making and interacting with stochastic environment feedback. While reinforcement learning (RL) has enabled progress in static tasks, multi-turn agent RL training remains underexplored. We propose StarPO (State-Thinking-Actions-Reward Policy Optimization), a general framework for trajectory-level agent RL, and introduce RAGEN, a modular system for training and evaluating LLM agents. Our study on three stylized environments reveals three core findings. First, our agent RL training shows a recurring mode of Echo Trap where reward variance cliffs and gradient spikes; we address this with StarPO-S, a stabilized variant with trajectory filtering, critic incorporation, and decoupled clipping. Second, we find the shaping of RL rollouts would benefit from diverse initial states, medium interaction granularity and more frequent sampling. Third, we show that without fine-grained, reasoning-aware reward signals, agent reasoning hardly emerge through multi-turn RL and they may show shallow strategies or hallucinated thoughts. Code and environments are available at https://github.com/RAGEN-AI/RAGEN.
SoTA with Less: MCTS-Guided Sample Selection for Data-Efficient Visual Reasoning Self-Improvement
Apr 10, 2025



In this paper, we present an effective method to enhance visual reasoning with significantly fewer training samples, relying purely on self-improvement with no knowledge distillation. Our key insight is that the difficulty of training data during reinforcement fine-tuning (RFT) is critical. Appropriately challenging samples can substantially boost reasoning capabilities even when the dataset is small. Despite being intuitive, the main challenge remains in accurately quantifying sample difficulty to enable effective data filtering. To this end, we propose a novel way of repurposing Monte Carlo Tree Search (MCTS) to achieve that. Starting from our curated 70k open-source training samples, we introduce an MCTS-based selection method that quantifies sample difficulty based on the number of iterations required by the VLMs to solve each problem. This explicit step-by-step reasoning in MCTS enforces the model to think longer and better identifies samples that are genuinely challenging. We filter and retain 11k samples to perform RFT on Qwen2.5-VL-7B-Instruct, resulting in our final model, ThinkLite-VL. Evaluation results on eight benchmarks show that ThinkLite-VL improves the average performance of Qwen2.5-VL-7B-Instruct by 7%, using only 11k training samples with no knowledge distillation. This significantly outperforms all existing 7B-level reasoning VLMs, and our fairly comparable baselines that use classic selection methods such as accuracy-based filtering. Notably, on MathVista, ThinkLite-VL-7B achieves the SoTA accuracy of 75.1, surpassing Qwen2.5-VL-72B, GPT-4o, and O1. Our code, data, and model are available at https://github.com/si0wang/ThinkLite-VL.
V-MAGE: A Game Evaluation Framework for Assessing Visual-Centric Capabilities in Multimodal Large Language Models
Apr 08, 2025Recent advancements in Multimodal Large Language Models (MLLMs) have led to significant improvements across various multimodal benchmarks. However, as evaluations shift from static datasets to open-world, dynamic environments, current game-based benchmarks remain inadequate because they lack visual-centric tasks and fail to assess the diverse reasoning skills required for real-world decision-making. To address this, we introduce Visual-centric Multiple Abilities Game Evaluation (V-MAGE), a game-based evaluation framework designed to assess visual reasoning capabilities of MLLMs. V-MAGE features five diverse games with 30+ handcrafted levels, testing models on core visual skills such as positioning, trajectory tracking, timing, and visual memory, alongside higher-level reasoning like long-term planning and deliberation. We use V-MAGE to evaluate leading MLLMs, revealing significant challenges in their visual perception and reasoning. In all game environments, the top-performing MLLMs, as determined by Elo rating comparisons, exhibit a substantial performance gap compared to humans. Our findings highlight critical limitations, including various types of perceptual errors made by the models, and suggest potential avenues for improvement from an agent-centric perspective, such as refining agent strategies and addressing perceptual inaccuracies. Code is available at https://github.com/CSU-JPG/V-MAGE.
Measurement of LLM's Philosophies of Human Nature
Apr 03, 2025The widespread application of artificial intelligence (AI) in various tasks, along with frequent reports of conflicts or violations involving AI, has sparked societal concerns about interactions with AI systems. Based on Wrightsman's Philosophies of Human Nature Scale (PHNS), a scale empirically validated over decades to effectively assess individuals' attitudes toward human nature, we design the standardized psychological scale specifically targeting large language models (LLM), named the Machine-based Philosophies of Human Nature Scale (M-PHNS). By evaluating LLMs' attitudes toward human nature across six dimensions, we reveal that current LLMs exhibit a systemic lack of trust in humans, and there is a significant negative correlation between the model's intelligence level and its trust in humans. Furthermore, we propose a mental loop learning framework, which enables LLM to continuously optimize its value system during virtual interactions by constructing moral scenarios, thereby improving its attitude toward human nature. Experiments demonstrate that mental loop learning significantly enhances their trust in humans compared to persona or instruction prompts. This finding highlights the potential of human-based psychological assessments for LLM, which can not only diagnose cognitive biases but also provide a potential solution for ethical learning in artificial intelligence. We release the M-PHNS evaluation code and data at https://github.com/kodenii/M-PHNS.
Beyond Words: Advancing Long-Text Image Generation via Multimodal Autoregressive Models
Mar 26, 2025Recent advancements in autoregressive and diffusion models have led to strong performance in image generation with short scene text words. However, generating coherent, long-form text in images, such as paragraphs in slides or documents, remains a major challenge for current generative models. We present the first work specifically focused on long text image generation, addressing a critical gap in existing text-to-image systems that typically handle only brief phrases or single sentences. Through comprehensive analysis of state-of-the-art autoregressive generation models, we identify the image tokenizer as a critical bottleneck in text generating quality. To address this, we introduce a novel text-focused, binary tokenizer optimized for capturing detailed scene text features. Leveraging our tokenizer, we develop \ModelName, a multimodal autoregressive model that excels in generating high-quality long-text images with unprecedented fidelity. Our model offers robust controllability, enabling customization of text properties such as font style, size, color, and alignment. Extensive experiments demonstrate that \ModelName~significantly outperforms SD3.5 Large~\cite{sd3} and GPT4o~\cite{gpt4o} with DALL-E 3~\cite{dalle3} in generating long text accurately, consistently, and flexibly. Beyond its technical achievements, \ModelName~opens up exciting opportunities for innovative applications like interleaved document and PowerPoint generation, establishing a new frontier in long-text image generating.
Zero-Shot Audio-Visual Editing via Cross-Modal Delta Denoising
Mar 26, 2025



In this paper, we introduce zero-shot audio-video editing, a novel task that requires transforming original audio-visual content to align with a specified textual prompt without additional model training. To evaluate this task, we curate a benchmark dataset, AvED-Bench, designed explicitly for zero-shot audio-video editing. AvED-Bench includes 110 videos, each with a 10-second duration, spanning 11 categories from VGGSound. It offers diverse prompts and scenarios that require precise alignment between auditory and visual elements, enabling robust evaluation. We identify limitations in existing zero-shot audio and video editing methods, particularly in synchronization and coherence between modalities, which often result in inconsistent outcomes. To address these challenges, we propose AvED, a zero-shot cross-modal delta denoising framework that leverages audio-video interactions to achieve synchronized and coherent edits. AvED demonstrates superior results on both AvED-Bench and the recent OAVE dataset to validate its generalization capabilities. Results are available at https://genjib.github.io/project_page/AVED/index.html