 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Foundation Models: From Specialists to General-Purpose Assistants
Sep 18, 2023This paper presents a comprehensive survey of the taxonomy and evolution of multimodal foundation models that demonstrate vision and vision-language capabilities, focusing on the transition from specialist models to general-purpose assistants. The research landscape encompasses five core topics, categorized into two classes. (i) We start with a survey of well-established research areas: multimodal foundation models pre-trained for specific purposes, including two topics -- methods of learning vision backbones for visual understanding and text-to-image generation. (ii) Then, we present recent advances in exploratory, open research areas: multimodal foundation models that aim to play the role of general-purpose assistants, including three topics -- unified vision models inspired by large language models (LLMs), end-to-end training of multimodal LLMs, and chaining multimodal tools with LLMs. The target audiences of the paper are researchers, graduate students, and professionals in computer vision and vision-language multimodal communities who are eager to learn the basics and recent advances in multimodal foundation models.
MOFI: Learning Image Representations from Noisy Entity Annotated Images
Jun 24, 2023We present MOFI, a new vision foundation model designed to learn image representations from noisy entity annotated images. MOFI differs from previous work in two key aspects: ($i$) pre-training data, and ($ii$) training recipe. Regarding data, we introduce a new approach to automatically assign entity labels to images from noisy image-text pairs. Our approach involves employing a named entity recognition model to extract entities from the alt-text, and then using a CLIP model to select the correct entities as labels of the paired image. The approach is simple, does not require costly human annotation, and can be readily scaled up to billions of image-text pairs mined from the web. Through this method, we have created Image-to-Entities (I2E), a new large-scale dataset with 1 billion images and 2 million distinct entities, covering rich visual concepts in the wild. Building upon the I2E dataset, we study different training recipes, including supervised pre-training, contrastive pre-training, and multi-task learning. For constrastive pre-training, we treat entity names as free-form text, and further enrich them with entity descriptions. Experiments show that supervised pre-training with large-scale fine-grained entity labels is highly effective for image retrieval tasks, and multi-task training further improves the performance. The final MOFI model achieves 86.66% mAP on the challenging GPR1200 dataset, surpassing the previous state-of-the-art performance of 72.19% from OpenAI's CLIP model. Further experiments on zero-shot and linear probe image classification also show that MOFI outperforms a CLIP model trained on the original image-text data, demonstrating the effectiveness of the I2E dataset in learning strong image representations.
An Empirical Study of Multimodal Model Merging
Apr 28, 2023Model merging (e.g., via interpolation or task arithmetic) fuses multiple models trained on different tasks to generate a multi-task solution. The technique has been proven successful in previous studies, where the models are trained on similar tasks and with the same initialization. In this paper, we expand on this concept to a multimodal setup by merging transformers trained on different modalities. Furthermore, we conduct our study for a novel goal where we can merge vision, language, and cross-modal transformers of a modality-specific architecture to create a parameter-efficient modality-agnostic architecture. Through comprehensive experiments, we systematically investigate the key factors impacting model performance after merging, including initialization, merging mechanisms, and model architectures. Our analysis leads to an effective training recipe for matching the performance of the modality-agnostic baseline (i.e. pre-trained from scratch) via model merging. Our code is available at: https://github.com/ylsung/vl-merging
Diagnostic Benchmark and Iterative Inpainting for Layout-Guided Image Generation
