 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Prototype-Guided Coarse Annotations Refining Approach for Whole Slide Images
Mar 25, 2025



The fine-grained annotations in whole slide images (WSIs) show the boundaries of various pathological regions. However, generating such detailed annotation is often costly, whereas the coarse annotations are relatively simpler to produce. Existing methods for refining coarse annotations often rely on extensive training samples or clean datasets, and fail to capture both intra-slide and inter-slide latent sematic patterns, limiting their precision. In this paper, we propose a prototype-guided approach. Specifically, we introduce a local-to-global approach to construct non-redundant representative prototypes by jointly modeling intra-slide local semantics and inter-slide contextual relationships. Then a prototype-guided pseudo-labeling module is proposed for refining coarse annotations. Finally, we employ dynamic data sampling and re-finetuning strategy to train a patch classifier. Extensive experiments on three publicly available WSI datasets, covering lymph, liver, and colorectal cancers, demonstrate that our method significantly outperforms existing state-of-the-art (SOTA) methods. The code will be available.
Trinity: A Modular Humanoid Robot AI System
Mar 11, 2025In recent years, research on humanoid robots has garnered increasing attention. With breakthroughs in various types of artificial intelligence algorithms, embodied intelligence, exemplified by humanoid robots, has been highly anticipated. The advancements in reinforcement learning (RL) algorithms have significantly improved the motion control and generalization capabilities of humanoid robots. Simultaneously, the groundbreaking progress in large language models (LLM) and visual language models (VLM) has brought more possibilities and imagination to humanoid robots. LLM enables humanoid robots to understand complex tasks from language instructions and perform long-term task planning, while VLM greatly enhances the robots' understanding and interaction with their environment. This paper introduces \textcolor{magenta}{Trinity}, a novel AI system for humanoid robots that integrates RL, LLM, and VLM. By combining these technologies, Trinity enables efficient control of humanoid robots in complex environments. This innovative approach not only enhances the capabilities but also opens new avenues for future research and applications of humanoid robotics.
IGroupSS-Mamba: Interval Group Spatial-Spectral Mamba for Hyperspectral Image Classification
Oct 07, 2024



Hyperspectral image (HSI) classification has garnered substantial attention in remote sensing fields. Recent Mamba architectures built upon the Selective State Space Models (S6) have demonstrated enormous potential in long-range sequence modeling. However, the high dimensionality of hyperspectral data and information redundancy pose challenges to the application of Mamba in HSI classification, suffering from suboptimal performance and computational efficiency. In light of this, this paper investigates a lightweight Interval Group Spatial-Spectral Mamba framework (IGroupSS-Mamba) for HSI classification, which allows for multi-directional and multi-scale global spatial-spectral information extraction in a grouping and hierarchical manner. Technically, an Interval Group S6 Mechanism (IGSM) is developed as the core component, which partitions high-dimensional features into multiple non-overlapping groups at intervals, and then integrates a unidirectional S6 for each group with a specific scanning direction to achieve non-redundant sequence modeling. Compared to conventional applying multi-directional scanning to all bands, this grouping strategy leverages the complementary strengths of different scanning directions while decreasing computational costs. To adequately capture the spatial-spectral contextual information, an Interval Group Spatial-Spectral Block (IGSSB) is introduced, in which two IGSM-based spatial and spectral operators are cascaded to characterize the global spatial-spectral relationship along the spatial and spectral dimensions, respectively. IGroupSS-Mamba is constructed as a hierarchical structure stacked by multiple IGSSB blocks, integrating a pixel aggregation-based downsampling strategy for multiscale spatial-spectral semantic learning from shallow to deep stages. Extensive experiments demonstrate that IGroupSS-Mamba outperforms the state-of-the-art methods.
