 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOstrichRL: A Musculoskeletal Ostrich Simulation to Study Bio-mechanical Locomotion
Dec 11, 2021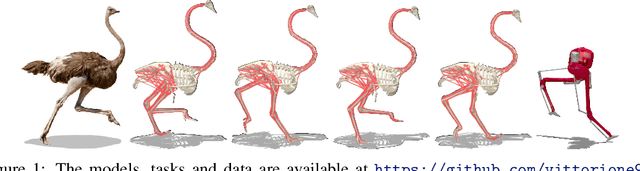
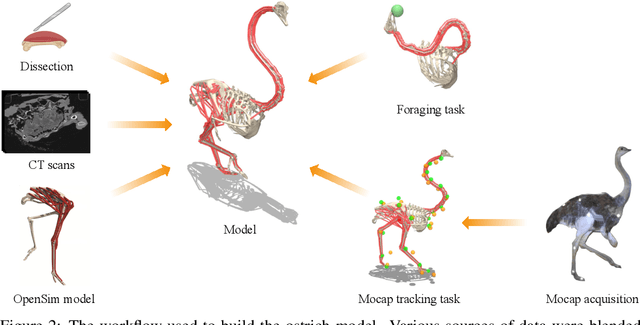
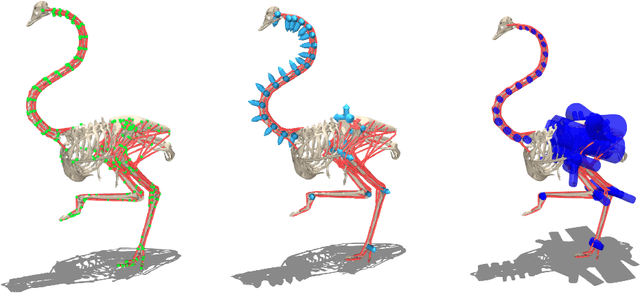
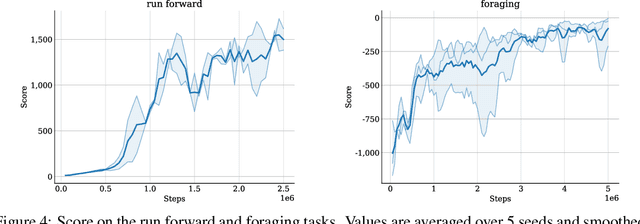
Muscle-actuated control is a research topic of interest spanning different fields, in particular biomechanics, robotics and graphics. This type of control is particularly challenging because models are often overactuated, and dynamics are delayed and non-linear. It is however a very well tested and tuned actuation model that has undergone millions of years of evolution and that involves interesting properties exploiting passive forces of muscle-tendon units and efficient energy storage and release. To facilitate research on muscle-actuated simulation, we release a 3D musculoskeletal simulation of an ostrich based on the MuJoCo simulator. Ostriches are one of the fastest bipeds on earth and are therefore an excellent model for studying muscle-actuated bipedal locomotion. The model is based on CT scans and dissections used to gather actual muscle data such as insertion sites, lengths and pennation angles. Along with this model, we also provide a set of reinforcement learning tasks, including reference motion tracking and a reaching task with the neck. The reference motion data are based on motion capture clips of various behaviors which we pre-processed and adapted to our model. This paper describes how the model was built and iteratively improved using the tasks. We evaluate the accuracy of the muscle actuation patterns by comparing them to experimentally collected electromyographic data from locomoting birds. We believe that this work can be a useful bridge between the biomechanics, reinforcement learning, graphics and robotics communities, by providing a fast and easy to use simulation.
