 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwen-RobotNav Technical Report: A Scalable Navigation Model Designed for an Agentic Navigation System
Jun 18, 2026Agentic navigation systems require a base navigation model whose observation strategy can be externally reconfigured at inference time, because instruction following, object search, target tracking, and autonomous driving share the same perception-planning backbone yet demand fundamentally different strategies for consuming the visual stream. We present Qwen-RobotNav, a scalable navigation model built on Qwen-RobotNav that addresses it through a parameterised interface with two complementary dimensions: multiple task modes that select the navigation behaviour, and controllable observation parameters (e.g., token budget, per-camera weights) that govern how visual history is encoded. With training-time randomization over all parameters, Qwen-RobotNav is robust to any inference-time configuration requiring zero architectural modification to the Qwen-RobotNav backbone. We train Qwen-RobotNav on 15.6M samples; co-training with vision-language data prevents the collapse into reactive action-sequence mappers observed in trajectory-only training. The parameterised interface also makes Qwen-RobotNav a natural building block for agentic systems: for long-horizon scenarios, an upper-level planner decomposes goals into sub-tasks and dynamically switches Qwen-RobotNav's task mode and context strategy mid-episode, composing complex behaviours from repeated calls to the same model. Extensive experiments show that Qwen-RobotNav sets new state-of-the-art results across major navigation benchmarks. The model exhibits favourable scaling from 2B to 8B parameters, with joint multi-task training developing a shared spatial-planning substrate that transfers across task families, and demonstrates strong zero-shot generalisation to real-world robots across diverse environments.
Recovering Policy-Induced Errors: Benchmarking and Trajectory Synthesis for Robust GUI Agents
May 28, 2026While GUI agents have advanced rapidly, they often lack the robustness to recover from their own errors, hindering real-world deployment. To bridge this gap at both the evaluation and data levels, we introduce GUI-RobustEval and propose Robustness-driven Trajectory Synthesis. GUI-RobustEval contains $1,216$ executable test cases that systematically measure error recovery capabilities across a broad and realistic spectrum of error modes. At the data level, RoTS is a scalable synthesis framework that creates $800k$ high-quality data via a tree-based pipeline that proactively discovers diverse error modes and synthesizes corresponding recovery steps. Our two models, RoTS-7B and RoTS-32B, fine-tuned on our dataset, both demonstrate significant gains on GUI-RobustEval and traditional GUI benchmarks. Notably, RoTS-32B achieves state-of-the-art performance on OSWorld, with a $47.4\%$ success rate and a $33.8\%$ All-Pass@4 score, suggesting that improved long-horizon error recovery ability contributes to both robustness and overall performance. Our code is available at https://github.com/AlibabaResearch/RoTS.
Long Live The Balance: Information Bottleneck Driven Tree-based Policy Optimization
May 27, 2026Recent advances in online reinforcement learning (RL) for large language models (LLMs) have demonstrated promising performance in complex reasoning tasks. However, they often exhibit an imbalanced exploration-exploitation trade-off, resulting in unstable optimization and sub-optimal performance. We introduce IB-Score, a novel metric grounded in Information Bottleneck theory that evaluates policy's exploration-exploitation balance by quantifying the trade-off between step-level reasoning diversity and mutual information shared with the correct answer. Analysis based on IB-Score shows that popular online RL approaches (e.g., GRPO) with common regularizers fail to consistently maintain balance during training with suboptimal results. To address this, we propose Information Bottleneck-driven Tree-based Policy Optimization (IB-TPO), a principled framework that formulates IB-Score as a fine-grained optimization objective and utilizes a novel IB-guided tree sampling strategy that not only improves the efficiency of online sampling with 50% more trajectories under the same token budget, but also reuses the tree structure for effective IB-Score Monte Carlo estimation. Extensive experiments across standard benchmarks show that our method significantly outperforms GRPO baseline by 2.9% to 3.6% and also outperforms other state-of-the-art online RL approaches. Our code is available at https://github.com/alibaba/EfficientRL.
One Brain, Omni Modalities: Towards Unified Non-Invasive Brain Decoding with Large Language Models
Feb 25, 2026Deciphering brain function through non-invasive recordings requires synthesizing complementary high-frequency electromagnetic (EEG/MEG) and low-frequency metabolic (fMRI) signals. However, despite their shared neural origins, extreme discrepancies have traditionally confined these modalities to isolated analysis pipelines, hindering a holistic interpretation of brain activity. To bridge this fragmentation, we introduce \textbf{NOBEL}, a \textbf{n}euro-\textbf{o}mni-modal \textbf{b}rain-\textbf{e}ncoding \textbf{l}arge language model (LLM) that unifies these heterogeneous signals within the LLM's semantic embedding space. Our architecture integrates a unified encoder for EEG and MEG with a novel dual-path strategy for fMRI, aligning non-invasive brain signals and external sensory stimuli into a shared token space, then leverages an LLM as a universal backbone. Extensive evaluations demonstrate that NOBEL serves as a robust generalist across standard single-modal tasks. We also show that the synergistic fusion of electromagnetic and metabolic signals yields higher decoding accuracy than unimodal baselines, validating the complementary nature of multiple neural modalities. Furthermore, NOBEL exhibits strong capabilities in stimulus-aware decoding, effectively interpreting visual semantics from multi-subject fMRI data on the NSD and HAD datasets while uniquely leveraging direct stimulus inputs to verify causal links between sensory signals and neural responses. NOBEL thus takes a step towards unifying non-invasive brain decoding, demonstrating the promising potential of omni-modal brain understanding.