3DSS-Mamba: 3D-Spectral-Spatial Mamba for Hyperspectral Image Classification
May 21, 2024



Hyperspectral image (HSI) classification constitutes the fundamental research in remote sensing fields. Convolutional Neural Networks (CNNs) and Transformers have demonstrated impressive capability in capturing spectral-spatial contextual dependencies. However, these architectures suffer from limited receptive fields and quadratic computational complexity, respectively. Fortunately, recent Mamba architectures built upon the State Space Model integrate the advantages of long-range sequence modeling and linear computational efficiency, exhibiting substantial potential in low-dimensional scenarios. Motivated by this, we propose a novel 3D-Spectral-Spatial Mamba (3DSS-Mamba) framework for HSI classification, allowing for global spectral-spatial relationship modeling with greater computational efficiency. Technically, a spectral-spatial token generation (SSTG) module is designed to convert the HSI cube into a set of 3D spectral-spatial tokens. To overcome the limitations of traditional Mamba, which is confined to modeling causal sequences and inadaptable to high-dimensional scenarios, a 3D-Spectral-Spatial Selective Scanning (3DSS) mechanism is introduced, which performs pixel-wise selective scanning on 3D hyperspectral tokens along the spectral and spatial dimensions. Five scanning routes are constructed to investigate the impact of dimension prioritization. The 3DSS scanning mechanism combined with conventional mapping operations forms the 3D-spectral-spatial mamba block (3DMB), enabling the extraction of global spectral-spatial semantic representations. Experimental results and analysis demonstrate that the proposed method outperforms the state-of-the-art methods on HSI classification benchmarks.
Deep Explainable Learning with Graph Based Data Assessing and Rule Reasoning
Nov 10, 2022



Learning an explainable classifier often results in low accuracy model or ends up with a huge rule set, while learning a deep model is usually more capable of handling noisy data at scale, but with the cost of hard to explain the result and weak at generalization. To mitigate this gap, we propose an end-to-end deep explainable learning approach that combines the advantage of deep model in noise handling and expert rule-based interpretability. Specifically, we propose to learn a deep data assessing model which models the data as a graph to represent the correlations among different observations, whose output will be used to extract key data features. The key features are then fed into a rule network