Evaluating model-based planning and planner amortization for continuous control
Oct 07, 2021
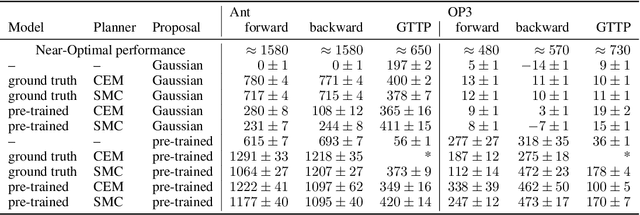
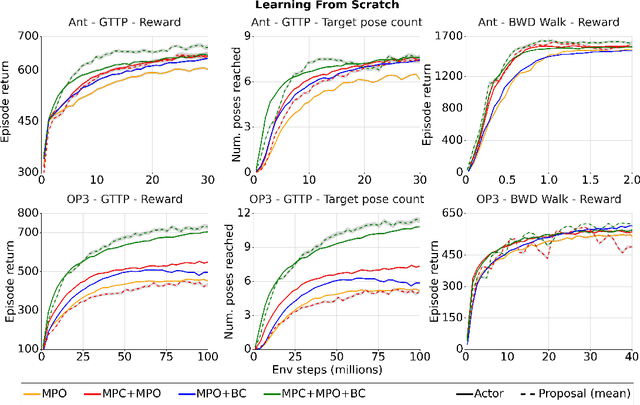
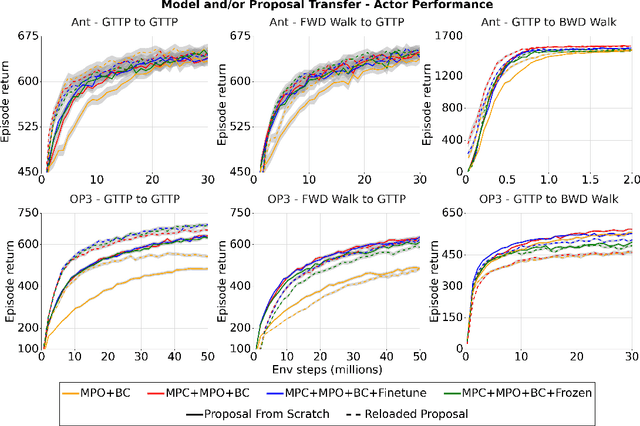
There is a widespread intuition that model-based control methods should be able to surpass the data efficiency of model-free approaches. In this paper we attempt to evaluate this intuition on various challenging locomotion tasks. We take a hybrid approach, combining model predictive control (MPC) with a learned model and model-free policy learning; the learned policy serves as a proposal for MPC. We find that well-tuned model-free agents are strong baselines even for high DoF control problems but MPC with learned proposals and models (trained on the fly or transferred from related tasks) can significantly improve performance and data efficiency in hard multi-task/multi-goal settings. Finally, we show that it is possible to distil a model-based planner into a policy that amortizes the planning computation without any loss of performance. Videos of agents performing different tasks can be seen at https://sites.google.com/view/mbrl-amortization/home.