Apr 14, 2023
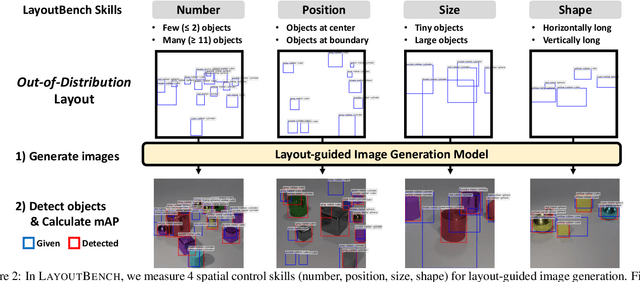
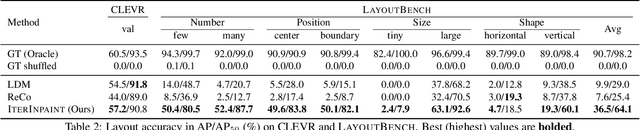
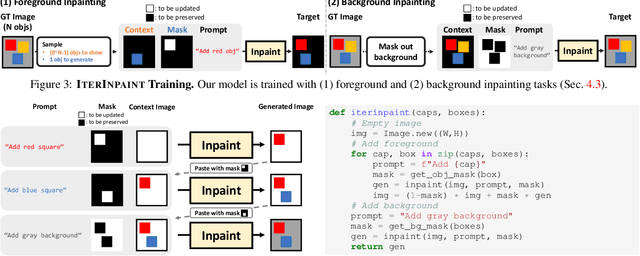
Spatial control is a core capability in controllable image generation. Advancements in layout-guided image generation have shown promising results on in-distribution (ID) datasets with similar spatial configurations. However, it is unclear how these models perform when facing out-of-distribution (OOD) samples with arbitrary, unseen layouts. In this paper, we propose LayoutBench, a diagnostic benchmark for layout-guided image generation that examines four categories of spatial control skills: number, position, size, and shape. We benchmark two recent representative layout-guided image generation methods and observe that the good ID layout control may not generalize well to arbitrary layouts in the wild (e.g., objects at the boundary). Next, we propose IterInpaint, a new baseline that generates foreground and background regions in a step-by-step manner via inpainting, demonstrating stronger generalizability than existing models on OOD layouts in LayoutBench. We perform quantitative and qualitative evaluation and fine-grained analysis on the four LayoutBench skills to pinpoint the weaknesses of existing models. Lastly, we show comprehensive ablation studies on IterInpaint, including training task ratio, crop&paste vs. repaint, and generation order. Project website: https://layoutbench.github.io
Generalized Decoding for Pixel, Image, and Language
Dec 21, 2022



We present X-Decoder, a generalized decoding model that can predict pixel-level segmentation and language tokens seamlessly. X-Decodert takes as input two types of queries: (i) generic non-semantic queries and (ii) semantic queries induced from text inputs, to decode different pixel-level and token-level outputs in the same semantic space. With such a novel design, X-Decoder is the first work that provides a unified way to support all types of image segmentation and a variety of vision-language (VL) tasks. Further, our design enables seamless interactions across tasks at different granularities and brings mutual benefits by learning a common and rich pixel-level visual-semantic understanding space, without any pseudo-labeling. After pretraining on a mixed set of a limited amount of segmentation data and millions of image-text pairs, X-Decoder exhibits strong transferability to a wide range of downstream tasks in both zero-shot and finetuning settings. Notably, it achieves (1) state-of-the-art results on open-vocabulary segmentation and referring segmentation on eight datasets; (2) better or competitive finetuned performance to other generalist and specialist models on segmentation and VL tasks; and (3) flexibility for efficient finetuning and novel task composition (e.g., referring captioning and image editing). Code, demo, video, and visualization are available at https://x-decoder-vl.github.io.
Exploring Discrete Diffusion Models for Image Captioning
Dec 09, 2022



The image captioning task is typically realized by an auto-regressive method that decodes the text tokens one by one. We present a diffusion-based captioning model, dubbed the name DDCap, to allow more decoding flexibility. Unlike image generation, where the output is continuous and redundant with a fixed length, texts in image captions are categorical and short with varied lengths. Therefore, naively applying the discrete diffusion model to text decoding does not work well, as shown in our experiments. To address the performance gap, we propose several key techniques including best-first inference, concentrated attention mask, text length prediction, and image-free training. On COCO without additional caption pre-training, it achieves a CIDEr score of 117.8, which is +5.0 higher than the auto-regressive baseline with the same architecture in the controlled setting. It also performs +26.8 higher CIDEr score than the auto-regressive baseline (230.3 v.s.203.5) on a caption infilling task. With 4M vision-language pre-training images and the base-sized model, we reach a CIDEr score of 125.1 on COCO, which is competitive to the best well-developed auto-regressive frameworks. The code is available at https://github.com/buxiangzhiren/DDCap.
