 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactorized RVQ-GAN For Disentangled Speech Tokenization
Jun 18, 2025We propose Hierarchical Audio Codec (HAC), a unified neural speech codec that factorizes its bottleneck into three linguistic levels-acoustic, phonetic, and lexical-within a single model. HAC leverages two knowledge distillation objectives: one from a pre-trained speech encoder (HuBERT) for phoneme-level structure, and another from a text-based encoder (LaBSE) for lexical cues. Experiments on English and multilingual data show that HAC's factorized bottleneck yields disentangled token sets: one aligns with phonemes, while another captures word-level semantics. Quantitative evaluations confirm that HAC tokens preserve naturalness and provide interpretable linguistic information, outperforming single-level baselines in both disentanglement and reconstruction quality. These findings underscore HAC's potential as a unified discrete speech representation, bridging acoustic detail and lexical meaning for downstream speech generation and understanding tasks.
A Large-Scale Evaluation of Speech Foundation Models
Apr 15, 2024The foundation model paradigm leverages a shared foundation model to achieve state-of-the-art (SOTA) performance for various tasks, requiring minimal downstream-specific modeling and data annotation. This approach has proven crucial in the field of Natural Language Processing (NLP). However, the speech processing community lacks a similar setup to explore the paradigm systematically. In this work, we establish the Speech processing Universal PERformance Benchmark (SUPERB) to study the effectiveness of the paradigm for speech. We propose a unified multi-tasking framework to address speech processing tasks in SUPERB using a frozen foundation model followed by task-specialized, lightweight prediction heads. Combining our results with community submissions, we verify that the foundation model paradigm is promising for speech, and our multi-tasking framework is simple yet effective, as the best-performing foundation model shows competitive generalizability across most SUPERB tasks. For reproducibility and extensibility, we have developed a long-term maintained platform that enables deterministic benchmarking, allows for result sharing via an online leaderboard, and promotes collaboration through a community-driven benchmark database to support new development cycles. Finally, we conduct a series of analyses to offer an in-depth understanding of SUPERB and speech foundation models, including information flows across tasks inside the models, the correctness of the weighted-sum benchmarking protocol and the statistical significance and robustness of the benchmark.
UniX-Encoder: A Universal $X$-Channel Speech Encoder for Ad-Hoc Microphone Array Speech Processing
Oct 25, 2023



The speech field is evolving to solve more challenging scenarios, such as multi-channel recordings with multiple simultaneous talkers. Given the many types of microphone setups out there, we present the UniX-Encoder. It's a universal encoder designed for multiple tasks, and worked with any microphone array, in both solo and multi-talker environments. Our research enhances previous multi-channel speech processing efforts in four key areas: 1) Adaptability: Contrasting traditional models constrained to certain microphone array configurations, our encoder is universally compatible. 2) Multi-Task Capability: Beyond the single-task focus of previous systems, UniX-Encoder acts as a robust upstream model, adeptly extracting features for diverse tasks including ASR and speaker recognition. 3) Self-Supervised Training: The encoder is trained without requiring labeled multi-channel data. 4) End-to-End Integration: In contrast to models that first beamform then process single-channels, our encoder offers an end-to-end solution, bypassing explicit beamforming or separation. To validate its effectiveness, we tested the UniX-Encoder on a synthetic multi-channel dataset from the LibriSpeech corpus. Across tasks like speech recognition and speaker diarization, our encoder consistently outperformed combinations like the WavLM model with the BeamformIt frontend.
Self-supervised learning with bi-label masked speech prediction for streaming multi-talker speech recognition
Nov 10, 2022



Self-supervised learning (SSL), which utilizes the input data itself for representation learning, has achieved state-of-the-art results for various downstream speech tasks. However, most of the previous studies focused on offline single-talker applications, with limited investigations in multi-talker cases, especially for streaming scenarios. In this paper, we investigate SSL for streaming multi-talker speech recognition, which generates transcriptions of overlapping speakers in a streaming fashion. We first observe that conventional SSL techniques do not work well on this task due to the poor representation of overlapping speech. We then propose a novel SSL training objective, referred to as bi-label masked speech prediction, which explicitly preserves representations of all speakers in overlapping speech. We investigate various aspects of the proposed system including data configuration and quantizer selection. The proposed SSL setup achieves substantially better word error rates on the LibriSpeechMix dataset.
