 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecognize Your Orchestrator: An Entropy Dynamics Perspective for LLM Multi-Agent Systems
May 31, 2026The transition from single-turn models to Multi-Agent Systems (MAS) promises enhanced problem-solving capabilities, yet the centralized orchestration topology remains a critical point of fragility. To analyze this, we propose a Mean-Field Entropy Dynamics framework, modeling the orchestration process as a system governed by the competing forces of task resolution and cumulative context loading. To facilitate validation, we introduce Inverse Workflow Generation (IWG), a multi-agent pipeline that synthesizes process-verifiable, high-complexity benchmarks with dense intermediate checkpoints. We demonstrate that our entropy dynamics model fits empirical trajectories, providing physically interpretable parameters that quantify system stability and performance collapse. Crucially, our analysis uncovers a ``Reasoning Trap": while reasoning-heavy models excel in isolated tasks, they frequently fail as orchestrators due to context squeezing. Elucidating the physical mechanisms underlying the Orchestrator and quantifying systemic uncertainty offers insights for the MASs' architectural design.
Causal Evidence for Attention Head Imbalance in Modality Conflict Hallucination
May 19, 2026Modality-conflict hallucination occurs when multimodal large language models (MLLMs) prioritize erroneous textual premises over contradictory visual evidence. To understand why visual evidence fails to prevail during generation, we take a mechanistic perspective and examine which internal components drive or resist this failure. We perform head-level causal analysis using path patching across five open-source MLLMs and identify two groups of attention heads with opposing causal roles: hallucination-driving heads and hallucination-resisting heads. We find a consistent asymmetry: driving effects are more broadly distributed and carry greater aggregate weight, whereas resisting effects concentrate in a small number of high-importance heads. Ablation experiments further confirm that these groups exert opposing effects during generation: distributed driving influence and localized resistance together form an imbalanced routing structure that biases generation toward the erroneous premise. Motivated by this finding, we propose MACI (Modality-conflict-Aware Causal Intervention), a conditional intervention that suppresses causally identified hallucination-driving heads only when conflict is detected. Across five MLLMs, MACI achieves the largest hallucination reduction among compared inference-time baselines on the MMMC benchmark with a favorable hallucination-accuracy trade-off, and transfers zero-shot to the SCI-SemanticConflict test.
Optimizing RAG Rerankers with LLM Feedback via Reinforcement Learning
Apr 02, 2026Rerankers play a pivotal role in refining retrieval results for Retrieval-Augmented Generation. However, current reranking models are typically optimized on static human annotated relevance labels in isolation, decoupled from the downstream generation process. This isolation leads to a fundamental misalignment: documents identified as topically relevant by information retrieval metrics often fail to provide the actual utility required by the LLM for precise answer generation. To bridge this gap, we introduce ReRanking Preference Optimization (RRPO), a reinforcement learning framework that directly aligns reranking with the LLM's generation quality. By formulating reranking as a sequential decision-making process, RRPO optimizes for context utility using LLM feedback, thereby eliminating the need for expensive human annotations. To ensure training stability, we further introduce a reference-anchored deterministic baseline. Extensive experiments on knowledge-intensive benchmarks demonstrate that RRPO significantly outperforms strong baselines, including the powerful list-wise reranker RankZephyr. Further analysis highlights the versatility of our framework: it generalizes seamlessly to diverse readers (e.g., GPT-4o), integrates orthogonally with query expansion modules like Query2Doc, and remains robust even when trained with noisy supervisors.
WebNavigator: Global Web Navigation via Interaction Graph Retrieval
Mar 20, 2026Despite significant advances in autonomous web navigation, current methods remain far from human-level performance in complex web environments. We argue that this limitation stems from Topological Blindness, where agents are forced to explore via trial-and-error without access to the global topological structure of the environment. To overcome this limitation, we introduce WebNavigator, which reframes web navigation from probabilistic exploration into deterministic retrieval and pathfinding. WebNavigator constructs Interaction Graphs via zero-token cost heuristic exploration offline and implements a Retrieve-Reason-Teleport workflow for global navigation online. WebNavigator achieves state-of-the-art performance on WebArena and OnlineMind2Web. On WebArena multi-site tasks, WebNavigator achieves a 72.9\% success rate, more than doubling the performance of enterprise-level agents. This work reveals that Topological Blindness, rather than model reasoning capabilities alone, is an underestimated bottleneck in autonomous web navigation.
