 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVEGAS: Towards Visually Explainable and Grounded Artificial Social Intelligence
Apr 03, 2025Social Intelligence Queries (Social-IQ) serve as the primary multimodal benchmark for evaluating a model's social intelligence level. While impressive multiple-choice question(MCQ) accuracy is achieved by current solutions, increasing evidence shows that they are largely, and in some cases entirely, dependent on language modality, overlooking visual context. Additionally, the closed-set nature further prevents the exploration of whether and to what extent the reasoning path behind selection is correct. To address these limitations, we propose the Visually Explainable and Grounded Artificial Social Intelligence (VEGAS) model. As a generative multimodal model, VEGAS leverages open-ended answering to provide explainable responses, which enhances the clarity and evaluation of reasoning paths. To enable visually grounded answering, we propose a novel sampling strategy to provide the model with more relevant visual frames. We then enhance the model's interpretation of these frames through Generalist Instruction Fine-Tuning (GIFT), which aims to: i) learn multimodal-language transformations for fundamental emotional social traits, and ii) establish multimodal joint reasoning capabilities. Extensive experiments, comprising modality ablation, open-ended assessments, and supervised MCQ evaluations, consistently show that VEGAS effectively utilizes visual information in reasoning to produce correct and also credible answers. We expect this work to of fer a new perspective on Social-IQ and advance the development of human-like social AI.
A Prototype-Guided Coarse Annotations Refining Approach for Whole Slide Images
Mar 25, 2025



The fine-grained annotations in whole slide images (WSIs) show the boundaries of various pathological regions. However, generating such detailed annotation is often costly, whereas the coarse annotations are relatively simpler to produce. Existing methods for refining coarse annotations often rely on extensive training samples or clean datasets, and fail to capture both intra-slide and inter-slide latent sematic patterns, limiting their precision. In this paper, we propose a prototype-guided approach. Specifically, we introduce a local-to-global approach to construct non-redundant representative prototypes by jointly modeling intra-slide local semantics and inter-slide contextual relationships. Then a prototype-guided pseudo-labeling module is proposed for refining coarse annotations. Finally, we employ dynamic data sampling and re-finetuning strategy to train a patch classifier. Extensive experiments on three publicly available WSI datasets, covering lymph, liver, and colorectal cancers, demonstrate that our method significantly outperforms existing state-of-the-art (SOTA) methods. The code will be available.
Federated Learning with Domain Shift Eraser
Mar 17, 2025Federated learning (FL) is emerging as a promising technique for collaborative learning without local data leaving their devices. However, clients' data originating from diverse domains may degrade model performance due to domain shifts, preventing the model from learning consistent representation space. In this paper, we propose a novel FL framework, Federated Domain Shift Eraser (FDSE), to improve model performance by differently erasing each client's domain skew and enhancing their consensus. First, we formulate the model forward passing as an iterative deskewing process that extracts and then deskews features alternatively. This is efficiently achieved by decomposing each original layer in the neural network into a Domain-agnostic Feature Extractor (DFE) and a Domain-specific Skew Eraser (DSE). Then, a regularization term is applied to promise the effectiveness of feature deskewing by pulling local statistics of DSE's outputs close to the globally consistent ones. Finally, DFE modules are fairly aggregated and broadcast to all the clients to maximize their consensus, and DSE modules are personalized for each client via similarity-aware aggregation to erase their domain skew differently. Comprehensive experiments were conducted on three datasets to confirm the advantages of our method in terms of accuracy, efficiency, and generalizability.
NeighborRetr: Balancing Hub Centrality in Cross-Modal Retrieval
Mar 13, 2025Cross-modal retrieval aims to bridge the semantic gap between different modalities, such as visual and textual data, enabling accurate retrieval across them. Despite significant advancements with models like CLIP that align cross-modal representations, a persistent challenge remains: the hubness problem, where a small subset of samples (hubs) dominate as nearest neighbors, leading to biased representations and degraded retrieval accuracy. Existing methods often mitigate hubness through post-hoc normalization techniques, relying on prior data distributions that may not be practical in real-world scenarios. In this paper, we directly mitigate hubness during training and introduce NeighborRetr, a novel method that effectively balances the learning of hubs and adaptively adjusts the relations of various kinds of neighbors. Our approach not only mitigates the hubness problem but also enhances retrieval performance, achieving state-of-the-art results on multiple cross-modal retrieval benchmarks. Furthermore, NeighborRetr demonstrates robust generalization to new domains with substantial distribution shifts, highlighting its effectiveness in real-world applications. We make our code publicly available at: https://github.com/zzezze/NeighborRetr .
