 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenXD: Generating Any 3D and 4D Scenes
Nov 05, 2024



Recent developments in 2D visual generation have been remarkably successful. However, 3D and 4D generation remain challenging in real-world applications due to the lack of large-scale 4D data and effective model design. In this paper, we propose to jointly investigate general 3D and 4D generation by leveraging camera and object movements commonly observed in daily life. Due to the lack of real-world 4D data in the community, we first propose a data curation pipeline to obtain camera poses and object motion strength from videos. Based on this pipeline, we introduce a large-scale real-world 4D scene dataset: CamVid-30K. By leveraging all the 3D and 4D data, we develop our framework, GenXD, which allows us to produce any 3D or 4D scene. We propose multiview-temporal modules, which disentangle camera and object movements, to seamlessly learn from both 3D and 4D data. Additionally, GenXD employs masked latent conditions to support a variety of conditioning views. GenXD can generate videos that follow the camera trajectory as well as consistent 3D views that can be lifted into 3D representations. We perform extensive evaluations across various real-world and synthetic datasets, demonstrating GenXD's effectiveness and versatility compared to previous methods in 3D and 4D generation.
Zero-shot Point Cloud Completion Via 2D Priors
Apr 10, 20243D point cloud completion is designed to recover complete shapes from partially observed point clouds. Conventional completion methods typically depend on extensive point cloud data for training %, with their effectiveness often constrained to object categories similar to those seen during training. In contrast, we propose a zero-shot framework aimed at completing partially observed point clouds across any unseen categories. Leveraging point rendering via Gaussian Splatting, we develop techniques of Point Cloud Colorization and Zero-shot Fractal Completion that utilize 2D priors from pre-trained diffusion models to infer missing regions. Experimental results on both synthetic and real-world scanned point clouds demonstrate that our approach outperforms existing methods in completing a variety of objects without any requirement for specific training data.
Multi-Scale 3D Gaussian Splatting for Anti-Aliased Rendering
Nov 28, 2023



3D Gaussians have recently emerged as a highly efficient representation for 3D reconstruction and rendering. Despite its high rendering quality and speed at high resolutions, they both deteriorate drastically when rendered at lower resolutions or from far away camera position. During low resolution or far away rendering, the pixel size of the image can fall below the Nyquist frequency compared to the screen size of each splatted 3D Gaussian and leads to aliasing effect. The rendering is also drastically slowed down by the sequential alpha blending of more splatted Gaussians per pixel. To address these issues, we propose a multi-scale 3D Gaussian splatting algorithm, which maintains Gaussians at different scales to represent the same scene. Higher-resolution images are rendered with more small Gaussians, and lower-resolution images are rendered with fewer larger Gaussians. With similar training time, our algorithm can achieve 13\%-66\% PSNR and 160\%-2400\% rendering speed improvement at 4$\times$-128$\times$ scale rendering on Mip-NeRF360 dataset compared to the single scale 3D Gaussian splatting.
Animate124: Animating One Image to 4D Dynamic Scene
Nov 24, 2023



We introduce Animate124 (Animate-one-image-to-4D), the first work to animate a single in-the-wild image into 3D video through textual motion descriptions, an underexplored problem with significant applications. Our 4D generation leverages an advanced 4D grid dynamic Neural Radiance Field (NeRF) model, optimized in three distinct stages using multiple diffusion priors. Initially, a static model is optimized using the reference image, guided by 2D and 3D diffusion priors, which serves as the initialization for the dynamic NeRF. Subsequently, a video diffusion model is employed to learn the motion specific to the subject. However, the object in the 3D videos tends to drift away from the reference image over time. This drift is mainly due to the misalignment between the text prompt and the reference image in the video diffusion model. In the final stage, a personalized diffusion prior is therefore utilized to address the semantic drift. As the pioneering image-text-to-4D generation framework, our method demonstrates significant advancements over existing baselines, evidenced by comprehensive quantitative and qualitative assessments.
GNeSF: Generalizable Neural Semantic Fields
Oct 26, 2023



3D scene segmentation based on neural implicit representation has emerged recently with the advantage of training only on 2D supervision. However, existing approaches still requires expensive per-scene optimization that prohibits generalization to novel scenes during inference. To circumvent this problem, we introduce a generalizable 3D segmentation framework based on implicit representation. Specifically, our framework takes in multi-view image features and semantic maps as the inputs instead of only spatial information to avoid overfitting to scene-specific geometric and semantic information. We propose a novel soft voting mechanism to aggregate the 2D semantic information from different views for each 3D point. In addition to the image features, view difference information is also encoded in our framework to predict the voting scores. Intuitively, this allows the semantic information from nearby views to contribute more compared to distant ones. Furthermore, a visibility module is also designed to detect and filter out detrimental information from occluded views. Due to the generalizability of our proposed method, we can synthesize semantic maps or conduct 3D semantic segmentation for novel scenes with solely 2D semantic supervision. Experimental results show that our approach achieves comparable performance with scene-specific approaches. More importantly, our approach can even outperform existing strong supervision-based approaches with only 2D annotations. Our source code is available at: https://github.com/HLinChen/GNeSF.
OD-NeRF: Efficient Training of On-the-Fly Dynamic Neural Radiance Fields
May 24, 2023