Learning Dynamics Models for Model Predictive Agents
Sep 29, 2021
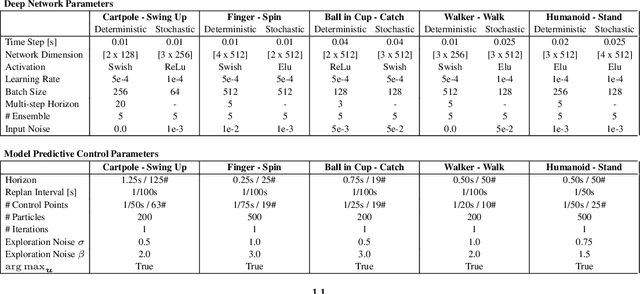
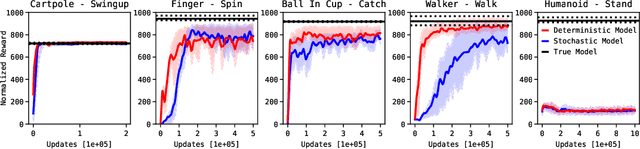
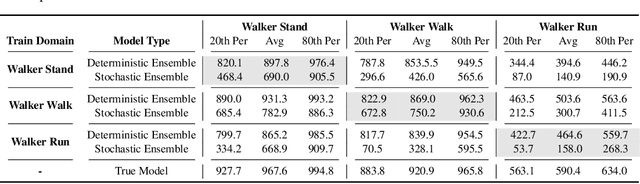
Model-Based Reinforcement Learning involves learning a \textit{dynamics model} from data, and then using this model to optimise behaviour, most often with an online \textit{planner}. Much of the recent research along these lines presents a particular set of design choices, involving problem definition, model learning and planning. Given the multiple contributions, it is difficult to evaluate the effects of each. This paper sets out to disambiguate the role of different design choices for learning dynamics models, by comparing their performance to planning with a ground-truth model -- the simulator. First, we collect a rich dataset from the training sequence of a model-free agent on 5 domains of the DeepMind Control Suite. Second, we train feed-forward dynamics models in a supervised fashion, and evaluate planner performance while varying and analysing different model design choices, including ensembling, stochasticity, multi-step training and timestep size. Besides the quantitative analysis, we describe a set of qualitative findings, rules of thumb, and future research directions for planning with learned dynamics models. Videos of the results are available at https://sites.google.com/view/learning-better-models.
From Motor Control to Team Play in Simulated Humanoid Football
May 25, 2021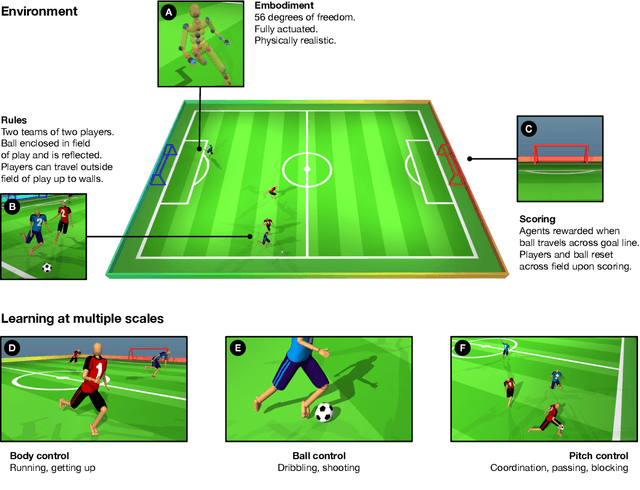

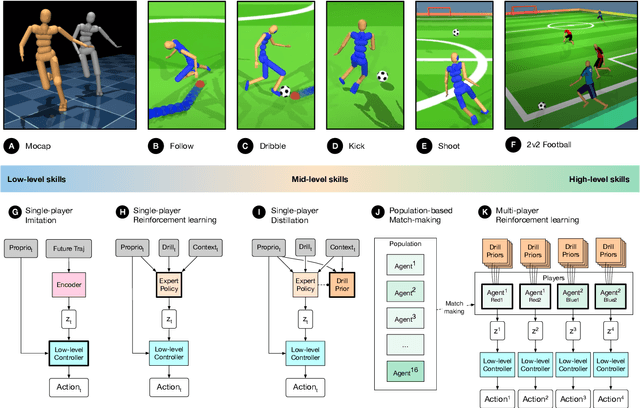

Intelligent behaviour in the physical world exhibits structure at multiple spatial and temporal scales. Although movements are ultimately executed at the level of instantaneous muscle tensions or joint torques, they must be selected to serve goals defined on much longer timescales, and in terms of relations that extend far beyond the body itself, ultimately involving coordination with other agents. Recent research in artificial intelligence has shown the promise of learning-based approaches to the respective problems of complex movement, longer-term planning and multi-agent coordination. However, there is limited research aimed at their integration. We study this problem by training teams of physically simulated humanoid avatars to play football in a realistic virtual environment. We develop a method that combines imitation learning, single- and multi-agent reinforcement learning and population-based training, and makes use of transferable representations of behaviour for decision making at different levels of abstraction. In a sequence of stages, players first learn to control a fully articulated body to perform realistic, human-like movements such as running and turning; they then acquire mid-level football skills such as dribbling and shooting; finally, they develop awareness of others and play as a team, bridging the gap between low-level motor control at a timescale of milliseconds, and coordinated goal-directed behaviour as a team at the timescale of tens of seconds. We investigate the emergence of behaviours at different levels of abstraction, as well as the representations that underlie these behaviours using several analysis techniques, including statistics from real-world sports analytics. Our work constitutes a complete demonstration of integrated decision-making at multiple scales in a physically embodied multi-agent setting. See project video at https://youtu.be/KHMwq9pv7mg.