From Refusal Tokens to Refusal Control: Discovering and Steering Category-Specific Refusal Directions
Mar 09, 2026Language models are commonly fine-tuned for safety alignment to refuse harmful prompts. One approach fine-tunes them to generate categorical refusal tokens that distinguish different refusal types before responding. In this work, we leverage a version of Llama 3 8B fine-tuned with these categorical refusal tokens to enable inference-time control over fine-grained refusal behavior, improving both safety and reliability. We show that refusal token fine-tuning induces separable, category-aligned directions in the residual stream, which we extract and use to construct categorical steering vectors with a lightweight probe that determines whether to steer toward or away from refusal during inference. In addition, we introduce a learned low-rank combination that mixes these category directions in a whitened, orthonormal steering basis, resulting in a single controllable intervention under activation-space anisotropy, and show that this intervention is transferable across same-architecture model variants without additional training. Across benchmarks, both categorical steering vectors and the low-rank combination consistently reduce over-refusals on benign prompts while increasing refusal rates on harmful prompts, highlighting their utility for multi-category refusal control.
Perceptive Humanoid Parkour: Chaining Dynamic Human Skills via Motion Matching
Feb 17, 2026While recent advances in humanoid locomotion have achieved stable walking on varied terrains, capturing the agility and adaptivity of highly dynamic human motions remains an open challenge. In particular, agile parkour in complex environments demands not only low-level robustness, but also human-like motion expressiveness, long-horizon skill composition, and perception-driven decision-making. In this paper, we present Perceptive Humanoid Parkour (PHP), a modular framework that enables humanoid robots to autonomously perform long-horizon, vision-based parkour across challenging obstacle courses. Our approach first leverages motion matching, formulated as nearest-neighbor search in a feature space, to compose retargeted atomic human skills into long-horizon kinematic trajectories. This framework enables the flexible composition and smooth transition of complex skill chains while preserving the elegance and fluidity of dynamic human motions. Next, we train motion-tracking reinforcement learning (RL) expert policies for these composed motions, and distill them into a single depth-based, multi-skill student policy, using a combination of DAgger and RL. Crucially, the combination of perception and skill composition enables autonomous, context-aware decision-making: using only onboard depth sensing and a discrete 2D velocity command, the robot selects and executes whether to step over, climb onto, vault or roll off obstacles of varying geometries and heights. We validate our framework with extensive real-world experiments on a Unitree G1 humanoid robot, demonstrating highly dynamic parkour skills such as climbing tall obstacles up to 1.25m (96% robot height), as well as long-horizon multi-obstacle traversal with closed-loop adaptation to real-time obstacle perturbations.
Locomotion Beyond Feet
Jan 07, 2026Most locomotion methods for humanoid robots focus on leg-based gaits, yet natural bipeds frequently rely on hands, knees, and elbows to establish additional contacts for stability and support in complex environments. This paper introduces Locomotion Beyond Feet, a comprehensive system for whole-body humanoid locomotion across extremely challenging terrains, including low-clearance spaces under chairs, knee-high walls, knee-high platforms, and steep ascending and descending stairs. Our approach addresses two key challenges: contact-rich motion planning and generalization across diverse terrains. To this end, we combine physics-grounded keyframe animation with reinforcement learning. Keyframes encode human knowledge of motor skills, are embodiment-specific, and can be readily validated in simulation or on hardware, while reinforcement learning transforms these references into robust, physically accurate motions. We further employ a hierarchical framework consisting of terrain-specific motion-tracking policies, failure recovery mechanisms, and a vision-based skill planner. Real-world experiments demonstrate that Locomotion Beyond Feet achieves robust whole-body locomotion and generalizes across obstacle sizes, obstacle instances, and terrain sequences.