GRiT: A Generative Region-to-text Transformer for Object Understanding
Dec 01, 2022This paper presents a Generative RegIon-to-Text transformer, GRiT, for object understanding. The spirit of GRiT is to formulate object understanding as <region, text> pairs, where region locates objects and text describes objects. For example, the text in object detection denotes class names while that in dense captioning refers to descriptive sentences. Specifically, GRiT consists of a visual encoder to extract image features, a foreground object extractor to localize objects, and a text decoder to generate open-set object descriptions. With the same model architecture, GRiT can understand objects via not only simple nouns, but also rich descriptive sentences including object attributes or actions. Experimentally, we apply GRiT to object detection and dense captioning tasks. GRiT achieves 60.4 AP on COCO 2017 test-dev for object detection and 15.5 mAP on Visual Genome for dense captioning. Code is available at https://github.com/JialianW/GRiT
ReCo: Region-Controlled Text-to-Image Generation
Nov 23, 2022Recently, large-scale text-to-image (T2I) models have shown impressive performance in generating high-fidelity images, but with limited controllability, e.g., precisely specifying the content in a specific region with a free-form text description. In this paper, we propose an effective technique for such regional control in T2I generation. We augment T2I models' inputs with an extra set of position tokens, which represent the quantized spatial coordinates. Each region is specified by four position tokens to represent the top-left and bottom-right corners, followed by an open-ended natural language regional description. Then, we fine-tune a pre-trained T2I model with such new input interface. Our model, dubbed as ReCo (Region-Controlled T2I), enables the region control for arbitrary objects described by open-ended regional texts rather than by object labels from a constrained category set. Empirically, ReCo achieves better image quality than the T2I model strengthened by positional words (FID: 8.82->7.36, SceneFID: 15.54->6.51 on COCO), together with objects being more accurately placed, amounting to a 20.40% region classification accuracy improvement on COCO. Furthermore, we demonstrate that ReCo can better control the object count, spatial relationship, and region attributes such as color/size, with the free-form regional description. Human evaluation on PaintSkill shows that ReCo is +19.28% and +17.21% more accurate in generating images with correct object count and spatial relationship than the T2I model.
Non-Contrastive Learning Meets Language-Image Pre-Training
Oct 17, 2022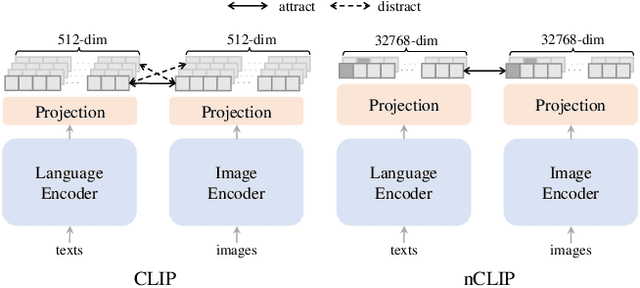

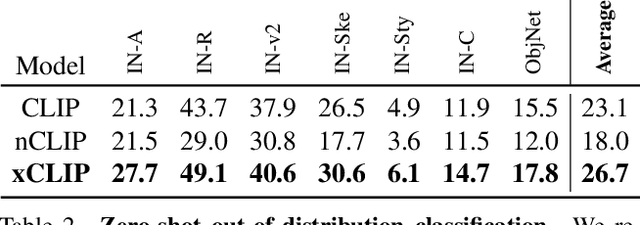
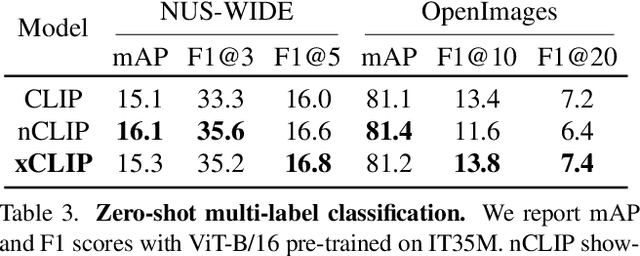
Contrastive language-image pre-training (CLIP) serves as a de-facto standard to align images and texts. Nonetheless, the loose correlation between images and texts of web-crawled data renders the contrastive objective data inefficient and craving for a large training batch size. In this work, we explore the validity of non-contrastive language-image pre-training (nCLIP), and study whether nice properties exhibited in visual self-supervised models can emerge. We empirically observe that the non-contrastive objective nourishes representation learning while sufficiently underperforming under zero-shot recognition. Based on the above study, we further introduce xCLIP, a multi-tasking framework combining CLIP and nCLIP, and show that nCLIP aids CLIP in enhancing feature semantics. The synergy between two objectives lets xCLIP enjoy the best of both worlds: superior performance in both zero-shot transfer and representation learning. Systematic evaluation is conducted spanning a wide variety of downstream tasks including zero-shot classification, out-of-domain classification, retrieval, visual representation learning, and textual representation learning, showcasing a consistent performance gain and validating the effectiveness of xCLIP.
