 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEE4D: Pose-Free 4D Generation via Auto-Regressive Video Inpainting
Oct 30, 2025Immersive applications call for synthesizing spatiotemporal 4D content from casual videos without costly 3D supervision. Existing video-to-4D methods typically rely on manually annotated camera poses, which are labor-intensive and brittle for in-the-wild footage. Recent warp-then-inpaint approaches mitigate the need for pose labels by warping input frames along a novel camera trajectory and using an inpainting model to fill missing regions, thereby depicting the 4D scene from diverse viewpoints. However, this trajectory-to-trajectory formulation often entangles camera motion with scene dynamics and complicates both modeling and inference. We introduce SEE4D, a pose-free, trajectory-to-camera framework that replaces explicit trajectory prediction with rendering to a bank of fixed virtual cameras, thereby separating camera control from scene modeling. A view-conditional video inpainting model is trained to learn a robust geometry prior by denoising realistically synthesized warped images and to inpaint occluded or missing regions across virtual viewpoints, eliminating the need for explicit 3D annotations. Building on this inpainting core, we design a spatiotemporal autoregressive inference pipeline that traverses virtual-camera splines and extends videos with overlapping windows, enabling coherent generation at bounded per-step complexity. We validate See4D on cross-view video generation and sparse reconstruction benchmarks. Across quantitative metrics and qualitative assessments, our method achieves superior generalization and improved performance relative to pose- or trajectory-conditioned baselines, advancing practical 4D world modeling from casual videos.
LongLive: Real-time Interactive Long Video Generation
Sep 26, 2025We present LongLive, a frame-level autoregressive (AR) framework for real-time and interactive long video generation. Long video generation presents challenges in both efficiency and quality. Diffusion and Diffusion-Forcing models can produce high-quality videos but suffer from low efficiency due to bidirectional attention. Causal attention AR models support KV caching for faster inference, but often degrade in quality on long videos due to memory challenges during long-video training. In addition, beyond static prompt-based generation, interactive capabilities, such as streaming prompt inputs, are critical for dynamic content creation, enabling users to guide narratives in real time. This interactive requirement significantly increases complexity, especially in ensuring visual consistency and semantic coherence during prompt transitions. To address these challenges, LongLive adopts a causal, frame-level AR design that integrates a KV-recache mechanism that refreshes cached states with new prompts for smooth, adherent switches; streaming long tuning to enable long video training and to align training and inference (train-long-test-long); and short window attention paired with a frame-level attention sink, shorten as frame sink, preserving long-range consistency while enabling faster generation. With these key designs, LongLive fine-tunes a 1.3B-parameter short-clip model to minute-long generation in just 32 GPU-days. At inference, LongLive sustains 20.7 FPS on a single NVIDIA H100, achieves strong performance on VBench in both short and long videos. LongLive supports up to 240-second videos on a single H100 GPU. LongLive further supports INT8-quantized inference with only marginal quality loss.
AppAgent-Pro: A Proactive GUI Agent System for Multidomain Information Integration and User Assistance
Aug 27, 2025
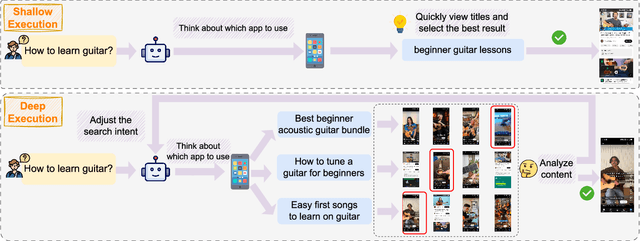


