 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid-Field Channel Estimation for XL-MIMO Systems with Stochastic Gradient Pursuit Algorithm
May 24, 2024



Extremely large-scale multiple-input multiple-output (XL-MIMO) is crucial for satisfying the high data rate requirements of the sixth-generation (6G) wireless networks. In this context, ensuring accurate acquisition of channel state information (CSI) with low complexity becomes imperative. Moreover, deploying an extremely large antenna array at the base station (BS) might result in some scatterers being located in near-field, while others are situated in far-field, leading to a hybrid-field communication scenario. To address these challenges, this paper introduces two stochastic gradient pursuit (SGP)-based schemes for the hybrid-field channel estimation in two scenarios. For the first scenario in which the prior knowledge of the specific proportion of the number of near-field and far-field channel paths is known, the scheme can effectively leverage the angular-domain sparsity of the far-field channels and the polar-domain sparsity of the near-field channels such that the channel estimation in these two fields can be performed separately. For the second scenario which the proportion is not available, we propose an off-grid SGP-based channel estimation scheme, which iterates through the values of the proportion parameter based on a criterion before performing the hybrid-field channel estimation. We demonstrate numerically that both of the proposed channel estimation schemes achieve superior performance in terms of both estimation accuracy and achievable rates while enjoying lower computational complexity compared with existing schemes. Additionally, we reveal that as the number of antennas at the UE increases, the normalized mean square error (NMSE) performances of the proposed schemes remain basically unchanged, while the NMSE performances of existing ones improve. Remarkably, even in this scenario, the proposed schemes continue to outperform the existing ones.
From Algorithm to Hardware: A Survey on Efficient and Safe Deployment of Deep Neural Networks
May 09, 2024



Deep neural networks (DNNs) have been widely used in many artificial intelligence (AI) tasks. However, deploying them brings significant challenges due to the huge cost of memory, energy, and computation. To address these challenges, researchers have developed various model compression techniques such as model quantization and model pruning. Recently, there has been a surge in research of compression methods to achieve model efficiency while retaining the performance. Furthermore, more and more works focus on customizing the DNN hardware accelerators to better leverage the model compression techniques. In addition to efficiency, preserving security and privacy is critical for deploying DNNs. However, the vast and diverse body of related works can be overwhelming. This inspires us to conduct a comprehensive survey on recent research toward the goal of high-performance, cost-efficient, and safe deployment of DNNs. Our survey first covers the mainstream model compression techniques such as model quantization, model pruning, knowledge distillation, and optimizations of non-linear operations. We then introduce recent advances in designing hardware accelerators that can adapt to efficient model compression approaches. Additionally, we discuss how homomorphic encryption can be integrated to secure DNN deployment. Finally, we discuss several issues, such as hardware evaluation, generalization, and integration of various compression approaches. Overall, we aim to provide a big picture of efficient DNNs, from algorithm to hardware accelerators and security perspectives.
AccidentBlip2: Accident Detection With Multi-View MotionBlip2
Apr 19, 2024



Multimodal Large Language Models (MLLMs) have shown outstanding capabilities in many areas of multimodal reasoning. Therefore, we use the reasoning ability of Multimodal Large Language Models for environment description and scene understanding in complex transportation environments. In this paper, we propose AccidentBlip2, a multimodal large language model that can predict in real time whether an accident risk will occur. Our approach involves feature extraction based on the temporal scene of the six-view surround view graphs and temporal inference using the temporal blip framework through the vision transformer. We then input the generated temporal token into the MLLMs for inference to determine whether an accident will occur or not. Since AccidentBlip2 does not rely on any BEV images and LiDAR, the number of inference parameters and the inference cost of MLLMs can be significantly reduced, and it also does not incur a large training overhead during training. AccidentBlip2 outperforms existing solutions on the DeepAccident dataset and can also provide a reference solution for end-to-end automated driving accident prediction.
Generative AI Agent for Next-Generation MIMO Design: Fundamentals, Challenges, and Vision
Apr 13, 2024Next-generation multiple input multiple output (MIMO) is expected to be intelligent and scalable. In this paper, we study generative artificial intelligence (AI) agent-enabled next-generation MIMO design. Firstly, we provide an overview of the development, fundamentals, and challenges of the next-generation MIMO. Then, we propose the concept of the generative AI agent, which is capable of generating tailored and specialized contents with the aid of large language model (LLM) and retrieval augmented generation (RAG). Next, we comprehensively discuss the features and advantages of the generative AI agent framework. More importantly, to tackle existing challenges of next-generation MIMO, we discuss generative AI agent-enabled next-generation MIMO design, from the perspective of performance analysis, signal processing, and resource allocation. Furthermore, we present two compelling case studies that demonstrate the effectiveness of leveraging the generative AI agent for performance analysis in complex configuration scenarios. These examples highlight how the integration of generative AI agents can significantly enhance the analysis and design of next-generation MIMO systems. Finally, we discuss important potential research future directions.
Attention Calibration for Disentangled Text-to-Image Personalization
Apr 11, 2024Recent thrilling progress in large-scale text-to-image (T2I) models has unlocked unprecedented synthesis quality of AI-generated content (AIGC) including image generation, 3D and video composition. Further, personalized techniques enable appealing customized production of a novel concept given only several images as reference. However, an intriguing problem persists: Is it possible to capture multiple, novel concepts from one single reference image? In this paper, we identify that existing approaches fail to preserve visual consistency with the reference image and eliminate cross-influence from concepts. To alleviate this, we propose an attention calibration mechanism to improve the concept-level understanding of the T2I model. Specifically, we first introduce new learnable modifiers bound with classes to capture attributes of multiple concepts. Then, the classes are separated and strengthened following the activation of the cross-attention operation, ensuring comprehensive and self-contained concepts. Additionally, we suppress the attention activation of different classes to mitigate mutual influence among concepts. Together, our proposed method, dubbed DisenDiff, can learn disentangled multiple concepts from one single image and produce novel customized images with learned concepts. We demonstrate that our method outperforms the current state of the art in both qualitative and quantitative evaluations. More importantly, our proposed techniques are compatible with LoRA and inpainting pipelines, enabling more interactive experiences.
Decision Transformer for Wireless Communications: A New Paradigm of Resource Management
Apr 08, 2024