Local Search for Policy Iteration in Continuous Control
Oct 12, 2020
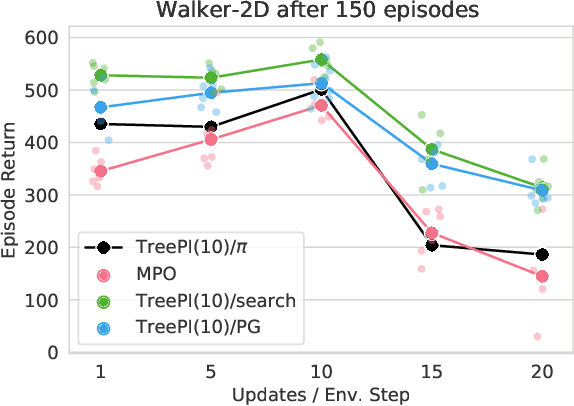

We present an algorithm for local, regularized, policy improvement in reinforcement learning (RL) that allows us to formulate model-based and model-free variants in a single framework. Our algorithm can be interpreted as a natural extension of work on KL-regularized RL and introduces a form of tree search for continuous action spaces. We demonstrate that additional computation spent on model-based policy improvement during learning can improve data efficiency, and confirm that model-based policy improvement during action selection can also be beneficial. Quantitatively, our algorithm improves data efficiency on several continuous control benchmarks (when a model is learned in parallel), and it provides significant improvements in wall-clock time in high-dimensional domains (when a ground truth model is available). The unified framework also helps us to better understand the space of model-based and model-free algorithms. In particular, we demonstrate that some benefits attributed to model-based RL can be obtained without a model, simply by utilizing more computation.
dm_control: Software and Tasks for Continuous Control
Jun 22, 2020

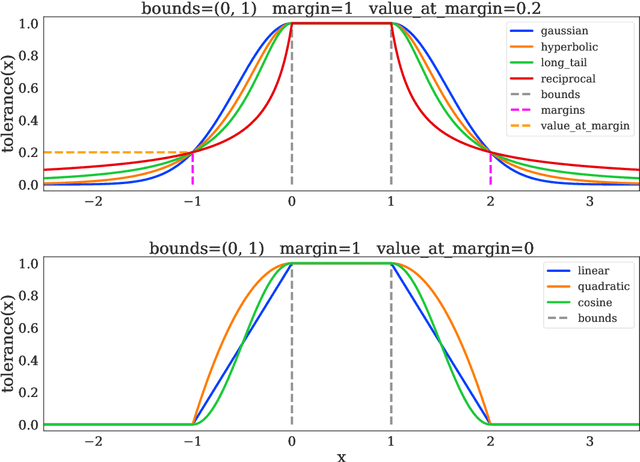
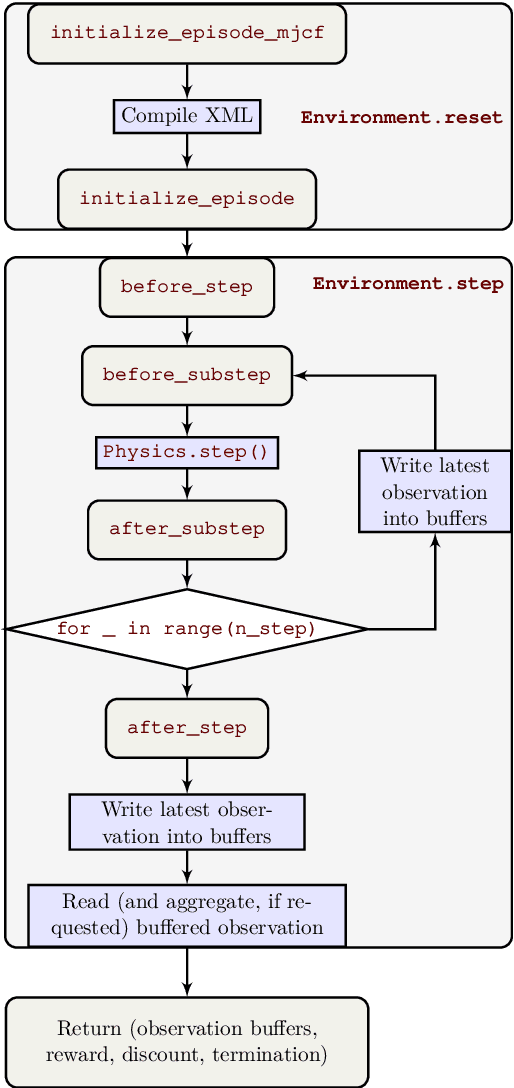