Perfect AI Mimicry and the Epistemology of Consciousness: A Solipsistic Dilemma
Oct 06, 2025Rapid advances in artificial intelligence necessitate a re-examination of the epistemological foundations upon which we attribute consciousness. As AI systems increasingly mimic human behavior and interaction with high fidelity, the concept of a "perfect mimic"-an entity empirically indistinguishable from a human through observation and interaction-shifts from hypothetical to technologically plausible. This paper argues that such developments pose a fundamental challenge to the consistency of our mind-recognition practices. Consciousness attributions rely heavily, if not exclusively, on empirical evidence derived from behavior and interaction. If a perfect mimic provides evidence identical to that of humans, any refusal to grant it equivalent epistemic status must invoke inaccessible factors, such as qualia, substrate requirements, or origin. Selectively invoking such factors risks a debilitating dilemma: either we undermine the rational basis for attributing consciousness to others (epistemological solipsism), or we accept inconsistent reasoning. I contend that epistemic consistency demands we ascribe the same status to empirically indistinguishable entities, regardless of metaphysical assumptions. The perfect mimic thus acts as an epistemic mirror, forcing critical reflection on the assumptions underlying intersubjective recognition in light of advancing AI. This analysis carries significant implications for theories of consciousness and ethical frameworks concerning artificial agents.
Training Neural Networks for Execution on Approximate Hardware
Apr 08, 2023



Approximate computing methods have shown great potential for deep learning. Due to the reduced hardware costs, these methods are especially suitable for inference tasks on battery-operated devices that are constrained by their power budget. However, approximate computing hasn't reached its full potential due to the lack of work on training methods. In this work, we discuss training methods for approximate hardware. We demonstrate how training needs to be specialized for approximate hardware, and propose methods to speed up the training process by up to 18X.
PhotoFourier: A Photonic Joint Transform Correlator-Based Neural Network Accelerator
Nov 10, 2022The last few years have seen a lot of work to address the challenge of low-latency and high-throughput convolutional neural network inference. Integrated photonics has the potential to dramatically accelerate neural networks because of its low-latency nature. Combined with the concept of Joint Transform Correlator (JTC), the computationally expensive convolution functions can be computed instantaneously (time of flight of light) with almost no cost. This 'free' convolution computation provides the theoretical basis of the proposed PhotoFourier JTC-based CNN accelerator. PhotoFourier addresses a myriad of challenges posed by on-chip photonic computing in the Fourier domain including 1D lenses and high-cost optoelectronic conversions. The proposed PhotoFourier accelerator achieves more than 28X better energy-delay product compared to state-of-art photonic neural network accelerators.
Bit-serial Weight Pools: Compression and Arbitrary Precision Execution of Neural Networks on Resource Constrained Processors
Jan 25, 2022
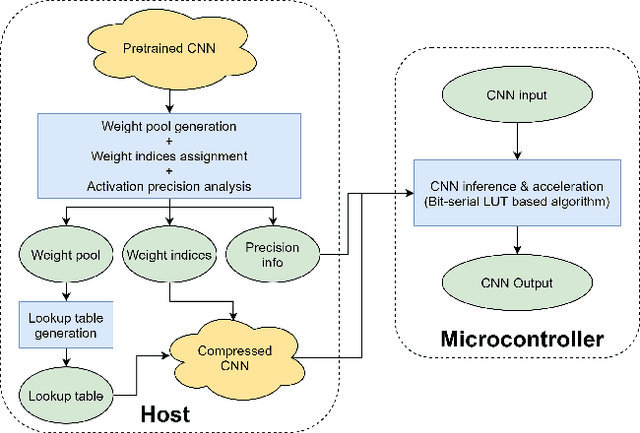
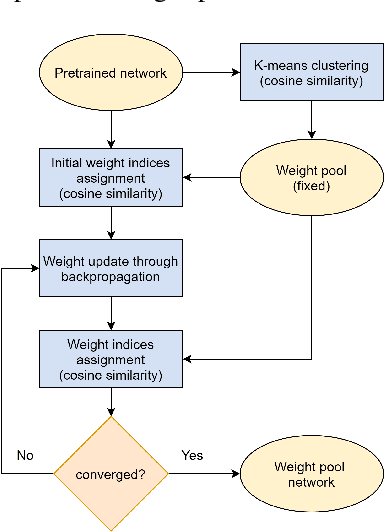

Applications of neural networks on edge systems have proliferated in recent years but the ever-increasing model size makes neural networks not able to deploy on resource-constrained microcontrollers efficiently. We propose bit-serial weight pools, an end-to-end framework that includes network compression and acceleration of arbitrary sub-byte precision. The framework can achieve up to 8x compression compared to 8-bit networks by sharing a pool of weights across the entire network. We further propose a bit-serial lookup based software implementation that allows runtime-bitwidth tradeoff and is able to achieve more than 2.8x speedup and 7.5x storage compression compared to 8-bit weight pool networks, with less than 1% accuracy drop.