Adapting self-supervised models to multi-talker speech recognition using speaker embeddings
Nov 01, 2022Self-supervised learning (SSL) methods which learn representations of data without explicit supervision have gained popularity in speech-processing tasks, particularly for single-talker applications. However, these models often have degraded performance for multi-talker scenarios -- possibly due to the domain mismatch -- which severely limits their use for such applications. In this paper, we investigate the adaptation of upstream SSL models to the multi-talker automatic speech recognition (ASR) task under two conditions. First, when segmented utterances are given, we show that adding a target speaker extraction (TSE) module based on enrollment embeddings is complementary to mixture-aware pre-training. Second, for unsegmented mixtures, we propose a novel joint speaker modeling (JSM) approach, which aggregates information from all speakers in the mixture through their embeddings. With controlled experiments on Libri2Mix, we show that using speaker embeddings provides relative WER improvements of 9.1% and 42.1% over strong baselines for the segmented and unsegmented cases, respectively. We also demonstrate the effectiveness of our models for real conversational mixtures through experiments on the AMI dataset.
SUPERB @ SLT 2022: Challenge on Generalization and Efficiency of Self-Supervised Speech Representation Learning
Oct 16, 2022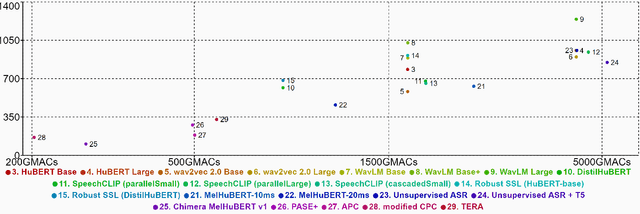
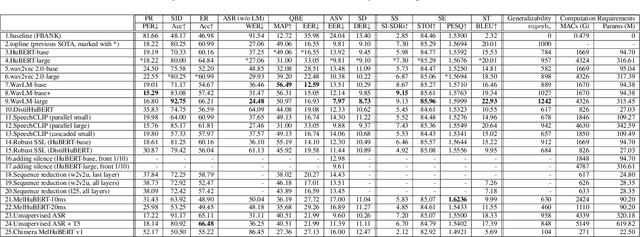
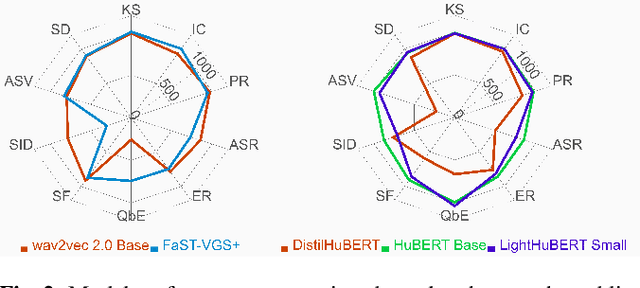
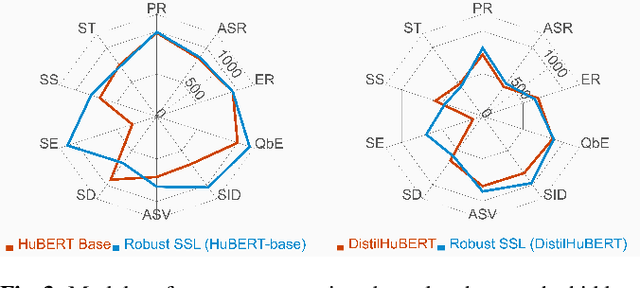
We present the SUPERB challenge at SLT 2022, which aims at learning self-supervised speech representation for better performance, generalization, and efficiency. The challenge builds upon the SUPERB benchmark and implements metrics to measure the computation requirements of self-supervised learning (SSL) representation and to evaluate its generalizability and performance across the diverse SUPERB tasks. The SUPERB benchmark provides comprehensive coverage of popular speech processing tasks, from speech and speaker recognition to audio generation and semantic understanding. As SSL has gained interest in the speech community and showed promising outcomes, we envision the challenge to uplevel the impact of SSL techniques by motivating more practical designs of techniques beyond task performance. We summarize the results of 14 submitted models in this paper. We also discuss the main findings from those submissions and the future directions of SSL research.