Large language model (LLM)-based agents have demonstrated remarkable capabilities in addressing complex tasks, thereby enabling more advanced information retrieval and supporting deeper, more sophisticated human information-seeking behaviors. However, most existing agents operate in a purely reactive manner, responding passively to user instructions, which significantly constrains their effectiveness and efficiency as general-purpose platforms for information acquisition. To overcome this limitation, this paper proposes AppAgent-Pro, a proactive GUI agent system that actively integrates multi-domain information based on user instructions. This approach enables the system to proactively anticipate users' underlying needs and conduct in-depth multi-domain information mining, thereby facilitating the acquisition of more comprehensive and intelligent information. AppAgent-Pro has the potential to fundamentally redefine information acquisition in daily life, leading to a profound impact on human society. Our code is available at: https://github.com/LaoKuiZe/AppAgent-Pro. The demonstration video could be found at: https://www.dropbox.com/scl/fi/hvzqo5vnusg66srydzixo/AppAgent-Pro-demo-video.mp4?rlkey=o2nlfqgq6ihl125mcqg7bpgqu&st=d29vrzii&dl=0.
SANA 1.5: Efficient Scaling of Training-Time and Inference-Time Compute in Linear Diffusion Transformer
Jan 30, 2025



This paper presents SANA-1.5, a linear Diffusion Transformer for efficient scaling in text-to-image generation. Building upon SANA-1.0, we introduce three key innovations: (1) Efficient Training Scaling: A depth-growth paradigm that enables scaling from 1.6B to 4.8B parameters with significantly reduced computational resources, combined with a memory-efficient 8-bit optimizer. (2) Model Depth Pruning: A block importance analysis technique for efficient model compression to arbitrary sizes with minimal quality loss. (3) Inference-time Scaling: A repeated sampling strategy that trades computation for model capacity, enabling smaller models to match larger model quality at inference time. Through these strategies, SANA-1.5 achieves a text-image alignment score of 0.72 on GenEval, which can be further improved to 0.80 through inference scaling, establishing a new SoTA on GenEval benchmark. These innovations enable efficient model scaling across different compute budgets while maintaining high quality, making high-quality image generation more accessible.
GenXD: Generating Any 3D and 4D Scenes
Nov 05, 2024



Recent developments in 2D visual generation have been remarkably successful. However, 3D and 4D generation remain challenging in real-world applications due to the lack of large-scale 4D data and effective model design. In this paper, we propose to jointly investigate general 3D and 4D generation by leveraging camera and object movements commonly observed in daily life. Due to the lack of real-world 4D data in the community, we first propose a data curation pipeline to obtain camera poses and object motion strength from videos. Based on this pipeline, we introduce a large-scale real-world 4D scene dataset: CamVid-30K. By leveraging all the 3D and 4D data, we develop our framework, GenXD, which allows us to produce any 3D or 4D scene. We propose multiview-temporal modules, which disentangle camera and object movements, to seamlessly learn from both 3D and 4D data. Additionally, GenXD employs masked latent conditions to support a variety of conditioning views. GenXD can generate videos that follow the camera trajectory as well as consistent 3D views that can be lifted into 3D representations. We perform extensive evaluations across various real-world and synthetic datasets, demonstrating GenXD's effectiveness and versatility compared to previous methods in 3D and 4D generation.
TreeSBA: Tree-Transformer for Self-Supervised Sequential Brick Assembly
Jul 22, 2024