As the next generation of mobile systems evolves, artificial intelligence (AI) is expected to deeply integrate with wireless communications for resource management in variable environments. In particular, deep reinforcement learning (DRL) is an important tool for addressing stochastic optimization issues of resource allocation. However, DRL has to start each new training process from the beginning once the state and action spaces change, causing low sample efficiency and poor generalization ability. Moreover, each DRL training process may take a large number of epochs to converge, which is unacceptable for time-sensitive scenarios. In this paper, we adopt an alternative AI technology, namely, the Decision Transformer (DT), and propose a DT-based adaptive decision architecture for wireless resource management. This architecture innovates through constructing pre-trained models in the cloud and then fine-tuning personalized models at the edges. By leveraging the power of DT models learned over extensive datasets, the proposed architecture is expected to achieve rapid convergence with many fewer training epochs and higher performance in a new context, e.g., similar tasks with different state and action spaces, compared with DRL. We then design DT frameworks for two typical communication scenarios: Intelligent reflecting surfaces-aided communications and unmanned aerial vehicle-aided edge computing. Simulations demonstrate that the proposed DT frameworks achieve over $3$-$6$ times speedup in convergence and better performance relative to the classic DRL method, namely, proximal policy optimization.
DiffBody: Human Body Restoration by Imagining with Generative Diffusion Prior
Apr 04, 2024