SimROD: A Simple Baseline for Raw Object Detection with Global and Local Enhancements
Mar 10, 2025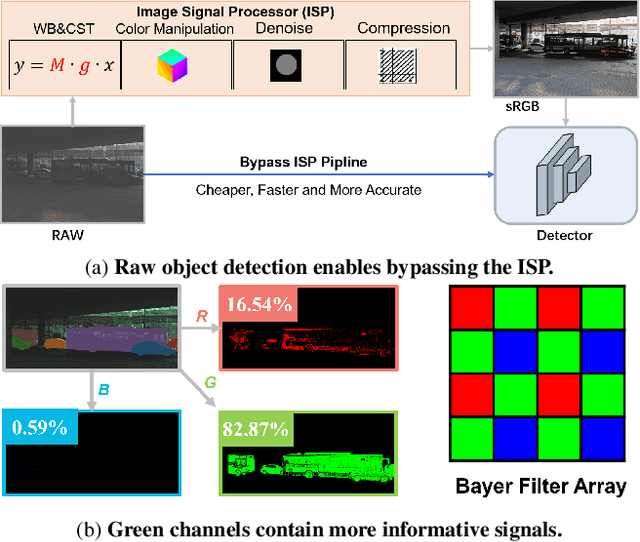
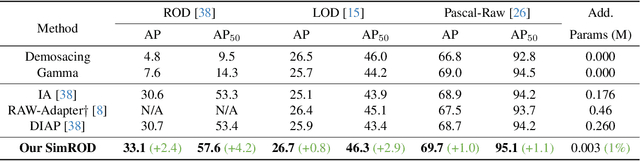
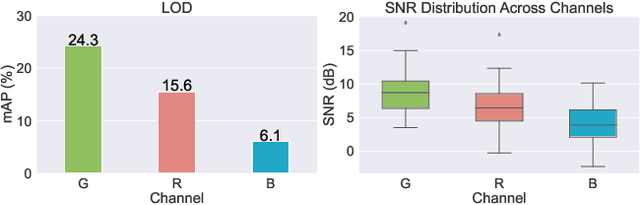
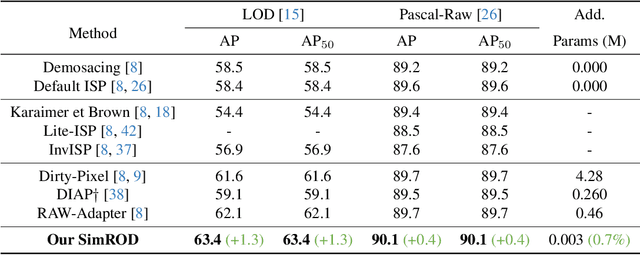
Most visual models are designed for sRGB images, yet RAW data offers significant advantages for object detection by preserving sensor information before ISP processing. This enables improved detection accuracy and more efficient hardware designs by bypassing the ISP. However, RAW object detection is challenging due to limited training data, unbalanced pixel distributions, and sensor noise. To address this, we propose SimROD, a lightweight and effective approach for RAW object detection. We introduce a Global Gamma Enhancement (GGE) module, which applies a learnable global gamma transformation with only four parameters, improving feature representation while keeping the model efficient. Additionally, we leverage the green channel's richer signal to enhance local details, aligning with the human eye's sensitivity and Bayer filter design. Extensive experiments on multiple RAW object detection datasets and detectors demonstrate that SimROD outperforms state-of-the-art methods like RAW-Adapter and DIAP while maintaining efficiency. Our work highlights the potential of RAW data for real-world object detection.
A Generalist Cross-Domain Molecular Learning Framework for Structure-Based Drug Discovery
Mar 06, 2025Structure-based drug discovery (SBDD) is a systematic scientific process that develops new drugs by leveraging the detailed physical structure of the target protein. Recent advancements in pre-trained models for biomolecules have demonstrated remarkable success across various biochemical applications, including drug discovery and protein engineering. However, in most approaches, the pre-trained models primarily focus on the characteristics of either small molecules or proteins, without delving into their binding interactions which are essential cross-domain relationships pivotal to SBDD. To fill this gap, we propose a general-purpose foundation model named BIT (an abbreviation for Biomolecular Interaction Transformer), which is capable of encoding a range of biochemical entities, including small molecules, proteins, and protein-ligand complexes, as well as various data formats, encompassing both 2D and 3D structures. Specifically, we introduce Mixture-of-Domain-Experts (MoDE) to handle the biomolecules from diverse biochemical domains and Mixture-of-Structure-Experts (MoSE) to capture positional dependencies in the molecular structures. The proposed mixture-of-experts approach enables BIT to achieve both deep fusion and domain-specific encoding, effectively capturing fine-grained molecular interactions within protein-ligand complexes. Then, we perform cross-domain pre-training on the shared Transformer backbone via several unified self-supervised denoising tasks. Experimental results on various benchmarks demonstrate that BIT achieves exceptional performance in downstream tasks, including binding affinity prediction, structure-based virtual screening, and molecular property prediction.