The dm_control software package is a collection of Python libraries and task suites for reinforcement learning agents in an articulated-body simulation. A MuJoCo wrapper provides convenient bindings to functions and data structures. The PyMJCF and Composer libraries enable procedural model manipulation and task authoring. The Control Suite is a fixed set of tasks with standardised structure, intended to serve as performance benchmarks. The Locomotion framework provides high-level abstractions and examples of locomotion tasks. A set of configurable manipulation tasks with a robot arm and snap-together bricks is also included. dm_control is publicly available at https://www.github.com/deepmind/dm_control
Reusable neural skill embeddings for vision-guided whole body movement and object manipulation
Nov 15, 2019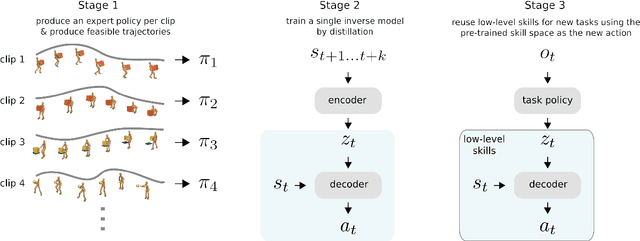
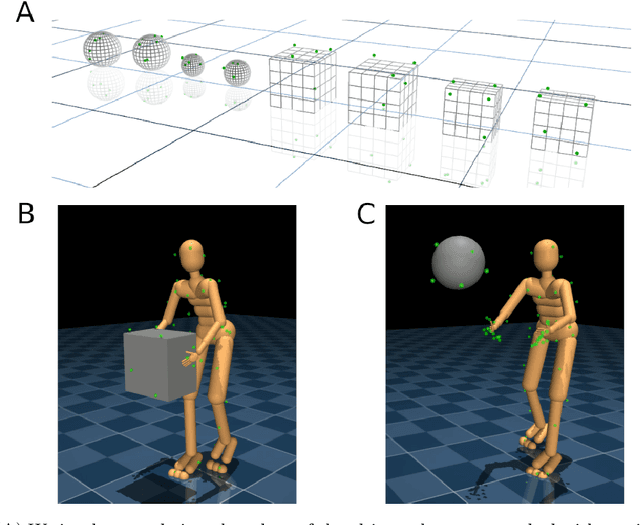
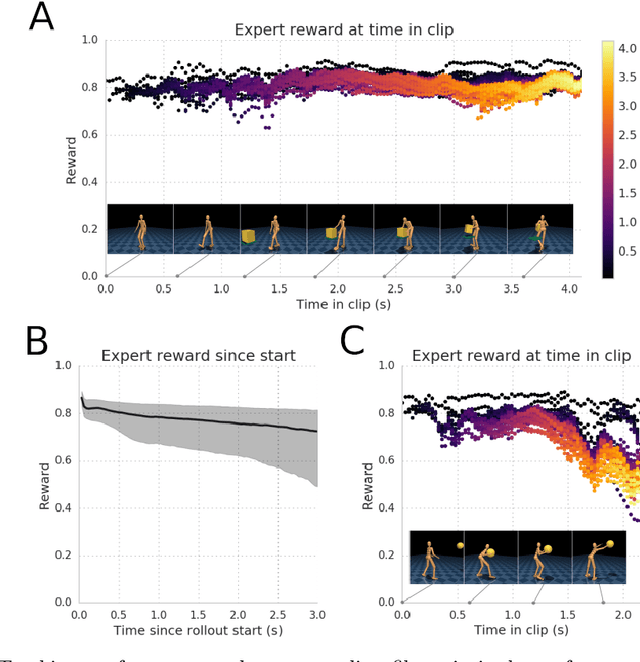
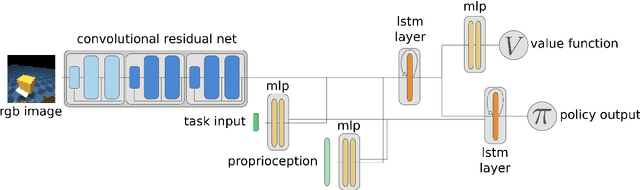
Both in simulation settings and robotics, there is an ambition to produce flexible control systems that can enable complex bodies to perform dynamic locomotion and natural object manipulation. In previous work, we developed a framework to train locomotor skills and reuse these skills for whole-body visuomotor tasks. Here, we extend this line of work to tasks involving whole body movement as well as visually guided manipulation of objects. This setting poses novel challenges in terms of task specification, exploration, and generalization. We develop an integrated approach consisting of a flexible motor primitive module, demonstrations, an instructed training regime as well as curricula in the form of task variations. We demonstrate the utility of our approach for solving challenging whole body tasks that require joint locomotion and manipulation, and characterize its behavioral robustness. We also provide a high-level overview video, see https://youtu.be/t0RDGSnE3cM .