Investigating self-supervised learning for speech enhancement and separation
Mar 15, 2022
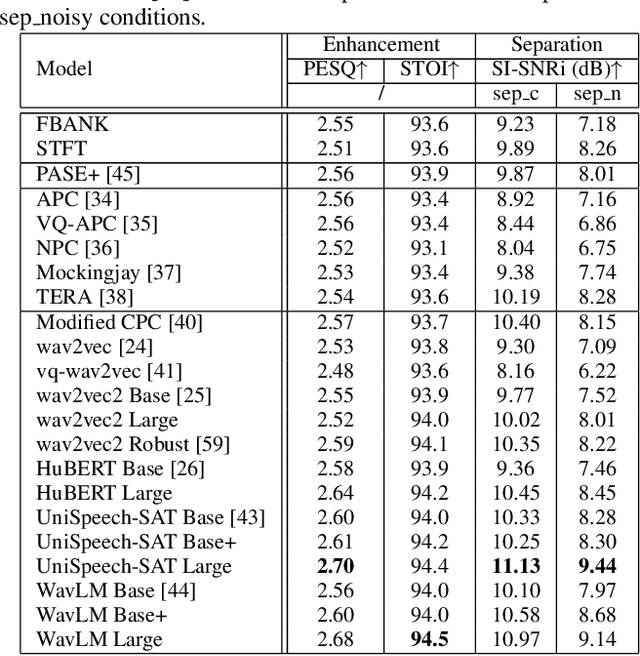
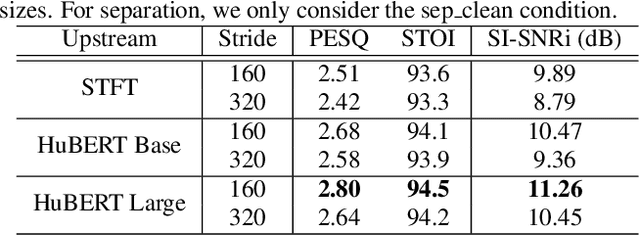
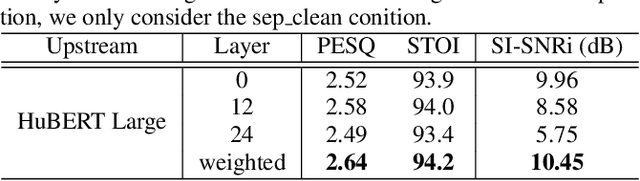
Speech enhancement and separation are two fundamental tasks for robust speech processing. Speech enhancement suppresses background noise while speech separation extracts target speech from interfering speakers. Despite a great number of supervised learning-based enhancement and separation methods having been proposed and achieving good performance, studies on applying self-supervised learning (SSL) to enhancement and separation are limited. In this paper, we evaluate 13 SSL upstream methods on speech enhancement and separation downstream tasks. Our experimental results on Voicebank-DEMAND and Libri2Mix show that some SSL representations consistently outperform baseline features including the short-time Fourier transform (STFT) magnitude and log Mel filterbank (FBANK). Furthermore, we analyze the factors that make existing SSL frameworks difficult to apply to speech enhancement and separation and discuss the representation properties desired for both tasks. Our study is included as the official speech enhancement and separation downstreams for SUPERB.