constructed following predefined noisy expert rules with trainable parameters. As these models are correlated, we propose an end-to-end training framework, utilizing the rule classification loss to optimize the rule learning model and data assessing model at the same time. As the rule-based computation is none-differentiable, we propose a gradient linking search module to carry the gradient information from the rule learning model to the data assessing model. The proposed method is tested in an industry production system, showing comparable prediction accuracy, much higher generalization stability and better interpretability when compared with a decent deep ensemble baseline, and shows much better fitting power than pure rule-based approach.
Magnetoelectric Bio-Implants Powered and Programmed by a Single Transmitter for Coordinated Multisite Stimulation
Dec 31, 2021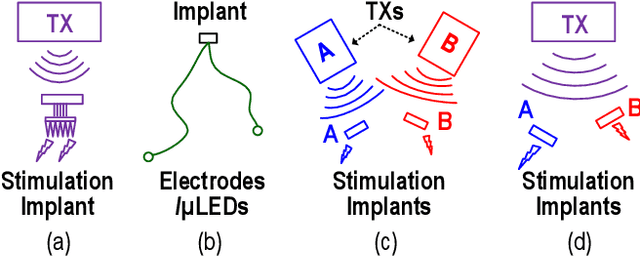
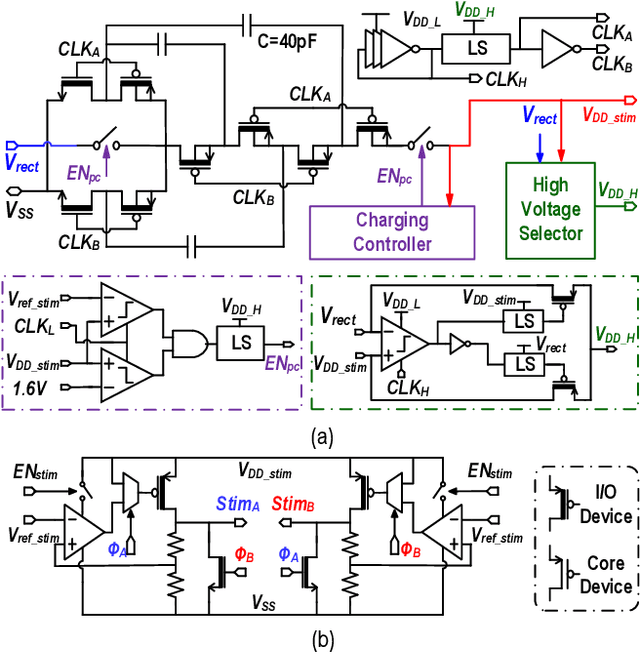
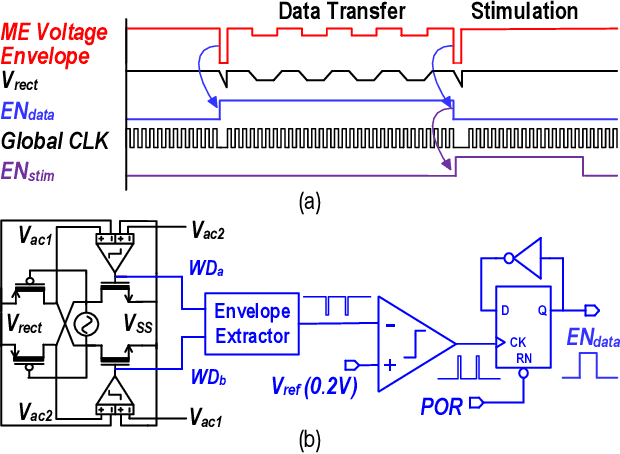
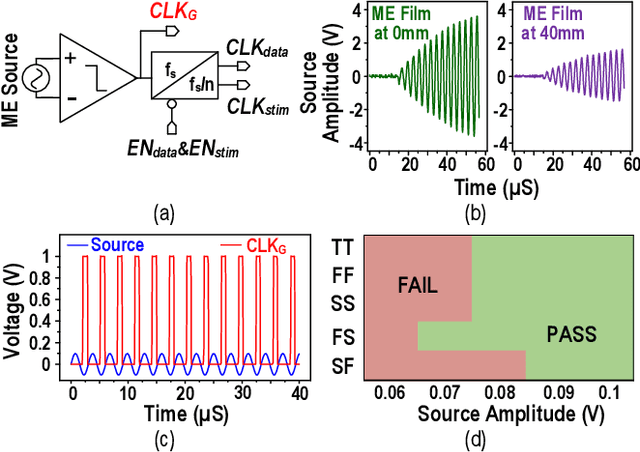
This article presents a hardware platform including stimulating implants wirelessly powered and controlled by a shared transmitter (TX) for coordinated leadless multisite stimulation. The adopted novel single-TX, multiple-implant structure can flexibly deploy stimuli, improve system efficiency, easily scale stimulating channel quantity, and relieve efforts in device synchronization. In the proposed system, a wireless link leveraging magnetoelectric (ME) effect is co-designed with a robust and efficient system-on-chip (SoC) to enable reliable operation and individual programming of every implant. Each implant integrates a 0.8-mm2 chip, a 6-mm2 ME film, and an energy storage capacitor within a 6.2-mm3 size. ME power transfer is capable of safely transmitting milliwatt power to devices placed several centimeters away from the TX coil, maintaining good efficiency with size constraints, and tolerating 60 degree, 1.5-cm misalignment in angular and lateral movement. The SoC robustly operates with 2-V source amplitude variations that spans a 40-mm TX-implant distance change, realizes individual addressability through physical unclonable function (PUF) IDs, and achieves 90% efficiency for 1.5-3.5-V stimulation with fully programmable stimulation parameters.
* This paper has been published in IEEE Journal of Solid-State Circuits, 2021
MagNI: A Magnetoelectrically Powered and Controlled Wireless Neurostimulating Implant
Jul 07, 2021
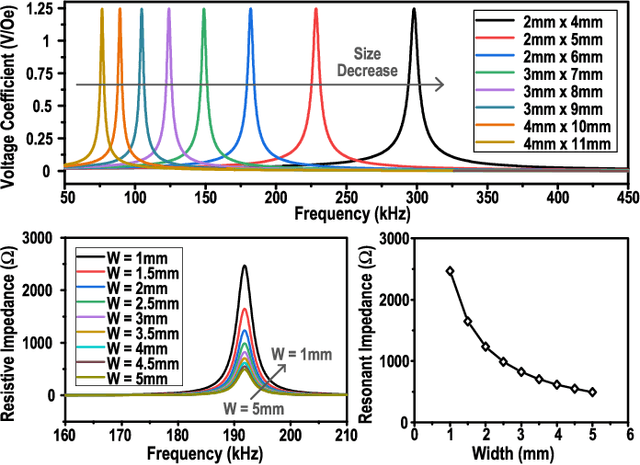
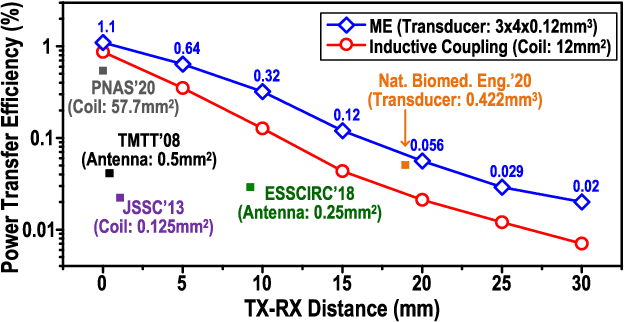
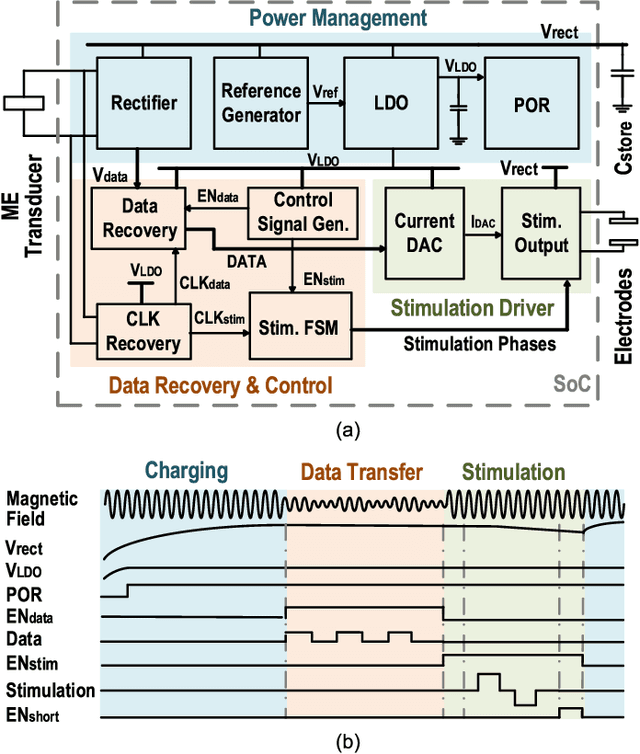