Inferring step-wise actions to assemble 3D objects with primitive bricks from images is a challenging task due to complex constraints and the vast number of possible combinations. Recent studies have demonstrated promising results on sequential LEGO brick assembly through the utilization of LEGO-Graph modeling to predict sequential actions. However, existing approaches are class-specific and require significant computational and 3D annotation resources. In this work, we first propose a computationally efficient breadth-first search (BFS) LEGO-Tree structure to model the sequential assembly actions by considering connections between consecutive layers. Based on the LEGO-Tree structure, we then design a class-agnostic tree-transformer framework to predict the sequential assembly actions from the input multi-view images. A major challenge of the sequential brick assembly task is that the step-wise action labels are costly and tedious to obtain in practice. We mitigate this problem by leveraging synthetic-to-real transfer learning. Specifically, our model is first pre-trained on synthetic data with full supervision from the available action labels. We then circumvent the requirement for action labels in the real data by proposing an action-to-silhouette projection that replaces action labels with input image silhouettes for self-supervision. Without any annotation on the real data, our model outperforms existing methods with 3D supervision by 7.8% and 11.3% in mIoU on the MNIST and ModelNet Construction datasets, respectively.
X-Ray: A Sequential 3D Representation for Generation
Apr 22, 2024In this paper, we introduce X-Ray, an innovative approach to 3D generation that employs a new sequential representation, drawing inspiration from the depth-revealing capabilities of X-Ray scans to meticulously capture both the external and internal features of objects. Central to our method is the utilization of ray casting techniques originating from the camera's viewpoint, meticulously recording the geometric and textural details encountered across all intersected surfaces. This process efficiently condenses complete objects or scenes into a multi-frame format, just like videos. Such a structure ensures the 3D representation is composed solely of critical surface information. Highlighting the practicality and adaptability of our X-Ray representation, we showcase its utility in synthesizing 3D objects, employing a network architecture akin to that used in video diffusion models. The outcomes reveal our representation's superior performance in enhancing both the accuracy and efficiency of 3D synthesis, heralding new directions for ongoing research and practical implementations in the field.
Zero-shot Point Cloud Completion Via 2D Priors
Apr 10, 20243D point cloud completion is designed to recover complete shapes from partially observed point clouds. Conventional completion methods typically depend on extensive point cloud data for training %, with their effectiveness often constrained to object categories similar to those seen during training. In contrast, we propose a zero-shot framework aimed at completing partially observed point clouds across any unseen categories. Leveraging point rendering via Gaussian Splatting, we develop techniques of Point Cloud Colorization and Zero-shot Fractal Completion that utilize 2D priors from pre-trained diffusion models to infer missing regions. Experimental results on both synthetic and real-world scanned point clouds demonstrate that our approach outperforms existing methods in completing a variety of objects without any requirement for specific training data.
Segment Any 3D Object with Language
Apr 02, 2024



In this paper, we investigate Open-Vocabulary 3D Instance Segmentation (OV-3DIS) with free-form language instructions. Earlier works that rely on only annotated base categories for training suffer from limited generalization to unseen novel categories. Recent works mitigate poor generalizability to novel categories by generating class-agnostic masks or projecting generalized masks from 2D to 3D, but disregard semantic or geometry information, leading to sub-optimal performance. Instead, generating generalizable but semantic-related masks directly from 3D point clouds would result in superior outcomes. In this paper, we introduce Segment any 3D Object with LanguagE (SOLE), which is a semantic and geometric-aware visual-language learning framework with strong generalizability by generating semantic-related masks directly from 3D point clouds. Specifically, we propose a multimodal fusion network to incorporate multimodal semantics in both backbone and decoder. In addition, to align the 3D segmentation model with various language instructions and enhance the mask quality, we introduce three types of multimodal associations as supervision. Our SOLE outperforms previous methods by a large margin on ScanNetv2, ScanNet200, and Replica benchmarks, and the results are even close to the fully-supervised counterpart despite the absence of class annotations in the training. Furthermore, extensive qualitative results demonstrate the versatility of our SOLE to language instructions.
Animate124: Animating One Image to 4D Dynamic Scene
Nov 24, 2023



We introduce Animate124 (Animate-one-image-to-4D), the first work to animate a single in-the-wild image into 3D video through textual motion descriptions, an underexplored problem with significant applications. Our 4D generation leverages an advanced 4D grid dynamic Neural Radiance Field (NeRF) model, optimized in three distinct stages using multiple diffusion priors. Initially, a static model is optimized using the reference image, guided by 2D and 3D diffusion priors, which serves as the initialization for the dynamic NeRF. Subsequently, a video diffusion model is employed to learn the motion specific to the subject. However, the object in the 3D videos tends to drift away from the reference image over time. This drift is mainly due to the misalignment between the text prompt and the reference image in the video diffusion model. In the final stage, a personalized diffusion prior is therefore utilized to address the semantic drift. As the pioneering image-text-to-4D generation framework, our method demonstrates significant advancements over existing baselines, evidenced by comprehensive quantitative and qualitative assessments.