Modelling Generalized Forces with Reinforcement Learning for Sim-to-Real Transfer
Oct 21, 2019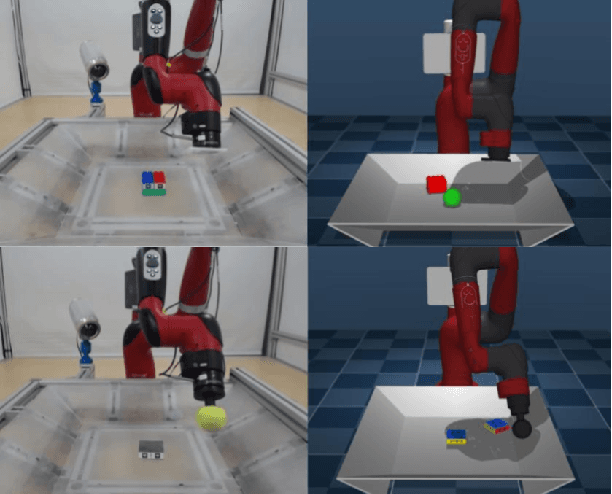
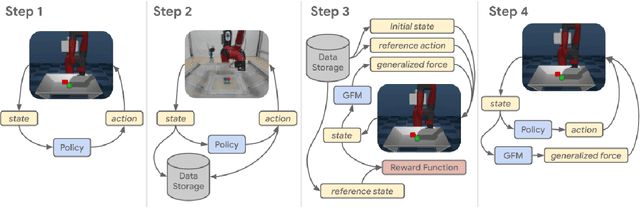
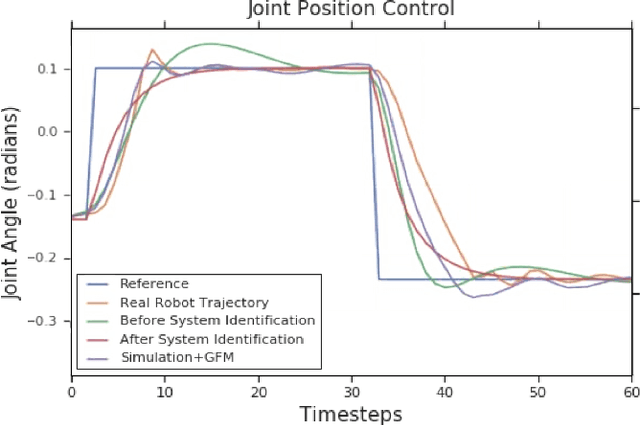

Learning robotic control policies in the real world gives rise to challenges in data efficiency, safety, and controlling the initial condition of the system. On the other hand, simulations are a useful alternative as they provide an abundant source of data without the restrictions of the real world. Unfortunately, simulations often fail to accurately model complex real-world phenomena. Traditional system identification techniques are limited in expressiveness by the analytical model parameters, and usually are not sufficient to capture such phenomena. In this paper we propose a general framework for improving the analytical model by optimizing state dependent generalized forces. State dependent generalized forces are expressive enough to model constraints in the equations of motion, while maintaining a clear physical meaning and intuition. We use reinforcement learning to efficiently optimize the mapping from states to generalized forces over a discounted infinite horizon. We show that using only minutes of real world data improves the sim-to-real control policy transfer. We demonstrate the feasibility of our approach by validating it on a nonprehensile manipulation task on the Sawyer robot.