SUPERB-SG: Enhanced Speech processing Universal PERformance Benchmark for Semantic and Generative Capabilities
Mar 14, 2022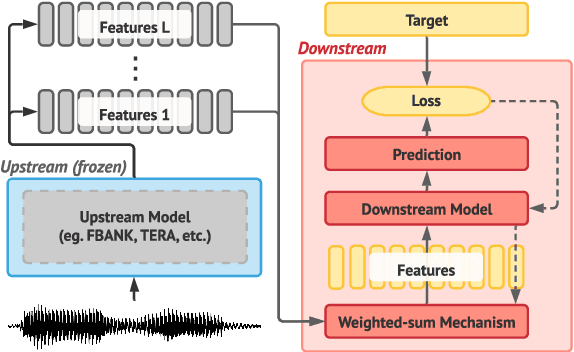
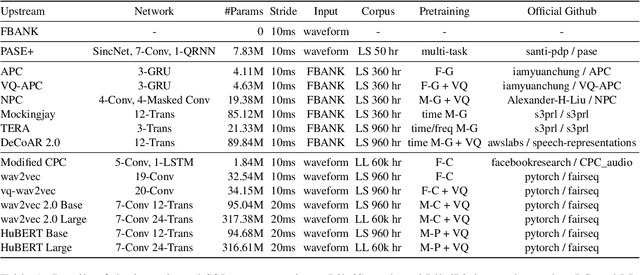
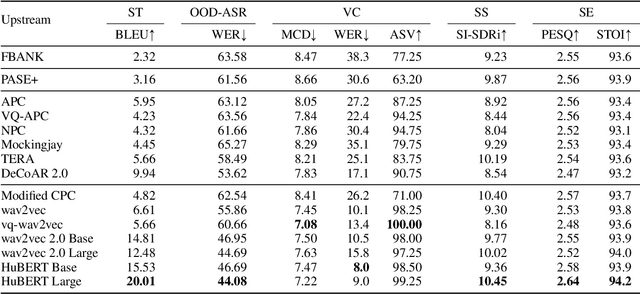
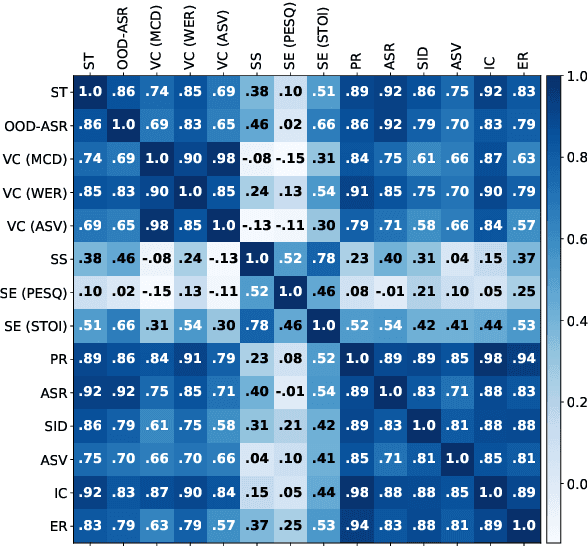
Transfer learning has proven to be crucial in advancing the state of speech and natural language processing research in recent years. In speech, a model pre-trained by self-supervised learning transfers remarkably well on multiple tasks. However, the lack of a consistent evaluation methodology is limiting towards a holistic understanding of the efficacy of such models. SUPERB was a step towards introducing a common benchmark to evaluate pre-trained models across various speech tasks. In this paper, we introduce SUPERB-SG, a new benchmark focused on evaluating the semantic and generative capabilities of pre-trained models by increasing task diversity and difficulty over SUPERB. We use a lightweight methodology to test the robustness of representations learned by pre-trained models under shifts in data domain and quality across different types of tasks. It entails freezing pre-trained model parameters, only using simple task-specific trainable heads. The goal is to be inclusive of all researchers, and encourage efficient use of computational resources. We also show that the task diversity of SUPERB-SG coupled with limited task supervision is an effective recipe for evaluating the generalizability of model representation.