Persona-Aware Alignment Framework for Personalized Dialogue Generation
Nov 13, 2025Personalized dialogue generation aims to leverage persona profiles and dialogue history to generate persona-relevant and consistent responses. Mainstream models typically rely on token-level language model training with persona dialogue data, such as Next Token Prediction, to implicitly achieve personalization, making these methods tend to neglect the given personas and generate generic responses. To address this issue, we propose a novel Persona-Aware Alignment Framework (PAL), which directly treats persona alignment as the training objective of dialogue generation. Specifically, PAL employs a two-stage training method including Persona-aware Learning and Persona Alignment, equipped with an easy-to-use inference strategy Select then Generate, to improve persona sensitivity and generate more persona-relevant responses at the semantics level. Through extensive experiments, we demonstrate that our framework outperforms many state-of-the-art personalized dialogue methods and large language models.
OmniRetarget: Interaction-Preserving Data Generation for Humanoid Whole-Body Loco-Manipulation and Scene Interaction
Sep 30, 2025A dominant paradigm for teaching humanoid robots complex skills is to retarget human motions as kinematic references to train reinforcement learning (RL) policies. However, existing retargeting pipelines often struggle with the significant embodiment gap between humans and robots, producing physically implausible artifacts like foot-skating and penetration. More importantly, common retargeting methods neglect the rich human-object and human-environment interactions essential for expressive locomotion and loco-manipulation. To address this, we introduce OmniRetarget, an interaction-preserving data generation engine based on an interaction mesh that explicitly models and preserves the crucial spatial and contact relationships between an agent, the terrain, and manipulated objects. By minimizing the Laplacian deformation between the human and robot meshes while enforcing kinematic constraints, OmniRetarget generates kinematically feasible trajectories. Moreover, preserving task-relevant interactions enables efficient data augmentation, from a single demonstration to different robot embodiments, terrains, and object configurations. We comprehensively evaluate OmniRetarget by retargeting motions from OMOMO, LAFAN1, and our in-house MoCap datasets, generating over 8-hour trajectories that achieve better kinematic constraint satisfaction and contact preservation than widely used baselines. Such high-quality data enables proprioceptive RL policies to successfully execute long-horizon (up to 30 seconds) parkour and loco-manipulation skills on a Unitree G1 humanoid, trained with only 5 reward terms and simple domain randomization shared by all tasks, without any learning curriculum.
Learning to Ball: Composing Policies for Long-Horizon Basketball Moves
Sep 26, 2025

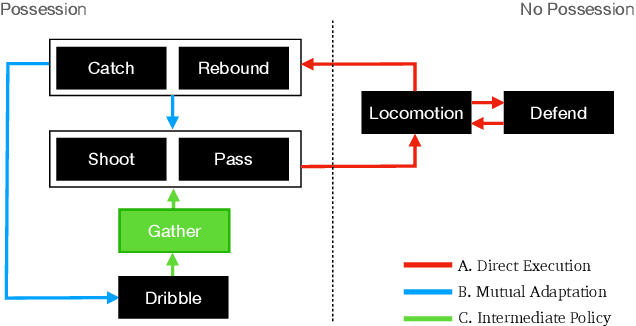

Learning a control policy for a multi-phase, long-horizon task, such as basketball maneuvers, remains challenging for reinforcement learning approaches due to the need for seamless policy composition and transitions between skills. A long-horizon task typically consists of distinct subtasks with well-defined goals, separated by transitional subtasks with unclear goals but critical to the success of the entire task. Existing methods like the mixture of experts and skill chaining struggle with tasks where individual policies do not share significant commonly explored states or lack well-defined initial and terminal states between different phases. In this paper, we introduce a novel policy integration framework to enable the composition of drastically different motor skills in multi-phase long-horizon tasks with ill-defined intermediate states. Based on that, we further introduce a high-level soft router to enable seamless and robust transitions between the subtasks. We evaluate our framework on a set of fundamental basketball skills and challenging transitions. Policies trained by our approach can effectively control the simulated character to interact with the ball and accomplish the long-horizon task specified by real-time user commands, without relying on ball trajectory references.
* ACM Transactions on Graphics (Proceedings of SIGGRAPH Asia 2025). Website: http://pei-xu.github.io/basketball. Video: https://youtu.be/2RBFIjjmR2I. Code: https://github.com/xupei0610/basketball