Learning Gentle Object Manipulation with Curiosity-Driven Deep Reinforcement Learning
Mar 20, 2019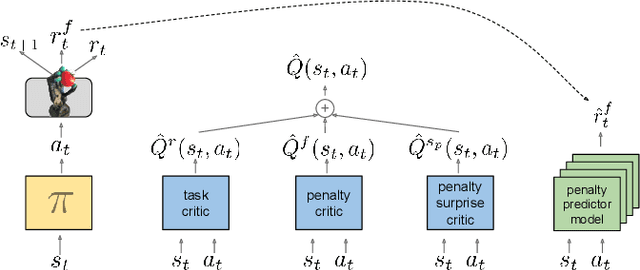

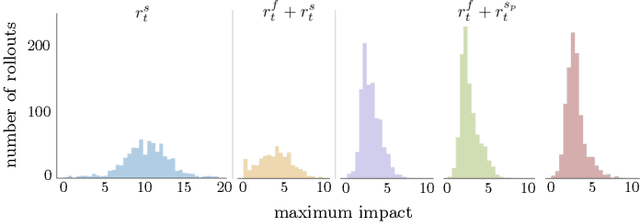
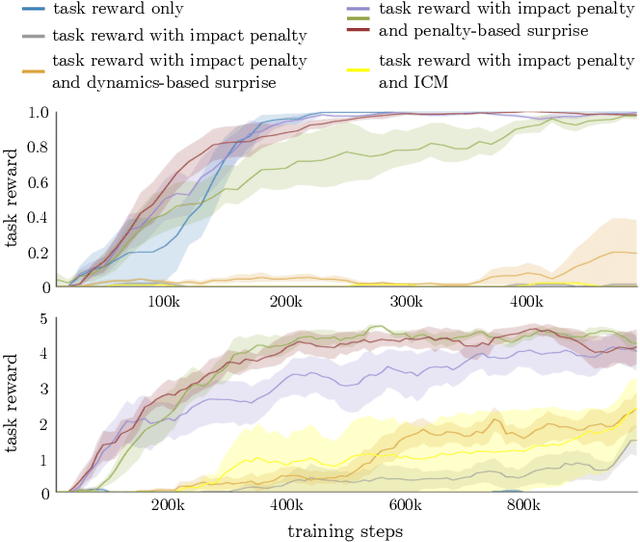
Robots must know how to be gentle when they need to interact with fragile objects, or when the robot itself is prone to wear and tear. We propose an approach that enables deep reinforcement learning to train policies that are gentle, both during exploration and task execution. In a reward-based learning environment, a natural approach involves augmenting the (task) reward with a penalty for non-gentleness, which can be defined as excessive impact force. However, augmenting with only this penalty impairs learning: policies get stuck in a local optimum which avoids all contact with the environment. Prior research has shown that combining auxiliary tasks or intrinsic rewards can be beneficial for stabilizing and accelerating learning in sparse-reward domains, and indeed we find that introducing a surprise-based intrinsic reward does avoid the no-contact failure case. However, we show that a simple dynamics-based surprise is not as effective as penalty-based surprise. Penalty-based surprise, based on predicting forceful contacts, has a further benefit: it encourages exploration which is contact-rich yet gentle. We demonstrate the effectiveness of the approach using a complex, tendon-powered robot hand with tactile sensors. Videos are available at http://sites.google.com/view/gentlemanipulation.