This paper presents the first wireless and programmable neural stimulator leveraging magnetoelectric (ME) effects for power and data transfer. Thanks to low tissue absorption, low misalignment sensitivity and high power transfer efficiency, the ME effect enables safe delivery of high power levels (a few milliwatts) at low resonant frequencies (~250 kHz) to mm-sized implants deep inside the body (30-mm depth). The presented MagNI (Magnetoelectric Neural Implant) consists of a 1.5-mm$^2$ 180-nm CMOS chip, an in-house built 4x2 mm ME film, an energy storage capacitor, and on-board electrodes on a flexible polyimide substrate with a total volume of 8.2 mm$^3$ . The chip with a power consumption of 23.7 $\mu$W includes robust system control and data recovery mechanisms under source amplitude variations (1-V variation tolerance). The system delivers fully-programmable bi-phasic current-controlled stimulation with patterns covering 0.05-to-1.5-mA amplitude, 64-to-512-$\mu$s pulse width, and 0-to-200Hz repetition frequency for neurostimulation.
* This work has been accepted to 2020 IEEE Transactions on Biomedical Circuits and Systems (TBioCAS)
CAP-RAM: A Charge-Domain In-Memory Computing 6T-SRAM for Accurate and Precision-Programmable CNN Inference
Jul 06, 2021

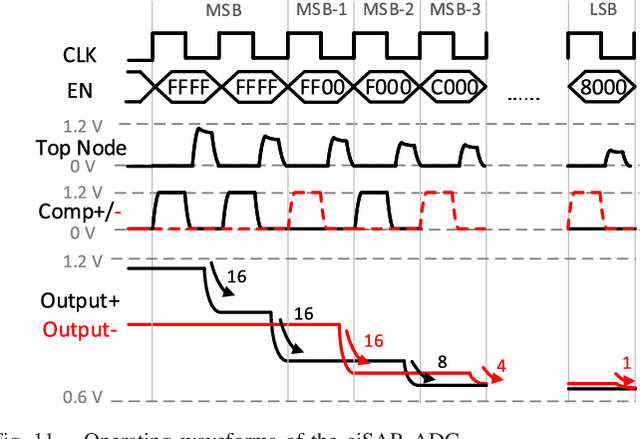
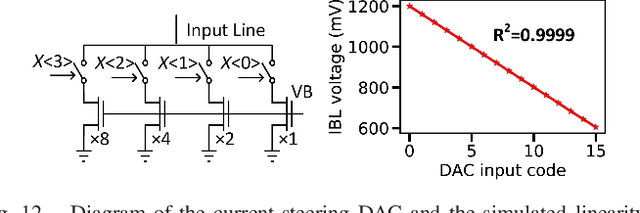
A compact, accurate, and bitwidth-programmable in-memory computing (IMC) static random-access memory (SRAM) macro, named CAP-RAM, is presented for energy-efficient convolutional neural network (CNN) inference. It leverages a novel charge-domain multiply-and-accumulate (MAC) mechanism and circuitry to achieve superior linearity under process variations compared to conventional IMC designs. The adopted semi-parallel architecture efficiently stores filters from multiple CNN layers by sharing eight standard 6T SRAM cells with one charge-domain MAC circuit. Moreover, up to six levels of bit-width of weights with two encoding schemes and eight levels of input activations are supported. A 7-bit charge-injection SAR (ciSAR) analog-to-digital converter (ADC) getting rid of sample and hold (S&H) and input/reference buffers further improves the overall energy efficiency and throughput. A 65-nm prototype validates the excellent linearity and computing accuracy of CAP-RAM. A single 512x128 macro stores a complete pruned and quantized CNN model to achieve 98.8% inference accuracy on the MNIST data set and 89.0% on the CIFAR-10 data set, with a 573.4-giga operations per second (GOPS) peak throughput and a 49.4-tera operations per second (TOPS)/W energy efficiency.