Human body restoration plays a vital role in various applications related to the human body. Despite recent advances in general image restoration using generative models, their performance in human body restoration remains mediocre, often resulting in foreground and background blending, over-smoothing surface textures, missing accessories, and distorted limbs. Addressing these challenges, we propose a novel approach by constructing a human body-aware diffusion model that leverages domain-specific knowledge to enhance performance. Specifically, we employ a pretrained body attention module to guide the diffusion model's focus on the foreground, addressing issues caused by blending between the subject and background. We also demonstrate the value of revisiting the language modality of the diffusion model in restoration tasks by seamlessly incorporating text prompt to improve the quality of surface texture and additional clothing and accessories details. Additionally, we introduce a diffusion sampler tailored for fine-grained human body parts, utilizing local semantic information to rectify limb distortions. Lastly, we collect a comprehensive dataset for benchmarking and advancing the field of human body restoration. Extensive experimental validation showcases the superiority of our approach, both quantitatively and qualitatively, over existing methods.
Self-Supervised Class-Agnostic Motion Prediction with Spatial and Temporal Consistency Regularizations
Mar 21, 2024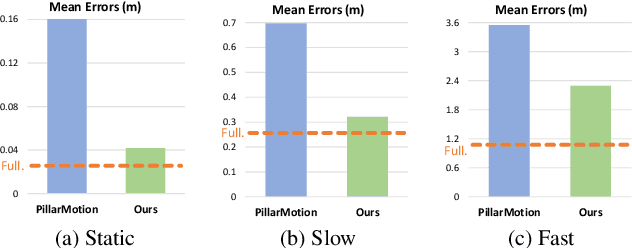
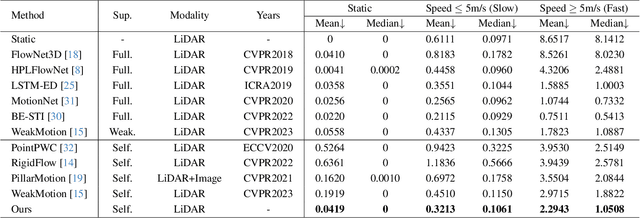
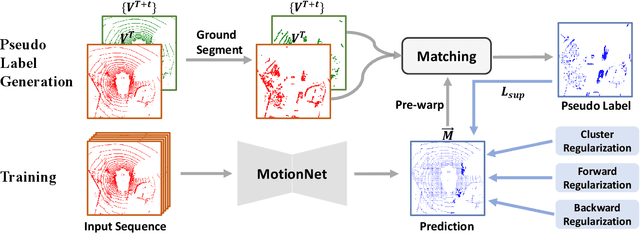
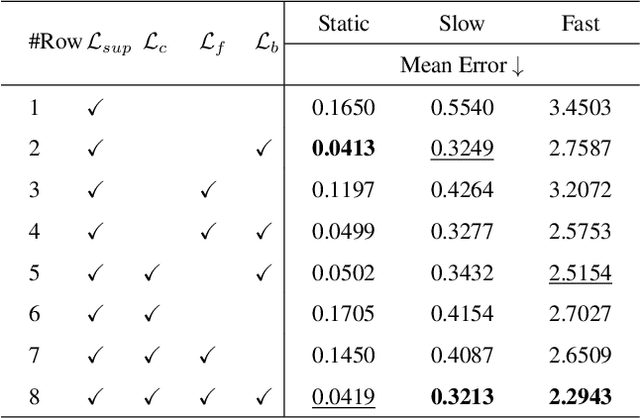
The perception of motion behavior in a dynamic environment holds significant importance for autonomous driving systems, wherein class-agnostic motion prediction methods directly predict the motion of the entire point cloud. While most existing methods rely on fully-supervised learning, the manual labeling of point cloud data is laborious and time-consuming. Therefore, several annotation-efficient methods have been proposed to address this challenge. Although effective, these methods rely on weak annotations or additional multi-modal data like images, and the potential benefits inherent in the point cloud sequence are still underexplored. To this end, we explore the feasibility of self-supervised motion prediction with only unlabeled LiDAR point clouds. Initially, we employ an optimal transport solver to establish coarse correspondences between current and future point clouds as the coarse pseudo motion labels. Training models directly using such coarse labels leads to noticeable spatial and temporal prediction inconsistencies. To mitigate these issues, we introduce three simple spatial and temporal regularization losses, which facilitate the self-supervised training process effectively. Experimental results demonstrate the significant superiority of our approach over the state-of-the-art self-supervised methods.
S-DyRF: Reference-Based Stylized Radiance Fields for Dynamic Scenes
Mar 13, 2024



Current 3D stylization methods often assume static scenes, which violates the dynamic nature of our real world. To address this limitation, we present S-DyRF, a reference-based spatio-temporal stylization method for dynamic neural radiance fields. However, stylizing dynamic 3D scenes is inherently challenging due to the limited availability of stylized reference images along the temporal axis. Our key insight lies in introducing additional temporal cues besides the provided reference. To this end, we generate temporal pseudo-references from the given stylized reference. These pseudo-references facilitate the propagation of style information from the reference to the entire dynamic 3D scene. For coarse style transfer, we enforce novel views and times to mimic the style details present in pseudo-references at the feature level. To preserve high-frequency details, we create a collection of stylized temporal pseudo-rays from temporal pseudo-references. These pseudo-rays serve as detailed and explicit stylization guidance for achieving fine style transfer. Experiments on both synthetic and real-world datasets demonstrate that our method yields plausible stylized results of space-time view synthesis on dynamic 3D scenes.
SparseLIF: High-Performance Sparse LiDAR-Camera Fusion for 3D Object Detection
Mar 12, 2024Sparse 3D detectors have received significant attention since the query-based paradigm embraces low latency without explicit dense BEV feature construction. However, these detectors achieve worse performance than their dense counterparts. In this paper, we find the key to bridging the performance gap is to enhance the awareness of rich representations in two modalities. Here, we present a high-performance fully sparse detector for end-to-end multi-modality 3D object detection. The detector, termed SparseLIF, contains three key designs, which are (1) Perspective-Aware Query Generation (PAQG) to generate high-quality 3D queries with perspective priors, (2) RoI-Aware Sampling (RIAS) to further refine prior queries by sampling RoI features from each modality, (3) Uncertainty-Aware Fusion (UAF) to precisely quantify the uncertainty of each sensor modality and adaptively conduct final multi-modality fusion, thus achieving great robustness against sensor noises. By the time of submission (2024/03/08), SparseLIF achieves state-of-the-art performance on the nuScenes dataset, ranking 1st on both validation set and test benchmark, outperforming all state-of-the-art 3D object detectors by a notable margin. The source code will be released upon acceptance.