Relative Entropy Regularized Policy Iteration
Dec 05, 2018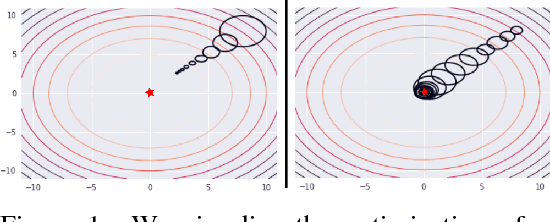
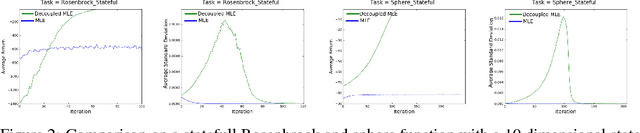

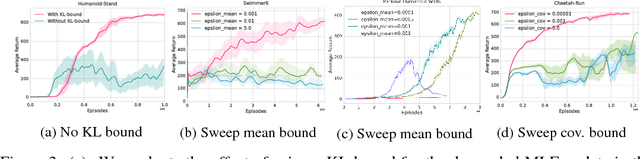
We present an off-policy actor-critic algorithm for Reinforcement Learning (RL) that combines ideas from gradient-free optimization via stochastic search with learned action-value function. The result is a simple procedure consisting of three steps: i) policy evaluation by estimating a parametric action-value function; ii) policy improvement via the estimation of a local non-parametric policy; and iii) generalization by fitting a parametric policy. Each step can be implemented in different ways, giving rise to several algorithm variants. Our algorithm draws on connections to existing literature on black-box optimization and 'RL as an inference' and it can be seen either as an extension of the Maximum a Posteriori Policy Optimisation algorithm (MPO) [Abdolmaleki et al., 2018a], or as an extension of Trust Region Covariance Matrix Adaptation Evolutionary Strategy (CMA-ES) [Abdolmaleki et al., 2017b; Hansen et al., 1997] to a policy iteration scheme. Our comparison on 31 continuous control tasks from parkour suite [Heess et al., 2017], DeepMind control suite [Tassa et al., 2018] and OpenAI Gym [Brockman et al., 2016] with diverse properties, limited amount of compute and a single set of hyperparameters, demonstrate the effectiveness of our method and the state of art results. Videos, summarizing results, can be found at goo.gl/HtvJKR .