* This work has been accepted by IEEE Journal of Solid-State Circuits (JSSC 2021)
Towards Class-incremental Object Detection with Nearest Mean of Exemplars
Aug 19, 2020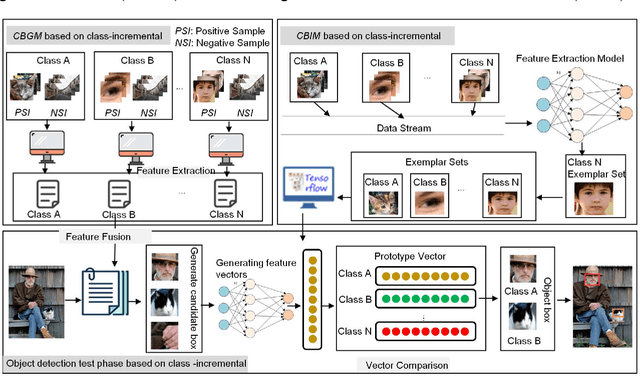
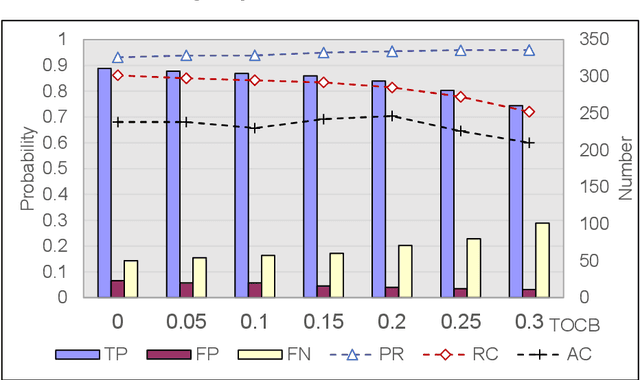
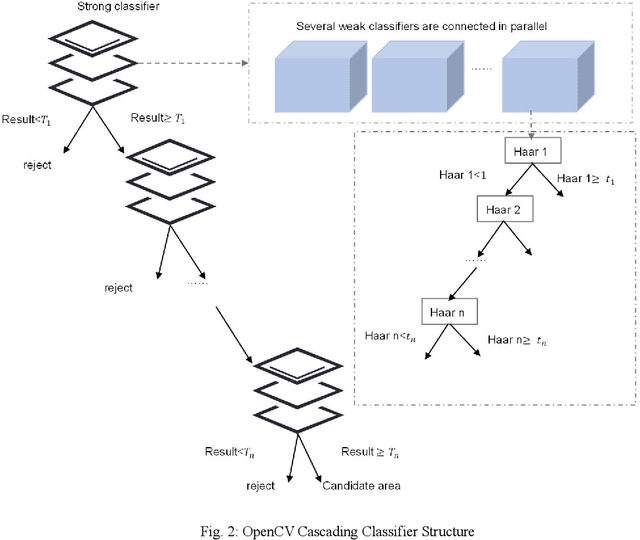
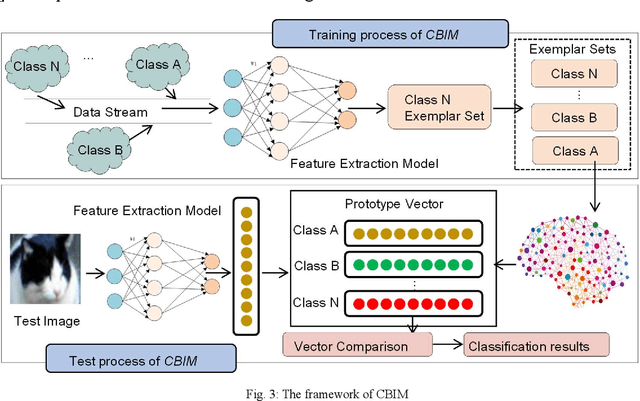
Object detection has been widely used in the field of Internet, and deep learning plays a very important role in object detection. However, the existing object detection methods need to be trained in the static setting, which requires obtaining all the data at one time, and it does not support training in the way of class-incremental. In this paper, an object detection framework named class-incremental object detection (CIOD) is proposed. CIOD divides object detection into two stages. Firstly, the traditional OpenCV cascade classifier is improved in the object candidate box generation stage to meet the needs of class increment. Secondly, we use the concept of prototype vector on the basis of deep learning to train a classifier based on class-incremental to identify the generated object candidate box, so as to extract the real object box. A large number of experiments on CIOD have been carried out to verify that CIOD can detect the object in the way of class-incremental and can control the training time and memory capacity.