Dynamic neural radiance fields (dynamic NeRFs) have demonstrated impressive results in novel view synthesis on 3D dynamic scenes. However, they often require complete video sequences for training followed by novel view synthesis, which is similar to playing back the recording of a dynamic 3D scene. In contrast, we propose OD-NeRF to efficiently train and render dynamic NeRFs on-the-fly which instead is capable of streaming the dynamic scene. When training on-the-fly, the training frames become available sequentially and the model is trained and rendered frame-by-frame. The key challenge of efficient on-the-fly training is how to utilize the radiance field estimated from the previous frames effectively. To tackle this challenge, we propose: 1) a NeRF model conditioned on the multi-view projected colors to implicitly track correspondence between the current and previous frames, and 2) a transition and update algorithm that leverages the occupancy grid from the last frame to sample efficiently at the current frame. Our algorithm can achieve an interactive speed of 6FPS training and rendering on synthetic dynamic scenes on-the-fly, and a significant speed-up compared to the state-of-the-art on real-world dynamic scenes.
NeRF-DS: Neural Radiance Fields for Dynamic Specular Objects
Mar 25, 2023



Dynamic Neural Radiance Field (NeRF) is a powerful algorithm capable of rendering photo-realistic novel view images from a monocular RGB video of a dynamic scene. Although it warps moving points across frames from the observation spaces to a common canonical space for rendering, dynamic NeRF does not model the change of the reflected color during the warping. As a result, this approach often fails drastically on challenging specular objects in motion. We address this limitation by reformulating the neural radiance field function to be conditioned on surface position and orientation in the observation space. This allows the specular surface at different poses to keep the different reflected colors when mapped to the common canonical space. Additionally, we add the mask of moving objects to guide the deformation field. As the specular surface changes color during motion, the mask mitigates the problem of failure to find temporal correspondences with only RGB supervision. We evaluate our model based on the novel view synthesis quality with a self-collected dataset of different moving specular objects in realistic environments. The experimental results demonstrate that our method significantly improves the reconstruction quality of moving specular objects from monocular RGB videos compared to the existing NeRF models. Our code and data are available at the project website https://github.com/JokerYan/NeRF-DS.
Adaptive Modeling Against Adversarial Attacks
Dec 23, 2021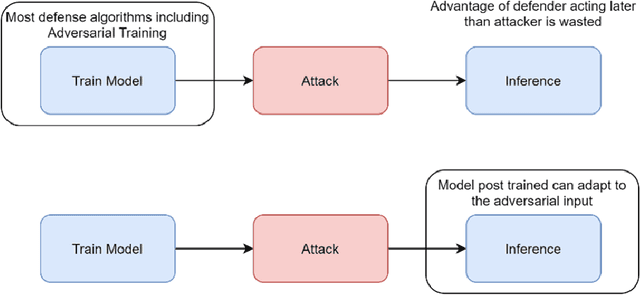

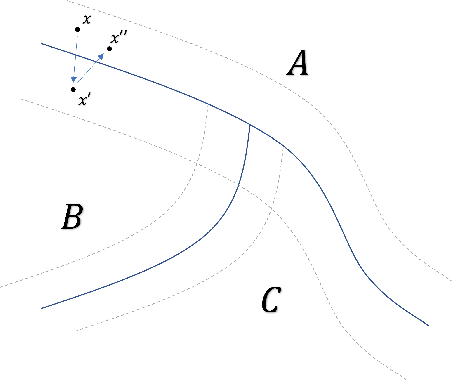
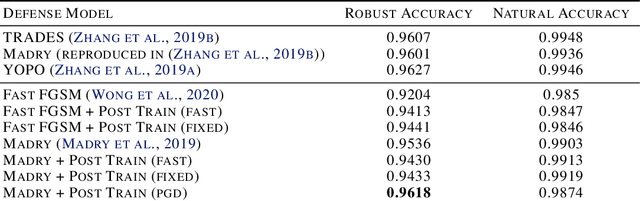
Adversarial training, the process of training a deep learning model with adversarial data, is one of the most successful adversarial defense methods for deep learning models. We have found that the robustness to white-box attack of an adversarially trained model can be further improved if we fine tune this model in inference stage to adapt to the adversarial input, with the extra information in it. We introduce an algorithm that "post trains" the model at inference stage between the original output class and a "neighbor" class, with existing training data. The accuracy of pre-trained Fast-FGSM CIFAR10 classifier base model against white-box projected gradient attack (PGD) can be significantly improved from 46.8% to 64.5% with our algorithm.