Target-speaker Voice Activity Detection with Improved I-Vector Estimation for Unknown Number of Speaker
Aug 07, 2021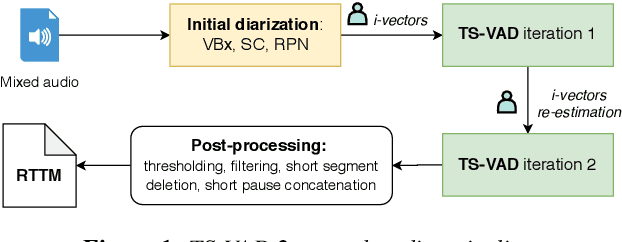
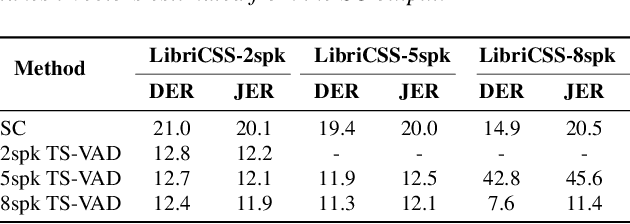
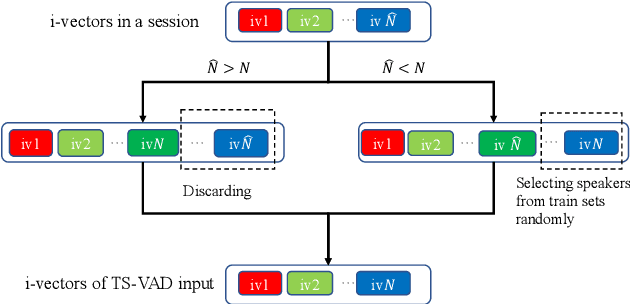
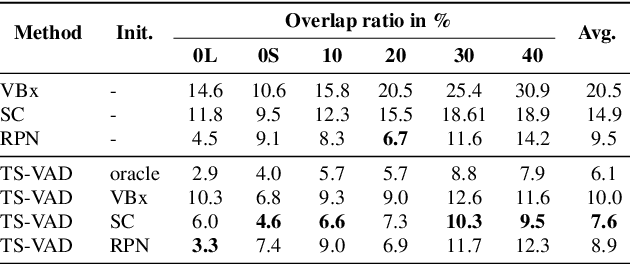
Target-speaker voice activity detection (TS-VAD) has recently shown promising results for speaker diarization on highly overlapped speech. However, the original model requires a fixed (and known) number of speakers, which limits its application to real conversations. In this paper, we extend TS-VAD to speaker diarization with unknown numbers of speakers. This is achieved by two steps: first, an initial diarization system is applied for speaker number estimation, followed by TS-VAD network output masking according to this estimate. We further investigate different diarization methods, including clustering-based and region proposal networks, for estimating the initial i-vectors. Since these systems have complementary strengths, we propose a fusion-based method to combine frame-level decisions from the systems for an improved initialization. We demonstrate through experiments on variants of the LibriCSS meeting corpus that our proposed approach can improve the DER by up to 50\% relative across varying numbers of speakers. This improvement also results in better downstream ASR performance approaching that using oracle segments.
SUPERB: Speech processing Universal PERformance Benchmark
May 03, 2021
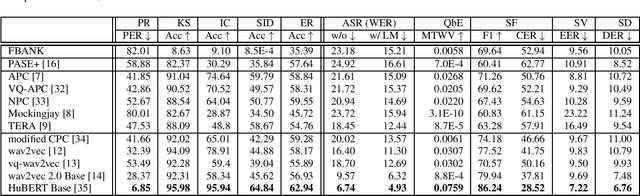
Self-supervised learning (SSL) has proven vital for advancing research in natural language processing (NLP) and computer vision (CV). The paradigm pretrains a shared model on large volumes of unlabeled data and achieves state-of-the-art (SOTA) for various tasks with minimal adaptation. However, the speech processing community lacks a similar setup to systematically explore the paradigm. To bridge this gap, we introduce Speech processing Universal PERformance Benchmark (SUPERB). SUPERB is a leaderboard to benchmark the performance of a shared model across a wide range of speech processing tasks with minimal architecture changes and labeled data. Among multiple usages of the shared model, we especially focus on extracting the representation learned from SSL due to its preferable re-usability. We present a simple framework to solve SUPERB tasks by learning task-specialized lightweight prediction heads on top of the frozen shared model. Our results demonstrate that the framework is promising as SSL representations show competitive generalizability and accessibility across SUPERB tasks. We release SUPERB as a challenge with a leaderboard and a benchmark toolkit to fuel the research in representation learning and general speech processing.