Multi-Channel Deep Networks for Block-Based Image Compressive Sensing
Aug 28, 2019
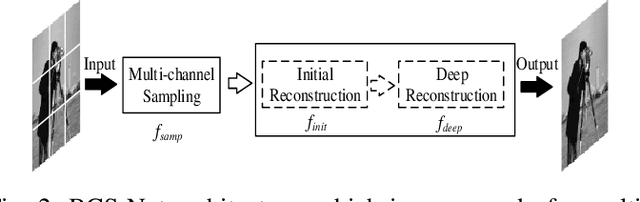
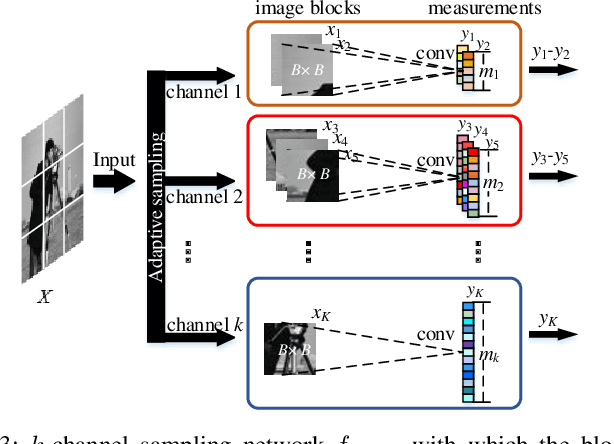
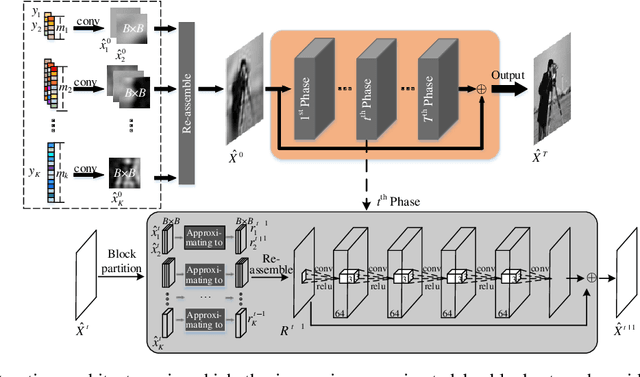
Incorporating deep neural networks in image compressive sensing (CS) receives intensive attentions recently. As deep network approaches learn the inverse mapping directly from the CS measurements, a number of models have to be trained, each of which corresponds to a sampling rate. This may potentially degrade the performance of image CS, especially when multiple sampling rates are assigned to different blocks within an image. In this paper, we develop a multi-channel deep network for block-based image CS with performance significantly exceeding the current state-of-the-art methods. The significant performance improvement of the model is attributed to block-based sampling rates allocation and model-level removal of blocking artifacts. Specifically, the image blocks with a variety of sampling rates can be reconstructed in a single model by exploiting inter-block correlation. At the same time, the initially reconstructed blocks are reassembled into a full image to remove blocking artifacts within the network by unrolling a hand-designed block-based CS algorithm. Experimental results demonstrate that the proposed method outperforms the state-of-the-art CS methods by a large margin in terms of objective metrics, PSNR, SSIM, and subjective visual quality.