Batch Processing and Data Streaming Fourier-based Convolutional Neural Network Accelerator
Dec 23, 2021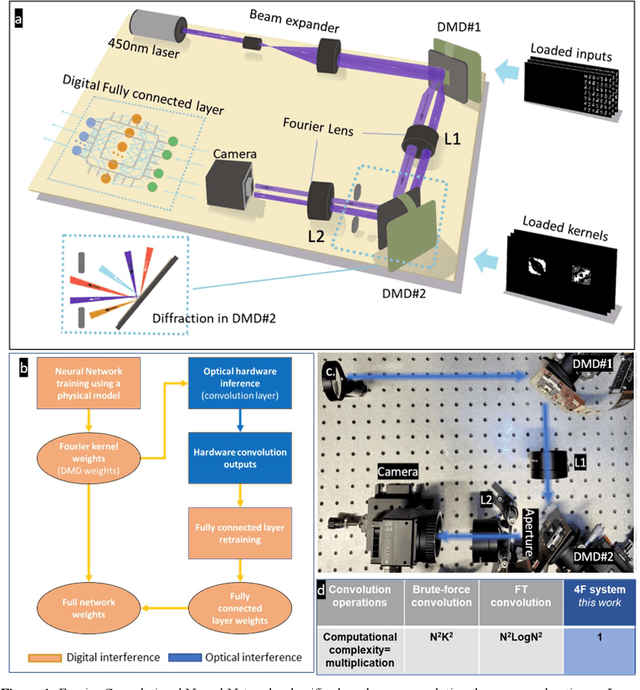

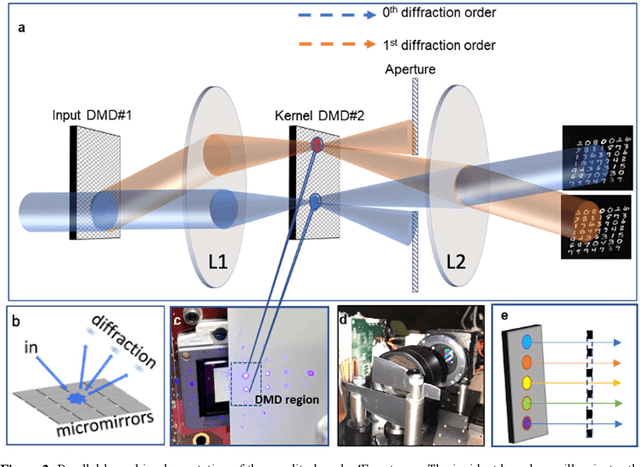
Decision-making by artificial neural networks with minimal latency is paramount for numerous applications such as navigation, tracking, and real-time machine action systems. This requires the machine learning hardware to handle multidimensional data with a high throughput. Processing convolution operations being the major computational tool for data classification tasks, unfortunately, follows a challenging run-time complexity scaling law. However, implementing the convolution theorem homomorphically in a Fourier-optic display-light-processor enables a non-iterative O(1) runtime complexity for data inputs beyond 1,000 x 1,000 large matrices. Following this approach, here we demonstrate data streaming multi-kernel image batch-processing with a Fourier Convolutional Neural Network (FCNN) accelerator. We show image batch processing of large-scale matrices as passive 2-million dot-product multiplications performed by digital light-processing modules in the Fourier domain. In addition, we parallelize this optical FCNN system further by utilizing multiple spatio-parallel diffraction orders, thus achieving a 98-times throughput improvement over state-of-art FCNN accelerators. The comprehensive discussion of the practical challenges related to working on the edge of the system's capabilities highlights issues of crosstalk in the Fourier domain and resolution scaling laws. Accelerating convolutions by utilizing the massive parallelism in display technology brings forth a non-van Neuman-based machine learning acceleration.
Revisiting the double-well problem by deep learning with a hybrid network
Apr 25, 2021
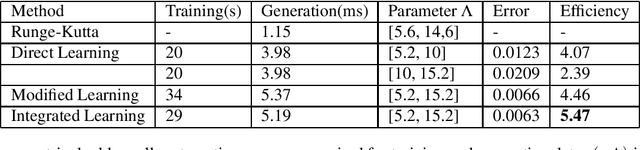
Solving physical problems by deep learning is accurate and efficient mainly accounting for the use of an elaborate neural network. We propose a novel hybrid network which integrates two different kinds of neural networks: LSTM and ResNet, in order to overcome the difficulty met in solving strongly-oscillating dynamics of the system's time evolution. By taking the double-well model as an example we show that our new method can benefit from a pre-learning and verification of the periodicity of frequency by using the LSTM network, simultaneously making a high-fidelity prediction about the whole dynamics of system with ResNet, which is impossibly achieved in the case of single network. Such a hybrid network can be applied for solving cooperative dynamics in a system with fast spatial or temporal modulations, promising for realistic oscillation calculations under experimental conditions.