 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCALM: Joint Contextual Acoustic-Linguistic Modeling for Personalization of Multi-Speaker ASR
Jan 30, 2026We present CALM, a joint Contextual Acoustic-Linguistic Modeling framework for multi-speaker automatic speech recognition (ASR). In personalized AI scenarios, the joint availability of acoustic and linguistic cues naturally motivates the integration of target-speaker conditioning with contextual biasing in overlapping conversations. CALM implements this integration in an end-to-end framework through speaker embedding-driven target-speaker extraction and dynamic vocabulary-based contextual biasing. We evaluate CALM on simulated English (LibriSpeechMix) and Japanese (Corpus of Spontaneous Japanese mixtures, CSJMix). On two-speaker mixtures, CALM reduces biased word error rate (B-WER) from 12.7 to 4.7 on LibriSpeech2Mix and biased character error rate (B-CER) from 16.6 to 8.4 on CSJMix2 (eval3), demonstrating the effectiveness of joint acoustic-linguistic modeling across languages. We additionally report results on the AMI corpus (IHM-mix condition) to validate performance on standardized speech mixtures.
Context-Driven Dynamic Pruning for Large Speech Foundation Models
May 24, 2025



Speech foundation models achieve strong generalization across languages and acoustic conditions, but require significant computational resources for inference. In the context of speech foundation models, pruning techniques have been studied that dynamically optimize model structures based on the target audio leveraging external context. In this work, we extend this line of research and propose context-driven dynamic pruning, a technique that optimizes the model computation depending on the context between different input frames and additional context during inference. We employ the Open Whisper-style Speech Model (OWSM) and incorporate speaker embeddings, acoustic event embeddings, and language information as additional context. By incorporating the speaker embedding, our method achieves a reduction of 56.7 GFLOPs while improving BLEU scores by a relative 25.7% compared to the fully fine-tuned OWSM model.
SpeechDPR: End-to-End Spoken Passage Retrieval for Open-Domain Spoken Question Answering
Jan 24, 2024


Spoken Question Answering (SQA) is essential for machines to reply to user's question by finding the answer span within a given spoken passage. SQA has been previously achieved without ASR to avoid recognition errors and Out-of-Vocabulary (OOV) problems. However, the real-world problem of Open-domain SQA (openSQA), in which the machine needs to first retrieve passages that possibly contain the answer from a spoken archive in addition, was never considered. This paper proposes the first known end-to-end framework, Speech Dense Passage Retriever (SpeechDPR), for the retrieval component of the openSQA problem. SpeechDPR learns a sentence-level semantic representation by distilling knowledge from the cascading model of unsupervised ASR (UASR) and text dense retriever (TDR). No manually transcribed speech data is needed. Initial experiments showed performance comparable to the cascading model of UASR and TDR, and significantly better when UASR was poor, verifying this approach is more robust to speech recognition errors.
SLUE Phase-2: A Benchmark Suite of Diverse Spoken Language Understanding Tasks
Dec 20, 2022Spoken language understanding (SLU) tasks have been studied for many decades in the speech research community, but have not received as much attention as lower-level tasks like speech and speaker recognition. In particular, there are not nearly as many SLU task benchmarks, and many of the existing ones use data that is not freely available to all researchers. Recent work has begun to introduce such benchmark datasets for several tasks. In this work, we introduce several new annotated SLU benchmark tasks based on freely available speech data, which complement existing benchmarks and address gaps in the SLU evaluation landscape. We contribute four tasks: question answering and summarization involve inference over longer speech sequences; named entity localization addresses the speech-specific task of locating the targeted content in the signal; dialog act classification identifies the function of a given speech utterance. We follow the blueprint of the Spoken Language Understanding Evaluation (SLUE) benchmark suite. In order to facilitate the development of SLU models that leverage the success of pre-trained speech representations, we will be publishing for each task (i) annotations for a relatively small fine-tuning set, (ii) annotated development and test sets, and (iii) baseline models for easy reproducibility and comparisons. In this work, we present the details of data collection and annotation and the performance of the baseline models. We also perform sensitivity analysis of pipeline models' performance (speech recognizer + text model) to the speech recognition accuracy, using more than 20 state-of-the-art speech recognition models.