Can Large Language Models Unveil the Mysteries? An Exploration of Their Ability to Unlock Information in Complex Scenarios
Feb 27, 2025Combining multiple perceptual inputs and performing combinatorial reasoning in complex scenarios is a sophisticated cognitive function in humans. With advancements in multi-modal large language models, recent benchmarks tend to evaluate visual understanding across multiple images. However, they often overlook the necessity of combinatorial reasoning across multiple perceptual information. To explore the ability of advanced models to integrate multiple perceptual inputs for combinatorial reasoning in complex scenarios, we introduce two benchmarks: Clue-Visual Question Answering (CVQA), with three task types to assess visual comprehension and synthesis, and Clue of Password-Visual Question Answering (CPVQA), with two task types focused on accurate interpretation and application of visual data. For our benchmarks, we present three plug-and-play approaches: utilizing model input for reasoning, enhancing reasoning through minimum margin decoding with randomness generation, and retrieving semantically relevant visual information for effective data integration. The combined results reveal current models' poor performance on combinatorial reasoning benchmarks, even the state-of-the-art (SOTA) closed-source model achieves only 33.04% accuracy on CVQA, and drops to 7.38% on CPVQA. Notably, our approach improves the performance of models on combinatorial reasoning, with a 22.17% boost on CVQA and 9.40% on CPVQA over the SOTA closed-source model, demonstrating its effectiveness in enhancing combinatorial reasoning with multiple perceptual inputs in complex scenarios. The code will be publicly available.
Less is More: Improving LLM Alignment via Preference Data Selection
Feb 22, 2025Direct Preference Optimization (DPO) has emerged as a promising approach for aligning large language models with human preferences. While prior work mainly extends DPO from the aspect of the objective function, we instead improve DPO from the largely overlooked but critical aspect of data selection. Specifically, we address the issue of parameter shrinkage caused by noisy data by proposing a novel margin-maximization principle for dataset curation in DPO training. To accurately estimate margins for data selection, we propose a dual-margin guided approach that considers both external reward margins and implicit DPO reward margins. Extensive experiments demonstrate that our method reduces computational cost dramatically while improving performance. Remarkably, by using just 10\% of the Ultrafeedback dataset, our approach achieves 3\% to 8\% improvements across various Llama and Mistral series models on the AlpacaEval 2.0 benchmark. Furthermore, our approach seamlessly extends to iterative DPO, yielding a roughly 3\% improvement with 25\% online data, while further reducing training time. These results highlight the potential of data selection strategies for advancing preference optimization.
PSCon: Toward Conversational Product Search
Feb 19, 2025



Conversational Product Search (CPS) is confined to simulated conversations due to the lack of real-world CPS datasets that reflect human-like language. Additionally, current conversational datasets are limited to support cross-market and multi-lingual usage. In this paper, we introduce a new CPS data collection protocol and present PSCon, a novel CPS dataset designed to assist product search via human-like conversations. The dataset is constructed using a coached human-to-human data collection protocol and supports two languages and dual markets. Also, the dataset enables thorough exploration of six subtasks of CPS: user intent detection, keyword extraction, system action prediction, question selection, item ranking, and response generation. Furthermore, we also offer an analysis of the dataset and propose a benchmark model on the proposed CPS dataset.
Leader and Follower: Interactive Motion Generation under Trajectory Constraints
Feb 17, 2025



With the rapid advancement of game and film production, generating interactive motion from texts has garnered significant attention due to its potential to revolutionize content creation processes. In many practical applications, there is a need to impose strict constraints on the motion range or trajectory of virtual characters. However, existing methods that rely solely on textual input face substantial challenges in accurately capturing the user's intent, particularly in specifying the desired trajectory. As a result, the generated motions often lack plausibility and accuracy. Moreover, existing trajectory - based methods for customized motion generation rely on retraining for single - actor scenarios, which limits flexibility and adaptability to different datasets, as well as interactivity in two-actor motions. To generate interactive motion following specified trajectories, this paper decouples complex motion into a Leader - Follower dynamic, inspired by role allocation in partner dancing. Based on this framework, this paper explores the motion range refinement process in interactive motion generation and proposes a training-free approach, integrating a Pace Controller and a Kinematic Synchronization Adapter. The framework enhances the ability of existing models to generate motion that adheres to trajectory by controlling the leader's movement and correcting the follower's motion to align with the leader. Experimental results show that the proposed approach, by better leveraging trajectory information, outperforms existing methods in both realism and accuracy.