Vision-Language Pre-training: Basics, Recent Advances, and Future Trends
Oct 17, 2022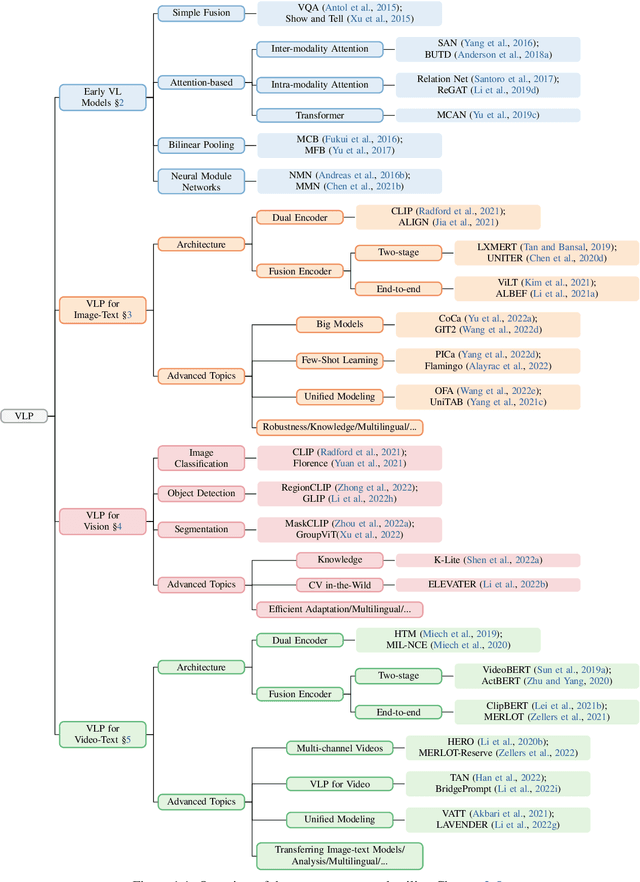
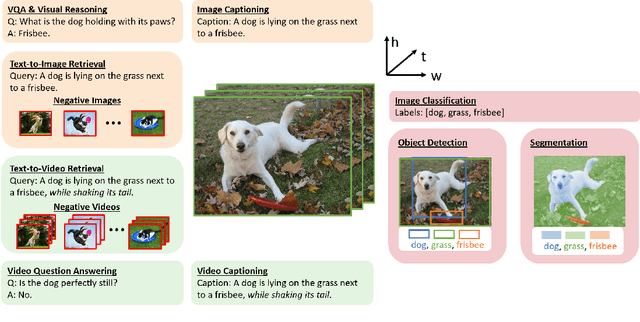
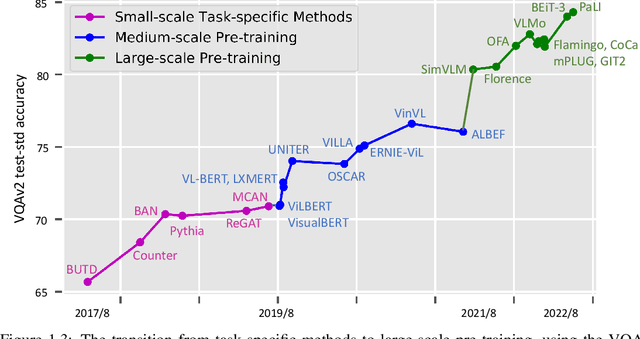

This paper surveys vision-language pre-training (VLP) methods for multimodal intelligence that have been developed in the last few years. We group these approaches into three categories: ($i$) VLP for image-text tasks, such as image captioning, image-text retrieval, visual question answering, and visual grounding; ($ii$) VLP for core computer vision tasks, such as (open-set) image classification, object detection, and segmentation; and ($iii$) VLP for video-text tasks, such as video captioning, video-text retrieval, and video question answering. For each category, we present a comprehensive review of state-of-the-art methods, and discuss the progress that has been made and challenges still being faced, using specific systems and models as case studies. In addition, for each category, we discuss advanced topics being actively explored in the research community, such as big foundation models, unified modeling, in-context few-shot learning, knowledge, robustness, and computer vision in the wild, to name a few.