Meta-TTS: Meta-Learning for Few-Shot Speaker Adaptive Text-to-Speech
Nov 07, 2021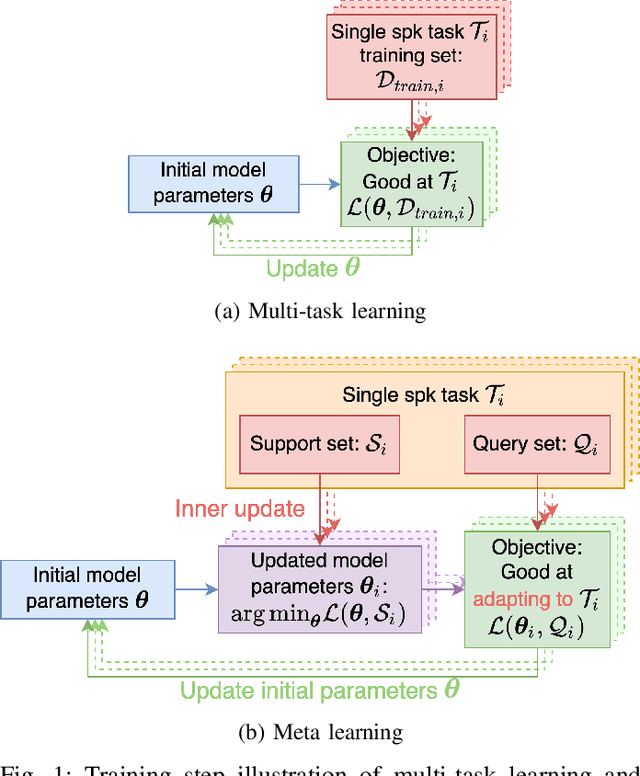
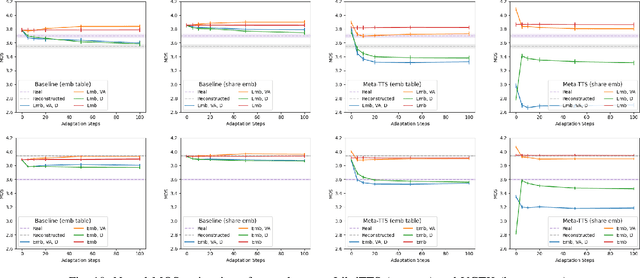
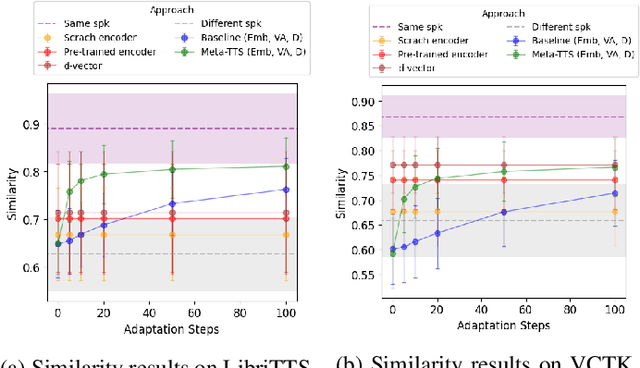
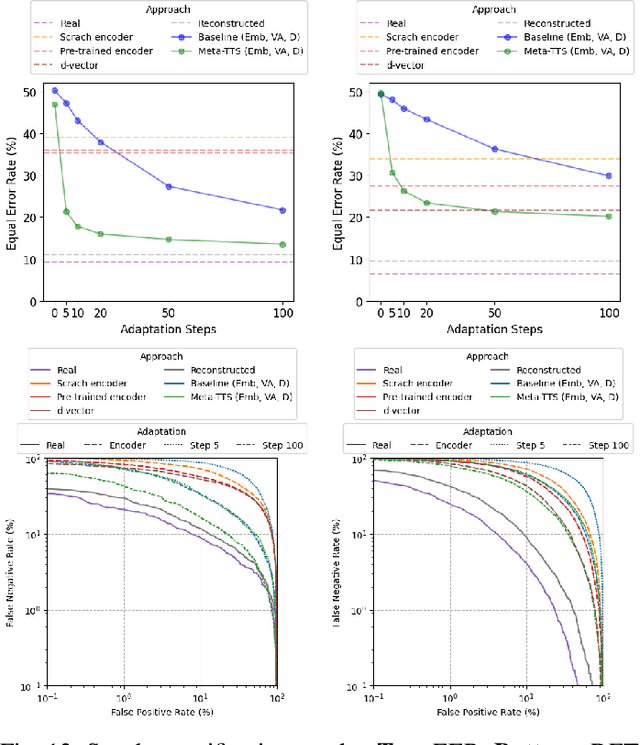
Personalizing a speech synthesis system is a highly desired application, where the system can generate speech with the user's voice with rare enrolled recordings. There are two main approaches to build such a system in recent works: speaker adaptation and speaker encoding. On the one hand, speaker adaptation methods fine-tune a trained multi-speaker text-to-speech (TTS) model with few enrolled samples. However, they require at least thousands of fine-tuning steps for high-quality adaptation, making it hard to apply on devices. On the other hand, speaker encoding methods encode enrollment utterances into a speaker embedding. The trained TTS model can synthesize the user's speech conditioned on the corresponding speaker embedding. Nevertheless, the speaker encoder suffers from the generalization gap between the seen and unseen speakers. In this paper, we propose applying a meta-learning algorithm to the speaker adaptation method. More specifically, we use Model Agnostic Meta-Learning (MAML) as the training algorithm of a multi-speaker TTS model, which aims to find a great meta-initialization to adapt the model to any few-shot speaker adaptation tasks quickly. Therefore, we can also adapt the meta-trained TTS model to unseen speakers efficiently. Our experiments compare the proposed method (Meta-TTS) with two baselines: a speaker adaptation method baseline and a speaker encoding method baseline. The evaluation results show that Meta-TTS can synthesize high speaker-similarity speech from few enrollment samples with fewer adaptation steps than the speaker adaptation baseline and outperforms the speaker encoding baseline under the same training scheme. When the speaker encoder of the baseline is pre-trained with extra 8371 speakers of data, Meta-TTS can still outperform the baseline on LibriTTS dataset and achieve comparable results on VCTK dataset.